2022. 3. 24. 16:43ㆍ프로젝트/KFood
드디어 우리 nochilsu 팀의 kfood 프로젝트가 마무리가 되었다. 최종 발표 전에 정한 프로젝트 명은 'HelloKfood'로 결정되었고, 로고도 다음과 같이 수현님께서 제작해주셨다.

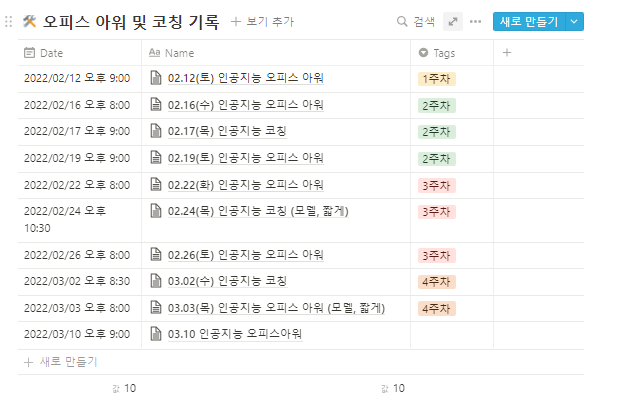
일정
일단 우리 AI 파트에서 진행한 일정은 다음과 같다. 22.02.15 ~ 22.03.10
나머지 03.12 까지는 백엔드,프론트엔드 분들께서 배포 및 서비스 오류 수정 마무리 단계를 진행해주셨다.

기능 구현
우리 AI파트가 해야할 것은 다음 3가지이다.
1. 데이터셋 구성
2. 음식탐지 모델 training 및 tuning
3. 음식선호도에 따른 음식 추천
1. 데이터셋 구성
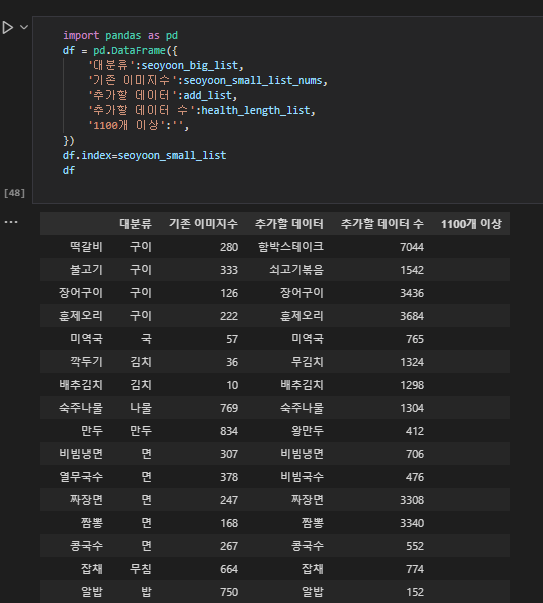
우리가 이번에 사용한 데이터셋은 모두 2개로, 한국인들이 즐겨먹는 음식에 대한 image와 bounding box에 대한 정보가 들어있는 데이터셋 2개를 사용하였다. 이 두 데이터셋을 적절히 정제하고 합쳐서 최종으로 82개의 class가 있는 한식 이미지 데이터셋을 구성하였다.
#1 건강관리를 위한 음식이미지 데이터셋
https://aihub.or.kr/aidata/27674
건강관리를 위한 음식 이미지
당뇨병 환자의 식단 관리를 위한 주재료 및 칼로리 정보가 포함된 음식 이미지 데이터
aihub.or.kr

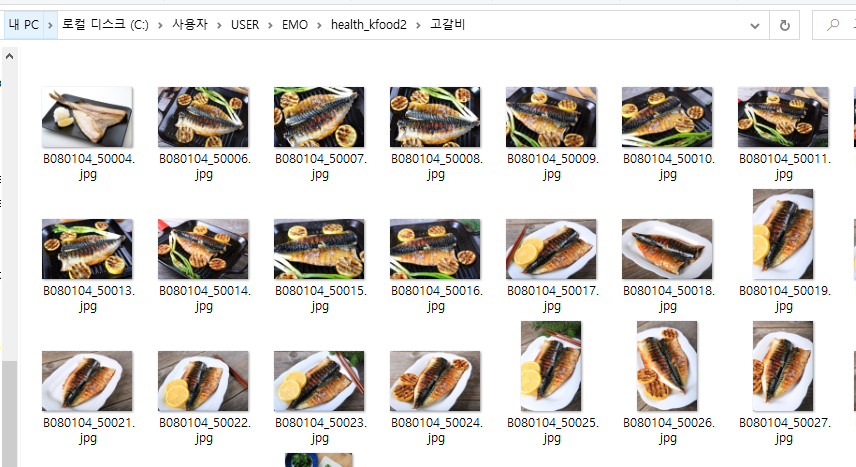
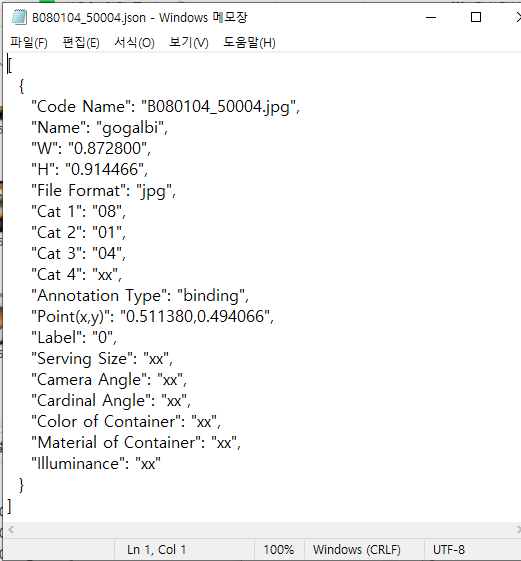
#2 한국이미지(음식) 데이터셋
https://aihub.or.kr/aidata/13594
한국 이미지(음식)
한국 음식 150종(종별 약 1천 장)의 데이터를 구축한 이미지 데이터 제공
aihub.or.kr


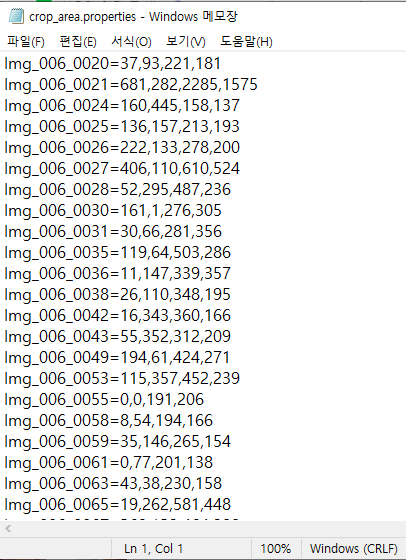
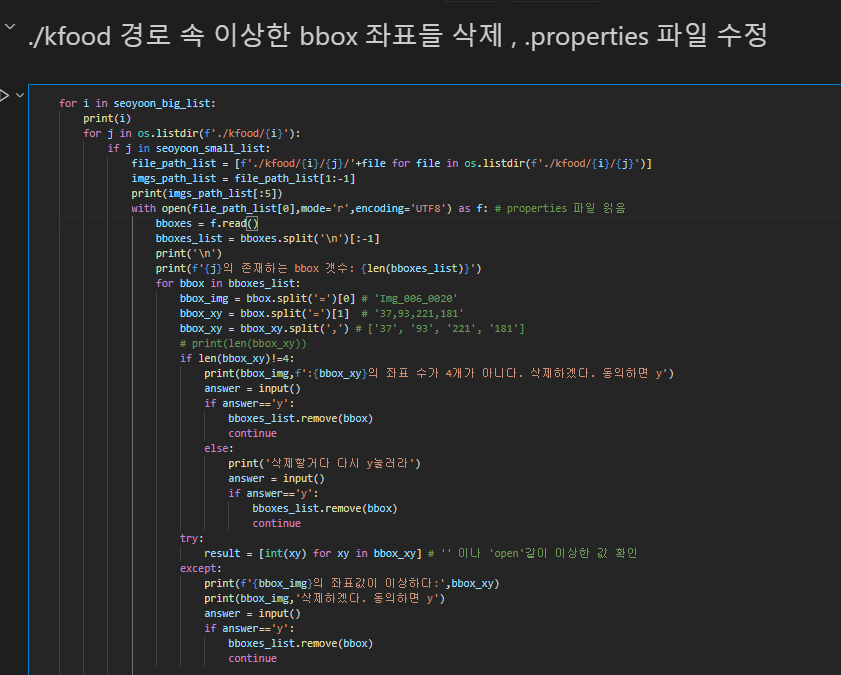
이렇게 두 데이터셋을 합칠 때 좌표값이 이상한 것도 있고, 건강관리의 경우는 image갯수 = bounding box anntation이 존재하는 image 갯수가 동일하여 정제가 필요없었지만, 한국이미지(음식)의 경우는 bounding box annotation이 결측된 경우가 있었다.
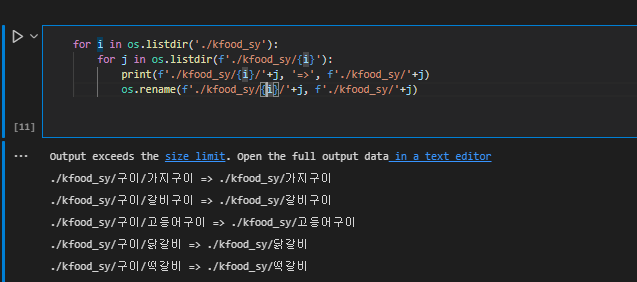
이를 자세히 알아보기 위해 가장 먼저 데이터를 합치기 전에 한국 이미지(음식) 데이터에 대해 랜덤으로 데이터를 뜯어보는 작업과, 이상한 데이터들은 삭제하는 작업을 거쳤다.
데이터 전처리에 사용된 파일들은 이 파일들의 코드를 참고하면 된다.


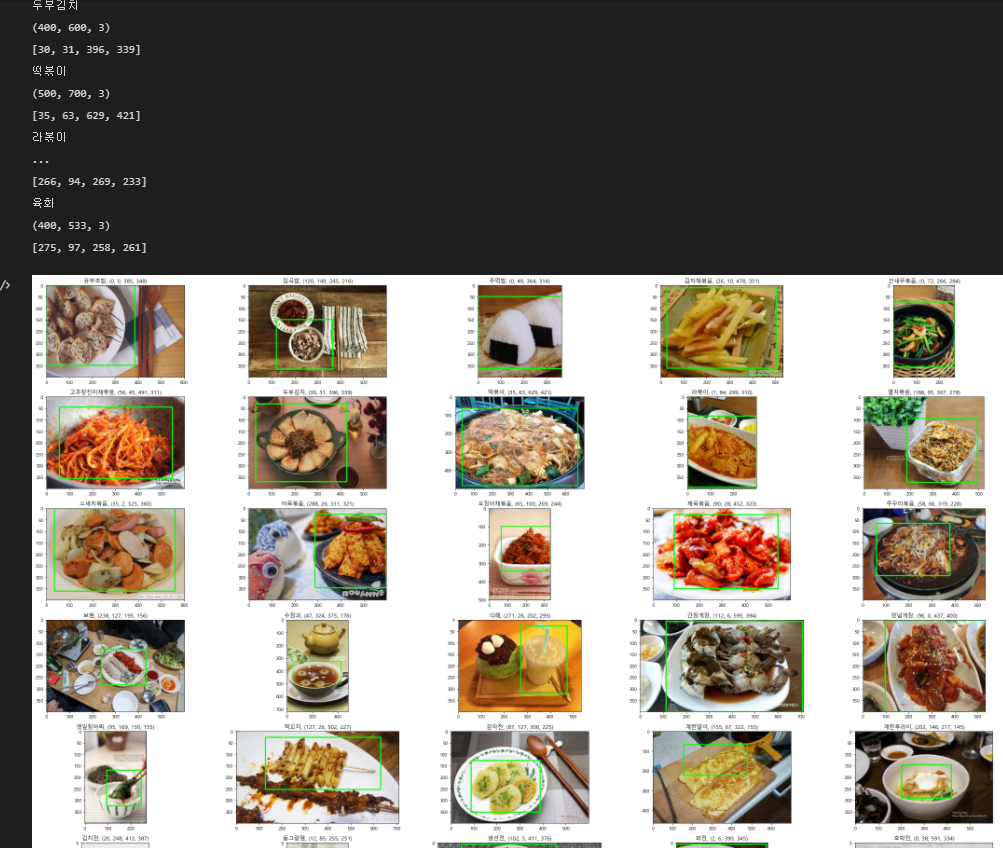
다음과 같이 한국 이미지(음식) 데이터의 image 갯수는 대부분 800~1000개인 반면 bbox 갯수는 100개~1000개로 천차만별이고, 많이 결측된 상황이어서 bbox가 900개 이상인 class만 남기기고 정제하기로 하였다.
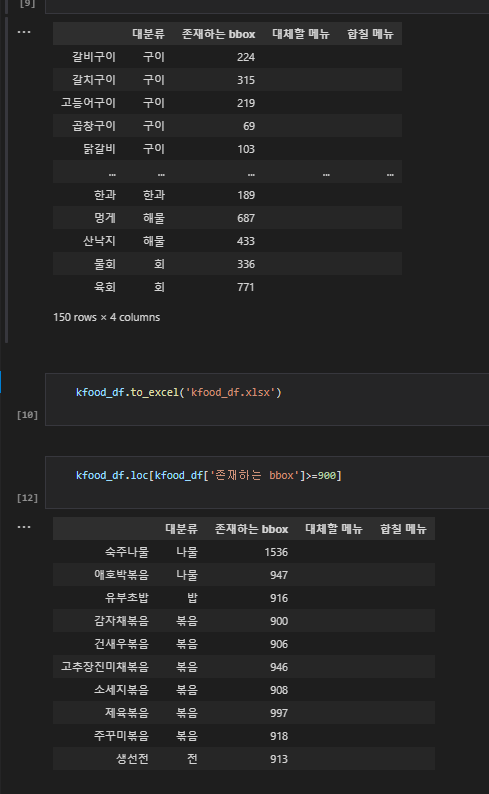
그 다음, 아래와 같은 step1~5를 거쳐서 데이터셋을 정제, 구성하였다.



이렇게 한국 이미지(음식)과 건강관리 이미지를 합쳐 총 81개의 class를 가진 데이터셋을 커스터마이징하였고,
이제 두 가지 작업을 실행해야 한다.
1. make_labels.ipynb - 데이터셋의 bbox에 대한 label을 우리가 사용할 모델이 원하는 input 형식인 yolo format에 맞게 만든다.
2. makes_yaml_and_split.ipynb - train:test:val = 8:1:1로 만들어주어야 한다.
#1 make_labels
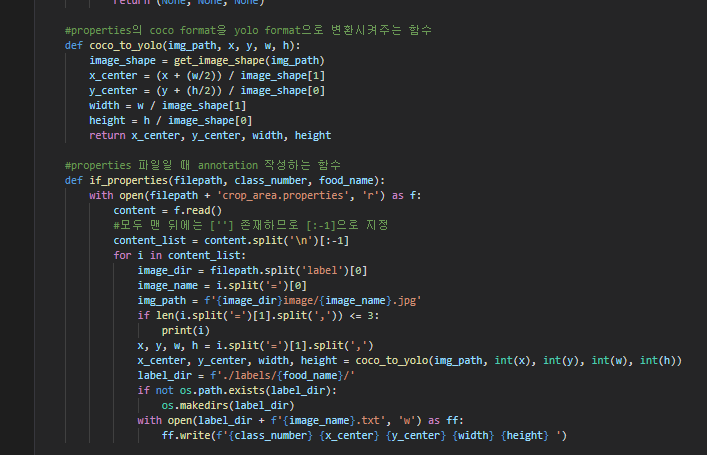
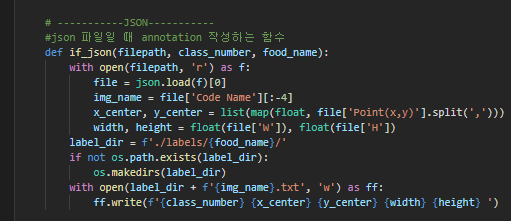


아래는 yolo format으로 통일된 bbox annotation의 모습이다. 각각 공백을 기준으로
class숫자(0~81) x_center y_center width height 이다.
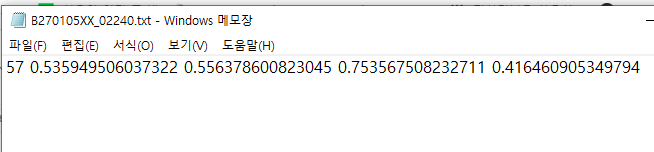

#2 makes_yaml_and_split
scikitlearn의 train_test_split함수를 import하여 사용했다.

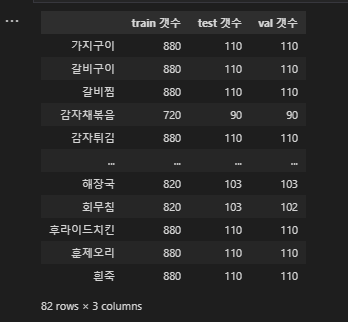

이와 같이 8:1:1로 82개의 음식 종류에 대해 split 또한 완료하였다.
이로써 길었던 데이터 전처리 및 데이터셋 구성 과정을 마쳤다.
이렇게 정제한 우리의 커스텀 데이터셋은 구글드라이브에 공유해놓겠다. 아래에서 다운받을 수 있다.
여기에 구글드라이브넣기
2. 음식탐지 모델 training 및 tuning
우리는 음식을 그저 classification 할 뿐 아니라 각 음식의 위치까지도 잡아내고자 하므로

detection 모델을 사용하기로 결정했고, 빠른 속도와 비교적 높은 정확도, 친절한 튜토리얼을 가진 YOLO 모델을 채택하였다.
https://github.com/ultralytics/yolov5
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
처음에는 yolov3를 사용하였다가, training을 진행하면서 그리고 wandb를 통해 성능을 분석하고 더 나은 inference를 만들기 위해 조금은 더 무겁고 느리지만 정확도가 높은 yolov5x6으로 진행하게 되었다.
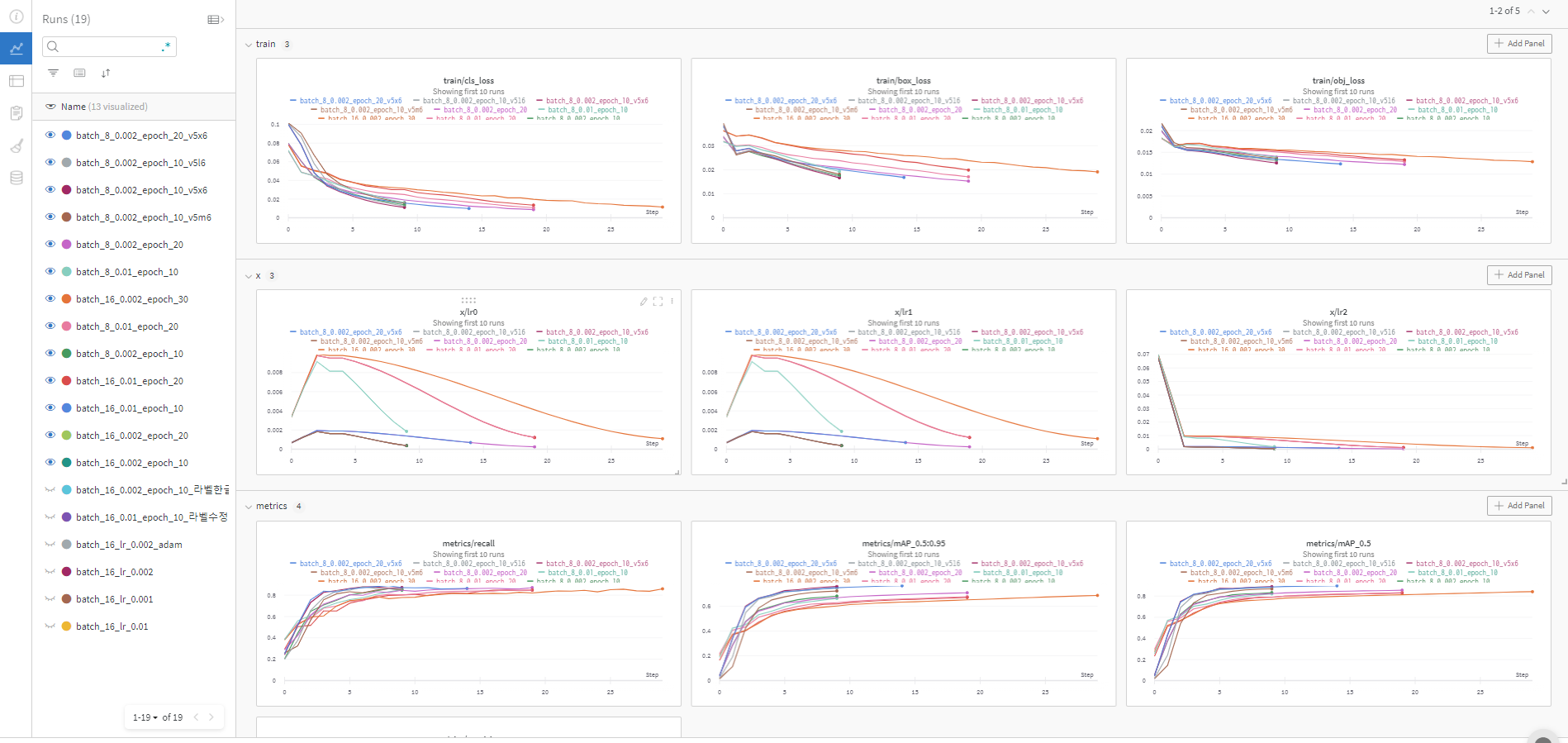

자세한 과정은 모델 학습에 대해 다룬 포스팅에 나와있다.
최종적으로 선정한 하이퍼파라미터는 batch size 16, lr 0.004, epoch 50(early stop 23) 이다.
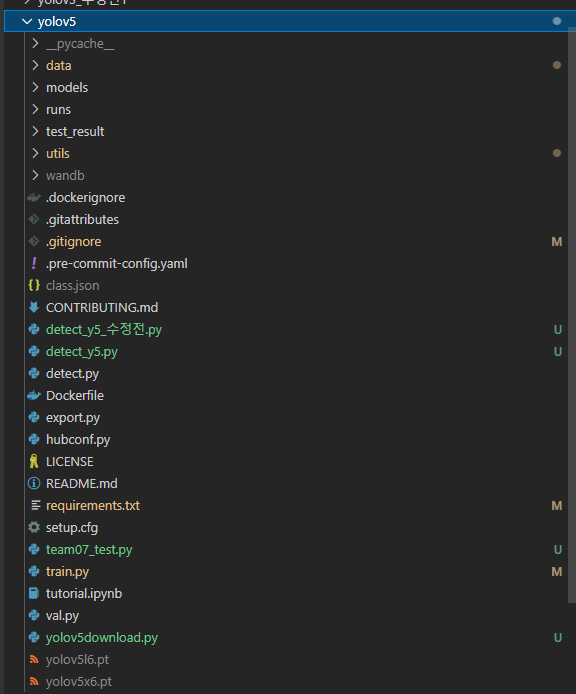
이와 같이 AI 모델에 대한 파일을 구성해놓았고, 우리의 프로젝트를 위해 input, output을 좀 손 보았다.
input으로는 base64로 디코딩된 이미지를 받으면 output으로 음식 detect가 완료된 bbox가 쳐진 image & bbox좌표 & class_list(detect된 음식들의 메뉴 Romanized 이름들)을 낸다.
따라서 기존 원작자의 GitHub의 detect.py 파일을 조금 다르게 수정하여 detect_y5.py로 변경하였다.
그리고 백엔드 파트가 파이썬 파일 하나를 함수처럼 불러오면 바로 사용할 수 있게끔 shell에서 실행하는 것이 아니라 team07_test.py 하나만 실행해도 inference가 진행될 수 있도록 수정해주었다.
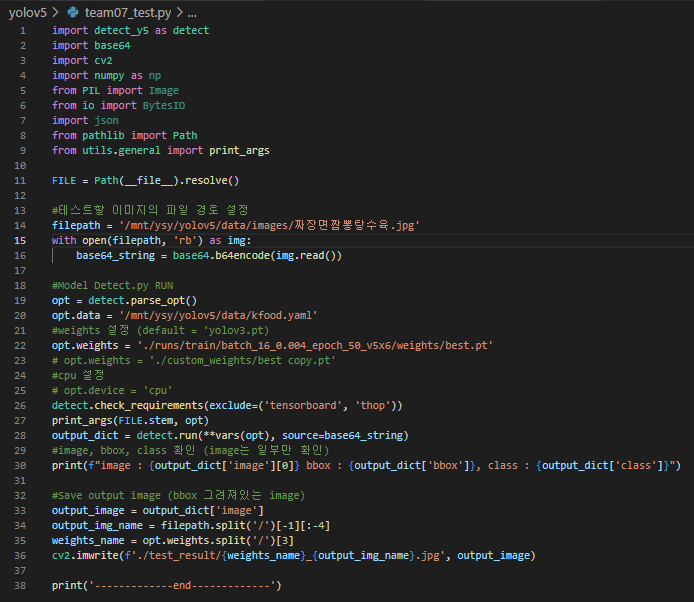
그리고 inference(detect)하기 위해서 아래의 class.json파일이 필요하고(0~81의 class를 구별)
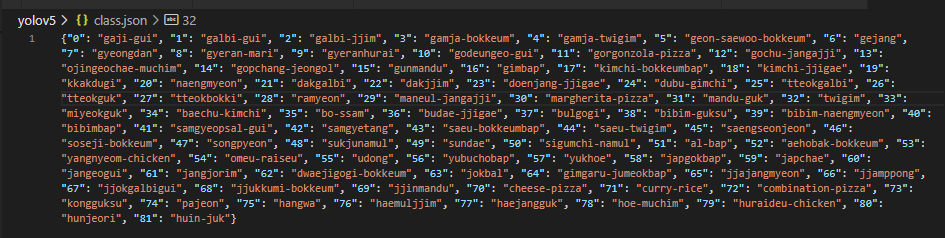
training하기 위해서 아래의 kfood.yaml 파일이 필요하다. (필수는 아닌데 YOLO 모델 training시 필요한 data에 관련된 정보들을 따로 빼서 저장해놓는 듯 하다.)
자세한 것은 yolov5 폴더 내 코드들을 참고하면 된다.
이로써 모델 학습 및 파라미터 tuning, 서비스를 위한 수정을 완료하였다.
3. 음식선호도에 따른 음식 추천
우리의 82가지의 메뉴들을 외국인들에게 소개해주는 서비스이다보니, 이것들에 대한 정보를 백엔드 DB에 넣어놓았다.
KFood음식 82종 수작업_final.csv 파일을 참고하면 된다.

우리는 구글 스프레드시트 공유를 통해 82개에 대한 정보들을 직접 모으고 정리하였다.
column으로는 korean_name , romanized_name, english_name, category, made_with, img_link, info, recipe_link, 그리고 맛에 대한 우리 팀원이 설문한 지표로 spicy, sour, salty, oily가 있다.

여기에서 외국인들이 음식 사진을 입력하면, 그 음식사진에서 탐지된 음식 메뉴에 대한 위 정보들을 DB에서 꺼내어 알려주고, 외국인들이 먹어보지 못한 그 음식에 대해 입맛에 맞을지 안 맞을지 짠맛,신맛,매운맛,기름진맛에 대한 설문을 진행하여

perfect/great/good/bad/not recommend 중 하나로 detect된 음식이 그 외국인과 얼마나 적합할지 그 결과를 알려주고, 외국인의 입맛과 잘 맞는 음식들 또한 전해주는 기능을 구현하였다.
여기서 우리는 다음과 같은 두 가지 작업을 진행하였다.
1. 입맛에 맞을 지 결과 알려주기 - 거리 계산

각 맛에 대한 차의 제곱을 합하여 ((3-2)^2 + (3-1)^2 + (3-5)^2 + (4-1)^2 = 18) 거리를 구해서 거리의 값을 5단계로 나눠서 각 level에 속하는 만큼 입맛에 적합할 것이라고 유저에게 알려주는 식으로 계산한다.
0~12 : perfect
13~25 : great
26~38 : good
39~51 : not recommend
52~64 : bad
이 작업에 대한 수식은 간단하기에 백엔드 상의 코드에서 진행된다.
2. 입맛에 잘 맞을 것 같은 음식 추천해주기 - 코사인유사도
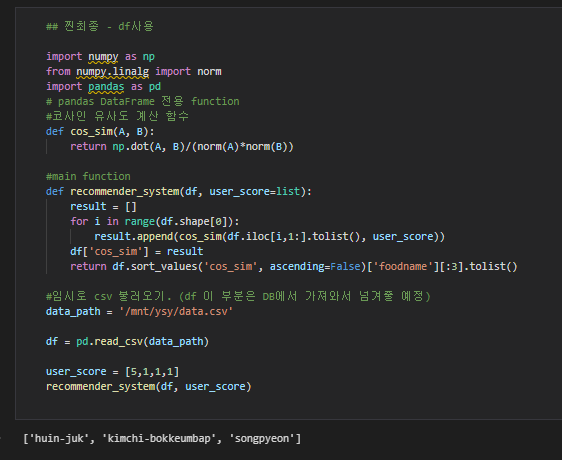
코사인 유사도 공식을 사용해 두 벡터가 얼마나 닮았는지를 판별한다. 따라서 외국인이 입력한 설문들과 우리의 DB에 있는 한국인이 설문한 음식들의 맛 지표를 가지고 외국인의 입맛과 DB에 있는 음식의 맛지표를 비교하여 가장 닮은 상위 3가지 음식을 추천해준다.
이렇게 AI파트의 3가지 기능 구현 데이터셋 구성, 음식탐지 모델 training 및 tuning, 음식선호도에 따른 음식 추천에 대한 설명을 마쳤다.
어려웠던 점
1. 데이터셋 구성 및 정제(데이터셋의 결측값으로 인해 두 데이터셋을 합치고, 결측,이상치는 제거)
2. YOLO 모델 학습 방향성 잡기 (wandb 사용법 & 하이퍼파라미터 설정)
배운 점
1. 데이터셋 전처리 하는 법(jupyter notebook과 dataframe, os모듈 적극 활용, skearn의 train_test_split)
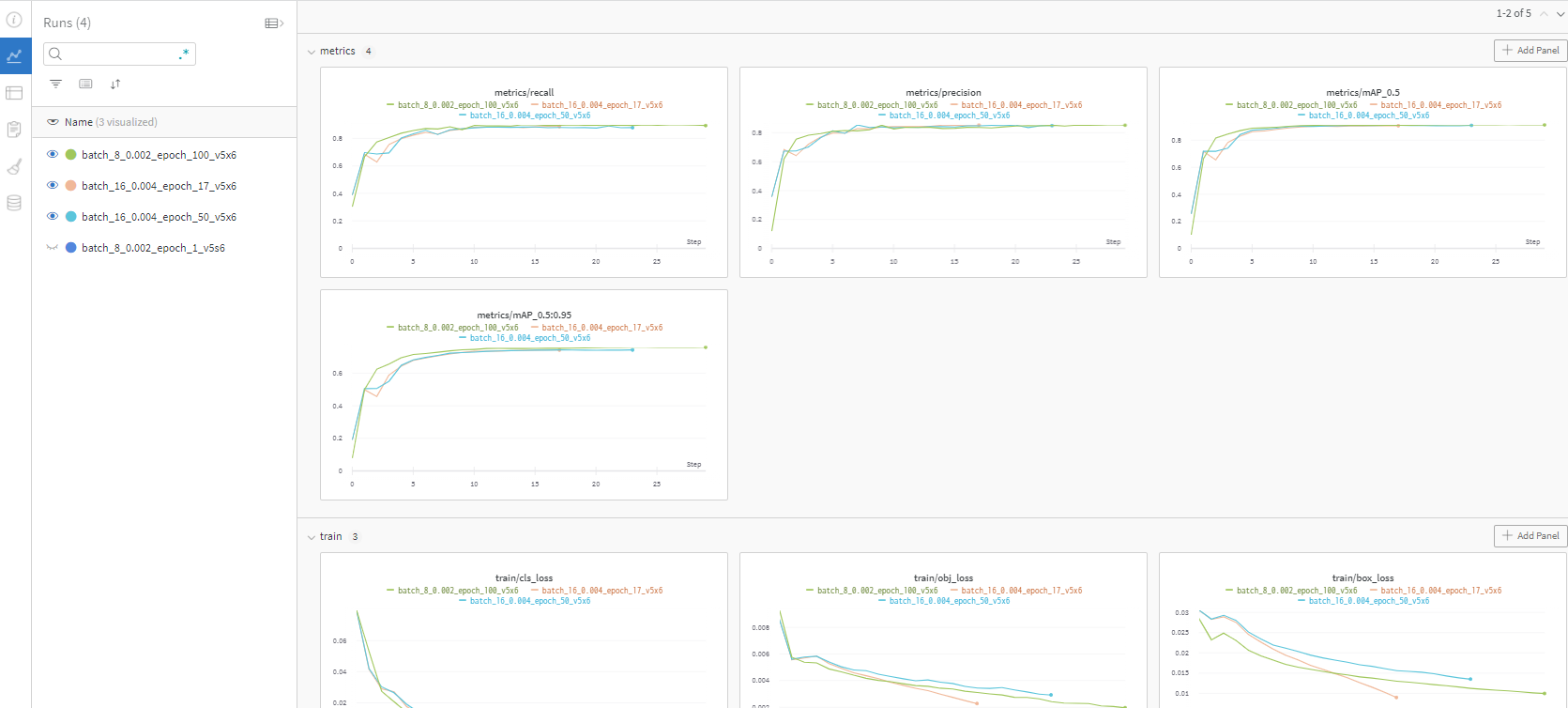
2-1. wandb 사용 (val_loss와 train_loss의 정확한 값 보기, recall과 precision 확인, smooth로 학습곡선 확인하기, 꼭 loss가 낮다고 해서 좋은 모델이 아니다. 실제 inference 돌려서 확인)
2-2. 하이퍼파라미터 설정 팁 (epoch 수 - early stop 및 overfitting/underfitting , lr 설정 - dataset 크기에 따라 초기값 설정, batch size 설정 - 허용되는 GPU 메모리에 따라)
앞으로의 계획
- YOLO 말고도 다른 컴퓨터비전 모델들에 대한 논문 리뷰 및 코드구현, 성능 개선할 수 있는 솔루션 찾기(ResNet)
- Object Detection 말고도 Classfication, Segmentation, Pose Estimation, GAN 등 이미지 분야에 대한 논문 리뷰 및 코드 구현
- 음식 탐지 작업과 입맛에 따른 간단한 음식 적합도 추천까지 완료하였으니, 더 나아가서 위치 정보, 먹기 싫은 재료 골라주기, Image Captioning을 사용한 음식 메뉴 소개 등을 추가하여 맛집 추천 서비스까지 연계할 예정
README.md 설명
##프로젝트 설명
한식에 관심이 있는 외국인들에게 드라마,영화 속에서 발견한 한식 사진 또는 한국여행 중 찍은 한식 사진을 업로드하면 82종의 한식 중에서 어떤 한식인지 detection 및 classification해주고, 해당 음식에 대한 레시피, romanized name, 간단한 설명, 재료 등을 알려줍니다.
( 7팀 AI 프로젝트 최종발표.pdf를 참고하세요 )
또한 그 음식을 먹어보지 못했더라도 얼마나 본인의 입맛에 잘 맞을지 5개의 레벨로 알려주고, 매운맛, 신맛, 짠맛, 기름진 맛의 선호에 따라 잘 맞을만한 한식 상위 3개를 추천해줍니다.
( Kfood음식 82종 수작업_final.csv, cos_sim_추천시스템.ipynb를 참고하세요 )
이 레포지토리에는 AI파트의 업무 코드만 올렸기에 training과 inference, 파이썬 코드 실행(cos_sim_추천시스템.ipynb)을 통한 음식 추천만 가능합니다. 전체 웹서비스 코드는 추후 업데이트 하겠습니다.
##사용방법
해결되지 않는 문제는 아래 yolov5 GitHub를 참고하세요.
https://github.com/ultralytics/yolov5
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
1. 아래 링크에서 우리팀이 만든 데이터셋 다운받아서 zip 풀고 datasets/ 아래에 그림과 같이 폴더 설정하기
datasets/kfood 아래에 이렇게 파일 구성


그리고 kfood.yaml에 datasets위치를 잘 설정해줍니다. 만약 음식탐지가 아닌 다른 데이터를 training시켜 탐지하고 싶다면 datasets 폴더 안에는 저희 kfood 데이터셋 뿐 아니라 coco 등 넣으시고 싶으신 데이터셋을 넣고 학습시킬 수도 있습니다. (마찬가지로 kfood.yaml 대신 coco.yaml 등 만들어서 사용하시면 됩니다)
2. 가상환경 만들기
# 가상환경 생성
python -m venv 가상환경이름
# 가상환경 activate - 이건 리눅스, Mac, 윈도우 등에 따라 다릅니다
source 가상환경이름/Scripts/activate
# 가상환경에 requirements.txt 설치 - 필요한 라이브러리들 설치
pip install -r yolov5/requirements.txtencoding 및 Upsampling 문제로 인해 저희 코드로 Yolov5를 돌리시려면 저희가 올린 requirements.txt로 pip install 하시기를 바랍니다. (Yolov5 GitHub의 requirements와 다릅니다)
여기까지 했다면 저희의 kfood 프로젝트를 이용할 준비가 완료되었습니다.
3. inference 하기
- team07_test.py 에서 input image, 사용할 모델, result를 저장할 경로 등 원하는 대로 수정해줍니다.
특히 opt.device = 'cpu'는 gpu가 없는 컴퓨터라면 꼭 넣기, gpu가 있다면 주석처리 하시기를 바랍니다.
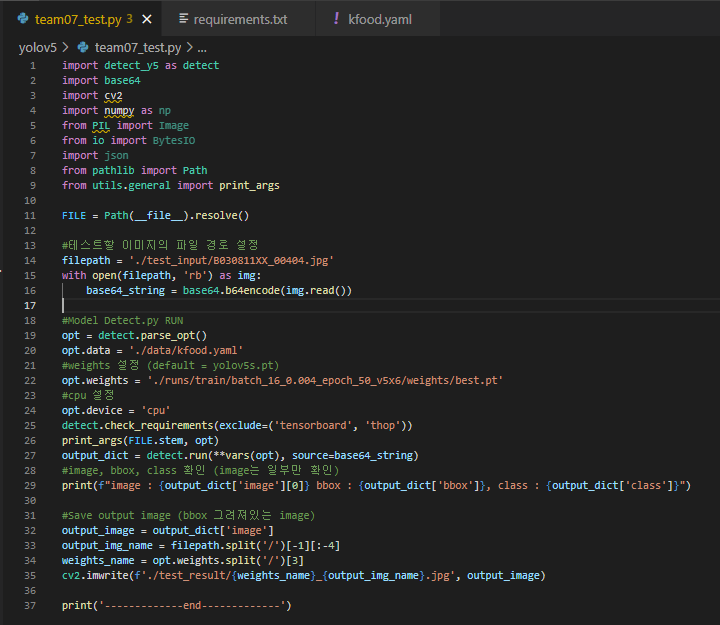
그 다음 가상환경으로 들어간 후 아래 코드를 실행합니다.
python team07_test.py
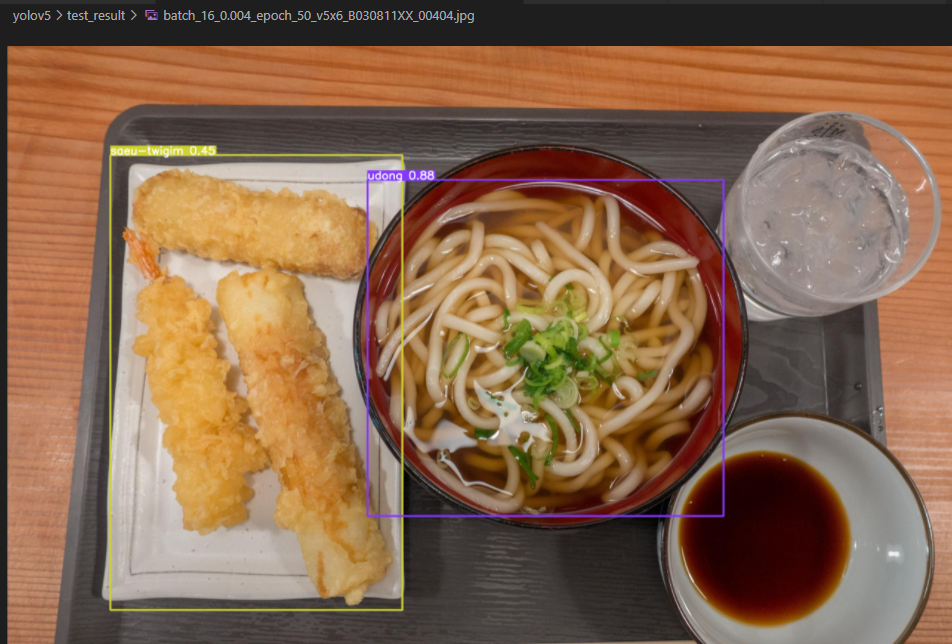
위 사진과 같이 test_result 폴더 안에 음식이 detect된 결과 이미지가 저장된 것을 볼 수 있습니다.
4. train 하기
- pretrained된 모델 다운로드해오기 : yolov5dowonload.py
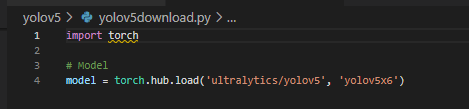
원하는 모델 종류를 골라서 수정하면 로컬에 .pt 확장자의 모델이 다운받아집니다.
- (권장)tmux 사용하기 : training은 매우 오랜 시간이 걸리는 과정입니다. 따라서 로컬에서 training을 시킨다면 컴퓨터를 장시간 켜놓는 것이 부담될 수 있습니다. tmux는 원격 GPU 서버를 사용하여 train 시킬 때 컴퓨터를 꺼도 돌아가게끔 해주는 session입니다. 개인 로컬 PC를 꺼놔도 원격으로 training을 진행할 수 있습니다.
우분투 또는 리눅스 tmux 설치: sudo apt-get install tmux
windwos tmux 설치 : 아래 과정 참고

tmux 사용법
# 새로운 세션 생성
tmux new -s (session_name)
# 세션 목록
tmux ls
# 세션 다시 시작하기(다시 불러오기)
tmux attach -t session_number
# 세션 종료
exit- 하이퍼파라미터 변경 : hyp.scratch-low.yaml
- (권장) wandb 사용하기 : wandb는 머신러닝의 training과정을 시각화하고, logging 해주는 사이트입니다. 적절한 하이퍼파라미터를 찾기 위해 사용되기도 하고, training한 이력들을 확인하기 위해 쓰기도 합니다. loss 그래프, precision 그래프 등을 깔끔하게 볼 수 있습니다.
https://wandb.ai/site 회원가입 및 로그인
- training run 시키기
(예시)
# Single GPU
python train.py --img 640 --batch 8 --epochs 10 --data kfood.yaml --weights yolov5x6.pt --name batch_8_0.002_epoch_10_v5x6
# Multi GPU
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch 16 --epochs 10 --data kfood.yaml --weights yolov5x6.pt --device 0,1 --name batch_16_0.002_epoch_10_v5x6--batch 는 GPU 메모리에 따라 8의 배수로 결정합니다(byte 단위 때문).
--weights 에는 pretrained된 다운로드 받은 모델 종류를 적습니다.
--device 뒤에 오는 옵션은 cuda device를 말합니다. gpu 갯수에 따라 gpu 0 또는 gpu 0,1 gpu가 없으면 cpu 등 다양하게 올 수 있습니다.
--name 뒤에 오는 옵션은 train 시킬 모델의 이름입니다. 설정하신 하이퍼파라미터와 pretrained 모델 종류 등을 본따 지으시는 게 좋습니다. 옵션에 대한 설명들은 train.py 에 있습니다.
학습된 모델은 runs/train 안에 저장됩니다.
wandb 옵션 : yolov5 GitHub에서 wandb 관련 코드를 제공해주어서 train 시 1,2,3 중 3을 입력하면 wandb를 사용하지 않고 training합니다. 저는 2를 입력하여 사용해보겠습니다
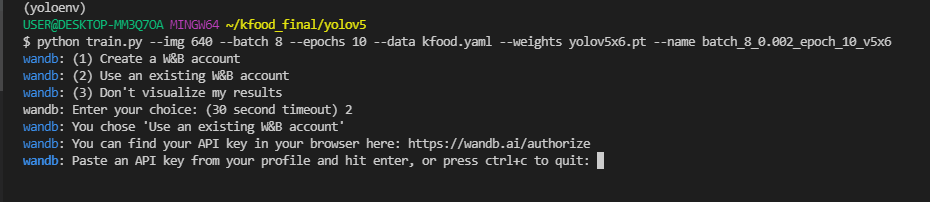
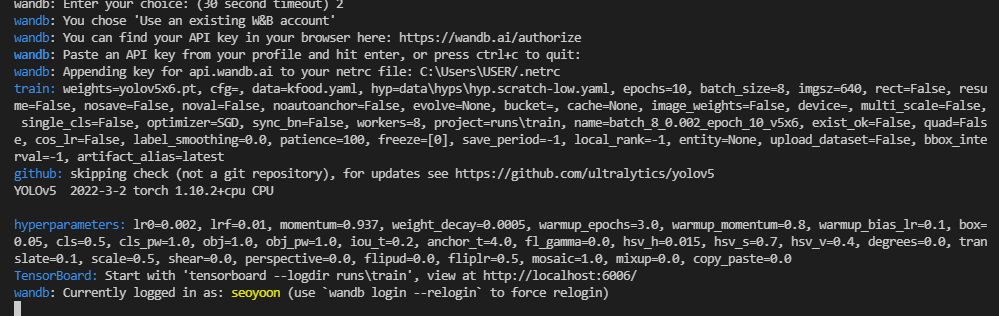

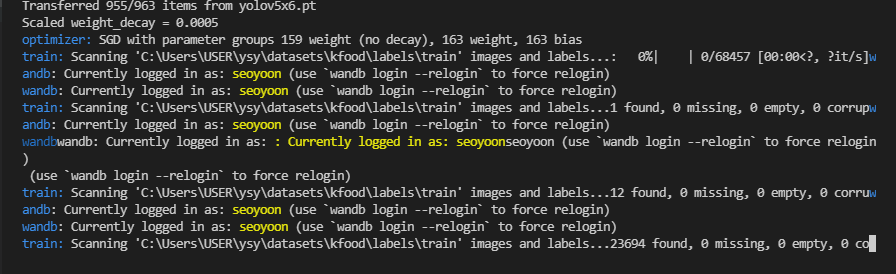
이렇게 training이 잘 실행되고 있고(지금은 로컬에서 CPU로 돌리는 상황이라 실제 training을 할 때는 주로 원격에서 GPU로 돌립니다.)
(권장 - wandb) 아래 사진처럼 wandb에도 잘 연결되는 것을 볼 수 있습니다. 아직은 1epoch이 지나지 않아 아무 그래프가 뜨지 않았습니다. 1 epoch이 지나고 나면 그래프가 뜨게 됩니다.