2022. 3. 10. 23:08ㆍ프로젝트/KFood





epoch 50은 saewoo-twigim과 udon을 모두 잡아내는 반면, epoch 100은 잡아내지 못한다.







recall , precision, mAP가 모두 epoch 100이 더 성능이 좋은데 왜 더 못잡는 것일까?
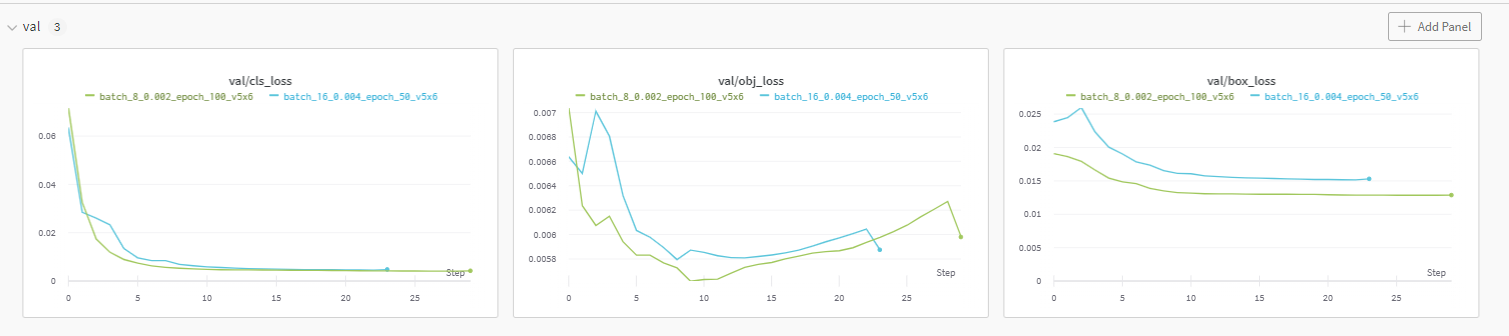
설마 obj_loss나 cls_loss 때문인걸까?
best.pt를 선정하는 기준이 무엇일까?
----------------------------------------------------------------------------------------------------------------------------------
epoch 50보다 epoch 100이 더 inference가 못잡았던 이유에 대한 분석
테스트한 환경과 학습한 환경, wandb의 threshold환경이 달라서 wandb에서는 성능이 좋아도 실제로는 inference에서는 못 잡을 수 있다.
그런데 만약 환경을 동일하게 해줬어도 overfitting이나 모델이 confidence를 더 높이는 방향으로 학습하도록 학습된 걸 수도 있다. (detection이다보니 iou문제가 있어서 조금 복잡함)
-> wandb(mAP_0.5), detect_y5.py의 iou threshold, train시에 쓰는 threshold 세 개를 다 동일하게 맞춰줘야 완전 공정한 환경이다.
+ 그리고 과적합도 일어난 것 같음
10epoch 이상부터는 잘 맞추는 것만 더 잘맞추려고 한다. 그게 loss가 줄어드는 방향이니까. 그래서 메뉴를 좀 버리더라도 신뢰도가 높은 것만 잡으려는 방향으로 학습하게 된 거 같다.
- best.pt는 metric에서 선정된다. loss를 보고 가장 낮았던 애로 선정하는 것이 아니다.
+ 논문에서 쓸 때 -> 성능높이는 게 제일 중요하므로 best.pt로 선택하는 것도 괜찮다.
+ (실제 서비스에 사용할 때) best.pt보다는 epoch마다 저장하는 게 좋을 수도 있다. 지금같은 경우도 best.pt(metric)상 보다는 epoch10정도가 오히려 더 괜찮을 것 같은 가능성이 있어보임.