2022. 3. 3. 14:53ㆍ프로젝트/KFood
코사인 유사도
- 컴퓨터 비전보다는 자연어 처리? 추천시스템 쪽에 자주 쓰이는 방법인 것 같다. (Word2Vec과 비슷한 원리라고 함)
- 코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 된다. 즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미한다.
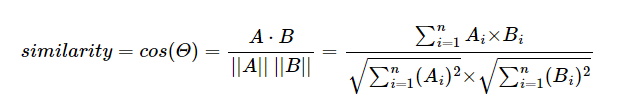
kfood 음식 추천에 적용
- 따라서 우리 프로젝트 같은 경우는 82가지의 한국 음식에 대한 신맛,짠맛,기름진맛,매운맛 column에 대한 점수가 1~5까지 존재하고, 그 점수를 벡터공간에 임베딩 했다고 치고, (예를 들면 (0,0,0,0) -> (1,3,2,4) 라는 벡터가 생김)
이 벡터Our와 유저가 입력한 본인의 신맛,짠맛,기름진맛,매운맛의 선호도에 대한 점수 벡터User를 이용한다. (예를 들어 (3점,2점,5점,1점) 을 주면 (0,0,0,0) -> (3,2,5,1) 이라는 벡터User 를 임베딩. )
- 벡터Our 82가지와 벡터User 1가지를 for문을 돌려 모두 코사인 유사도를 구한 후 그 82가지를 내림차순으로 sorting해서 코사인유사도가 가장 높은 음식들을 Top3든([:2]) 가장 높은 1위 하나든([0]) 추천을 해준다.
코드 짜기(jupyter notebook)
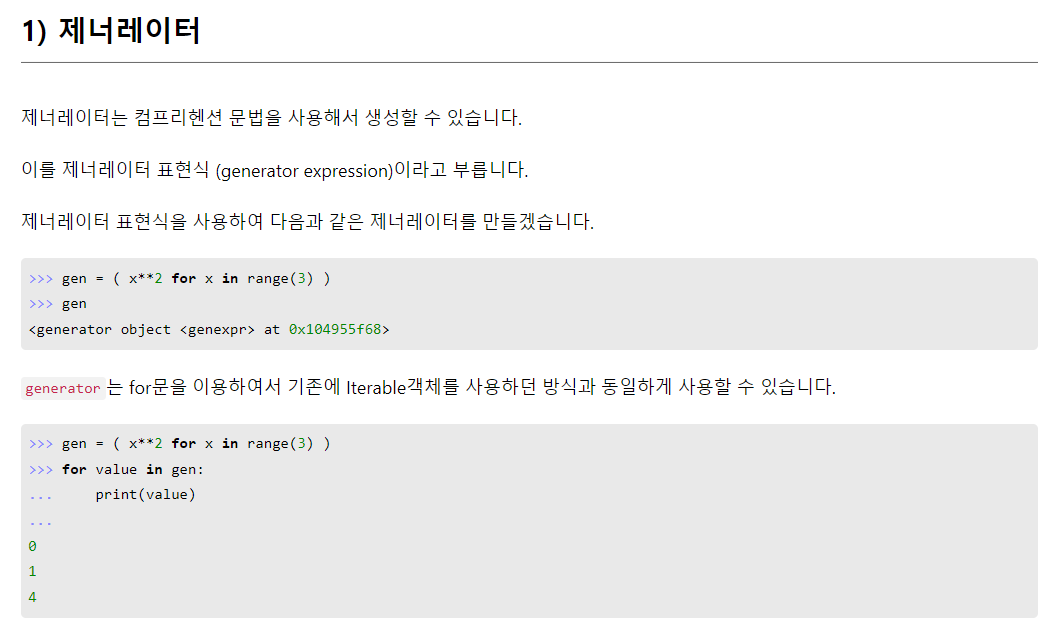
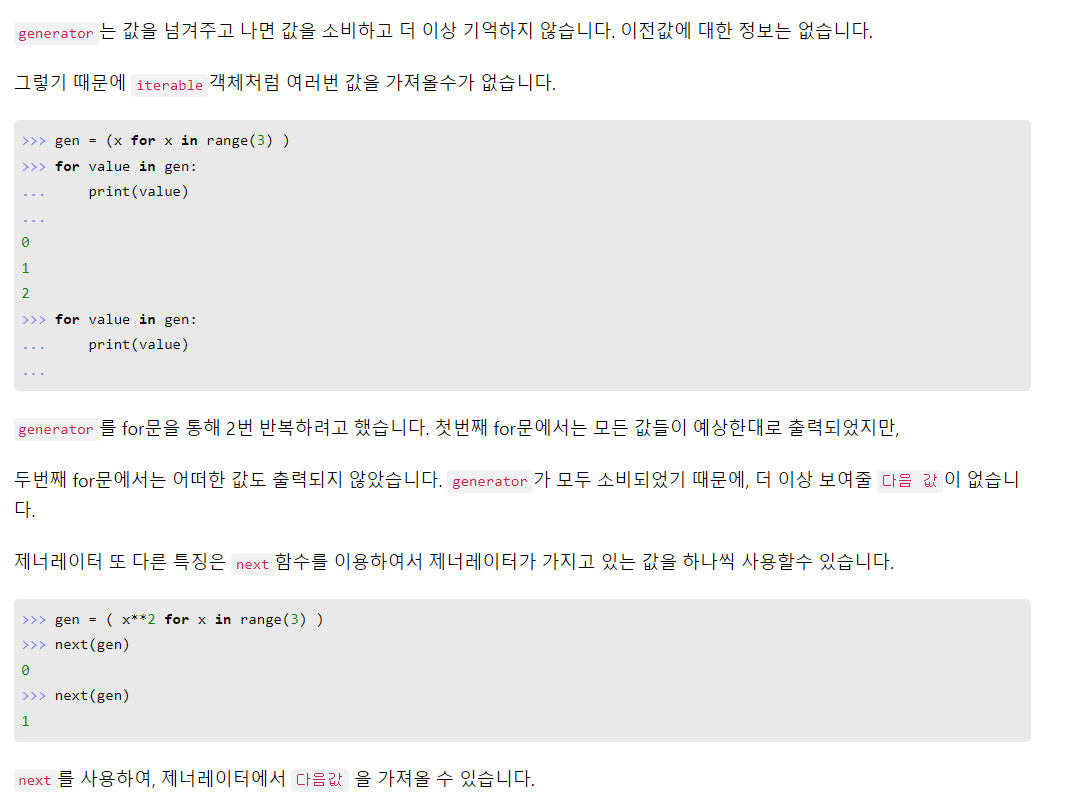
- generator
- pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
import pandas as pd
import numpy as np
food_list = ["gaji-gui", "galbi-gui", "galbi-jjim", "gamja-bokkeum", "gamja-twigim", "geon-saewoo-bokkeum", "gejang", "gyeongdan", "gyeran-mari", "gyeranhurai", "godeungeo-gui", "gorgonzola-pizza", "gochu-jangajji", "ojingeochae-muchim", "gopchang-jeongol", "gunmandu", "gimbap", "kimchi-bokkeumbap", "kimchi-jjigae", "kkakdugi", "naengmyeon", "dakgalbi", "dakjjim", "doenjang-jjigae", "dubu-gimchi", "tteokgalbi", "tteokguk", "tteokbokki", "ramyeon", "maneul-jangajji", "margherita-pizza", "mandu-guk", "modeum-twigim", "miyeokguk", "baechu-kimchi", "bo-ssam", "budae-jjigae", "bulgogi", "bibim-guksu", "bibim-naengmyeon", "bibimbap", "samgyeopsal-gui", "samgyetang", "saeu-bokkeumbap", "saeu-twigim", "saengseonjeon", "soseji-bokkeum", "songpyeon", "sukjunamul", "sundae", "sigumchi-namul", "al-bap", "aehobak-bokkeum", "yangnyeom-chicken", "omeu-raiseu", "udong", "yubuchobap", "yukhoe", "japgokbap", "japchae", "jangeogui", "jangjorim", "dwaejigogi-bokkeum", "jokbal", "gimgaru-jumeokbap", "jjajangmyeon", "jjamppong", "jjokgalbigui", "jjukkumi-bokkeum", "jjinmandu", "cheese-pizza", "curry-rice", "combination-pizza", "kongguksu", "pajeon", "hangwa", "haemuljjim", "haejangguk", "hoe-muchim", "huraideu-chicken", "hunjeori", "huin-juk"]scores = np.array([[1,3,2,4] for i in range(len(food_list))])
scores = np.array([np.random.randint(1,6,size=4) for i in range(len(food_list))])
print(scores)
scores.T
# df 생성
scores = np.array([np.random.randint(1,6,size=4) for i in range(len(food_list))])
print(scores.shape)
df = pd.DataFrame(scores, index=food_list,columns=['spicy','sour','salty','oily'])
df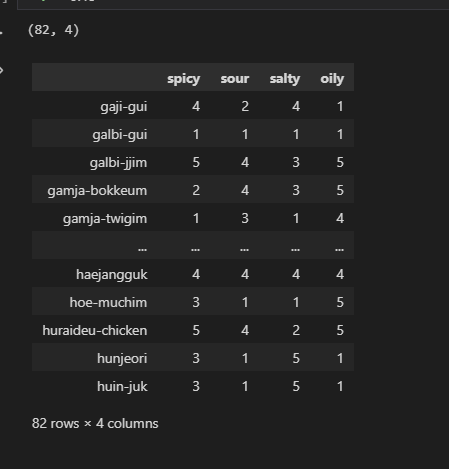
from numpy.linalg import norm
from numpy import dot
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
#코사인 유사도, 1일 수록 가까운 것
print(cos_sim([1,2,3,4], [5,4,3,1])) # 둘이 다른 것
print(cos_sim([1,2,3,4], [1,2,3,5])) # 둘이 비슷한 것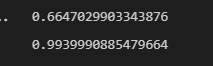
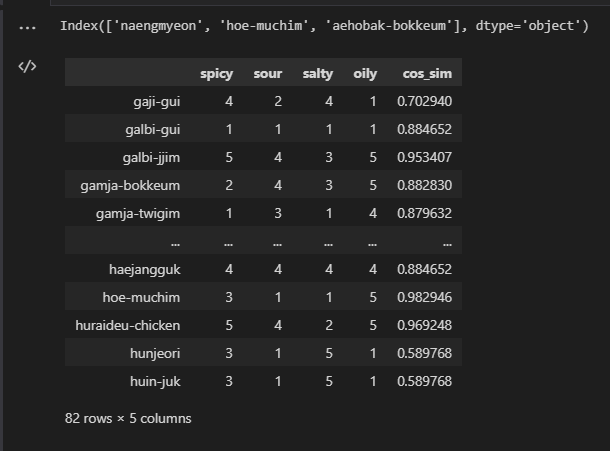
df.loc['gaji-gui',:]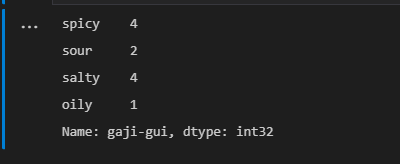
list(df.loc['gaji-gui',:])
def recommender_system(df, user_score=list):
result = []
for i in range(df.shape[0]): # 82
result.append(cos_sim(list(map(int,df.iloc[i,:])), user_score))
df['cos_sim'] = result
return df.sort_values('cos_sim', ascending=False).index[:3]
# 코사인 유사도값을 기준으로 내림차순 정렬, Top3 음식이름 뽑기recommend_result = recommender_system(df, [4,2,1,5])
print(recommend_result)
df