2022. 3. 2. 19:29ㆍ프로젝트/KFood
우리 팀이 이번에 외국인이 K드라마, 영화, KPOP 방송 등에 나온 한식 이미지를 올리면
데이터셋 내에 존재하는 한식 메뉴 150개 중 무엇인지 분류하고, 이에 필요한 서비스들을 제공해주는 프로젝트를 진행하고 있다.
기획

기획단에서 레시피만 국한해서 서비스를 만들었었는데, 생각해보니 기능이 많다고 좋은 앱은 아니니까
팀원분인 무원님의 고찰에 따라 외국인에게 한식 이미지를 분류해주고, 한식에 대한 정보를 제공하고, 그 한식이 내 입맛에 맞을 지 취향분석을 해주고, 먹어보고 싶은 외국인에게는 근처맛집이나 밀키트 제공, 레시피 제공 이렇게 세 개를 생각했는데 여기서 다 제외하고 recipe만 제공하기로 했다.
사용한 데이터셋 필요한 용량 16GB
https://aihub.or.kr/aidata/13594
한국 이미지(음식)
한국 음식 150종(종별 약 1천 장)의 데이터를 구축한 이미지 데이터 제공
aihub.or.kr
사용한 깃허브
https://github.com/djagusgh/EMO
GitHub - djagusgh/EMO: 한식 분류 딥러닝 모델을 활용해 한국 내 외국인들에게 맞춤형 정보를 제공하
한식 분류 딥러닝 모델을 활용해 한국 내 외국인들에게 맞춤형 정보를 제공하는 안드로이드 앱 - GitHub - djagusgh/EMO: 한식 분류 딥러닝 모델을 활용해 한국 내 외국인들에게 맞춤형 정보를 제공하
github.com
https://github.com/sejongresearch/FoodRecommender
GitHub - sejongresearch/FoodRecommender: 작위적인공조 팀, 음식추천분류기 (2019)
작위적인공조 팀, 음식추천분류기 (2019). Contribute to sejongresearch/FoodRecommender development by creating an account on GitHub.
github.com
구현 환경 : 로컬에서는 conda 가상환경.. 그러나 16GB 짜리 데이터셋이 GPU가 있는 내 데스크탑에서는 돌아가지 않아서 CPU만 있는 노트북에서 돌려야하므로 colab의 GPU와 데이터공간을 사용.
2월 16일 17시 현재 돌려보는 모델 : EMO 팀에서 진행한 모델.
사용한 colab 코드




EMO 팀에서는 위와 같은 과정으로 인공지능 모델을 개발하였다. 일단은 우리도 이대로 따라가보자.
전체 데이터 폴더 kfood 를 final_food라는 폴더에 train, validation, test 로 8:1:1로 split

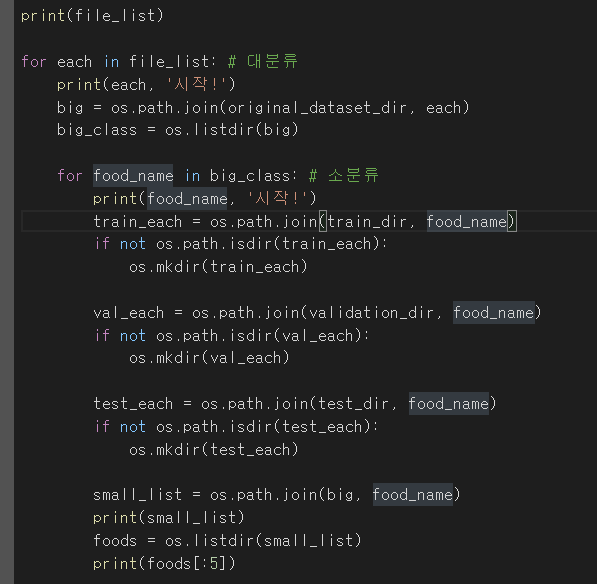
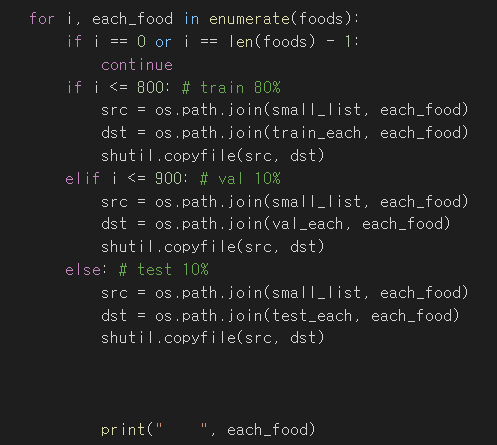
결과 파일



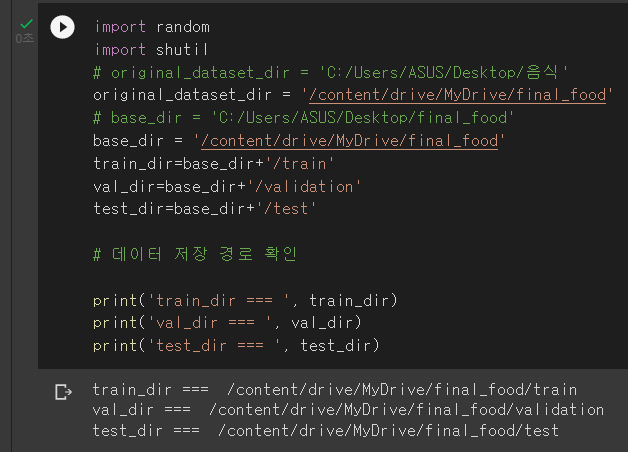
colab에 Mount하고 드라이브에 저 final_food 폴더를 통째로 저장.. 업로드만 한 24시간 걸렸다.
그 다음 sage maker를 사용하는 코드가 있는데, 우리 팀은 sagemaker는 쓰지 않을 것 같다(한 시간당 가격이 꽤 비싸다고 한다.)





이런 식으로 data augmentation을 하면 이미지가 flip 되거나 rotate 되거나 등등 여러 경우로 돈다.

이러한 augmentation과정(width_shift, rotation 등..) 은 train 데이터에 대해서만 적용한다고 한다. 그리고 데이터셋의 크기가 크면 웬만하면 generator를 쓰는 것이 좋다고 한다.



target size는 299 x 299로 정사각형이고, 이미지의 각 픽셀을 255로 나눠주는 게 되게 중요했었다.(현호님과 했었을 때 test도 255로 나눠주지 않으면 이미지 픽셀값을 너무 크게 인식해 아예 분류를 해내지 못했었다.)
batch size는 32로 2의 몇승 형태로 한다고 한다. gpu로 병렬로 거대한 양의 이미지들을 묶음묶음으로 나눠서 넣는 거라고 이해했다. (32개씩 나눠서 넣는 119933개를 넣는거다...!?)

이제 모델 구성. EMO 팀은 음식 분류를 InceptionV3와 MobileNetV2를 사용했다고 한다.


잠깐 각 레이어들을 쓰는 이유를 정리해보자.
Convolution : 이미지 데이터를 1차원배열이 아닌 2차원배열로 저장하는데, 이 때 input * kernel(=filter)를 해서 feature map를 뽑아낸다. 이러한 kernel은 행렬이고, 그 행렬들을 이루는 각 값들(0.6, 0.3243등등) 을 weight라고 부른다. 이러한 kernel들로 이루어진 layer를 Conv Layer라고 부른다. (그리고 하나의 Conv layer안에는 여러 kernel이 있을 수 있음. 그게 바로 channel의 갯수) 즉 정리하자면 2차원 배열계산을 이용해 Feature Map을 뽑아내는 역할을 한다. weights 값들이 모이면 ->kernel 행렬 이 모이면 -> Conv layer 이 모이면 -> CNN 구성
AvgPool : Conv Layer와 함께 쓰이는 Layer로, Feature Map의 사이즈(16x16)를 줄여서 Parameter 개수를 줄여 과적합 조절. Avg 방법은 예를 들어 Feature Map 16x16에서 4개의 요소를 평균낸 값으로 선택해서 4x4로 줄인다.
MaxPool : Conv Layer와 함께 쓰이는 Layer로, Feature Map의 사이즈(16x16)를 줄여서 Parameter 개수를 줄여 과적합 조절. Max 방법은 예를 들어 Feature Map 16x16에서 4개의 요소 중 제일 큰 값으로 선택해서 4x4로 줄인다.
Concat : 입력 list를 연결하는 layer이다. concatenation axis를 제외하고 모두 동일한 shape의 tensor list를 input으로 주고, 그 모든 input들을 결합시킨 하나의 tensor를 반환한다.
Dropout : 과적합의 고전적 해결 방법으로는 regularization(너무 training data만 공부하지 않도록 패널티 부여), data augmentation(데이터증강) 방법이 있다. 그리고 새로 나온 방법으로 Batch Normalization(2015년)과 Dropout(2012년)이 있다. Network의 일부를 생략하고 학습을 진행하는 것. 이 생략된 일부는 학습에 영향을 미치지 않는다.
Fully Connected(FC) : 1차원 배열로 Conv/Pooling의 결과물을 가지고 Class를 판별하는, 즉 이미지를 분류/설명하는 데 사용된다.
Activation : 특정세기 이상의 자극이 오면 활성화를 시켜주는 함수. 즉 0 또는 1로 나온다. ( ex . Relu, softmax )
Softmax : predict한 class들(car -1, person 3, dog 2)의 확률값들을 0과 1사이로 표현해준다(car 0.01, person 0.72, dog 0.27) 그리고 그 중에서 가장 확률이 높은 class(car)를 결정하면 된다. 즉 총 벡터의 합이 1이 됨.
Concat 설명
https://keras.io/api/layers/merging_layers/concatenate/
Dropout 설명블로그
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=laonple&logNo=220818841217
[Part Ⅵ. CNN 핵심 요소 기술] 2. Dropout [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic Segmentat...
blog.naver.com
----------------------------------------------------------------------------------------------------------------------------------
그럼 keras가 제공하는 모델들은 어떤어떤 게 있을까
keras.models 안에는 이런 모델들이 미리 내장되어 있다고 한다.
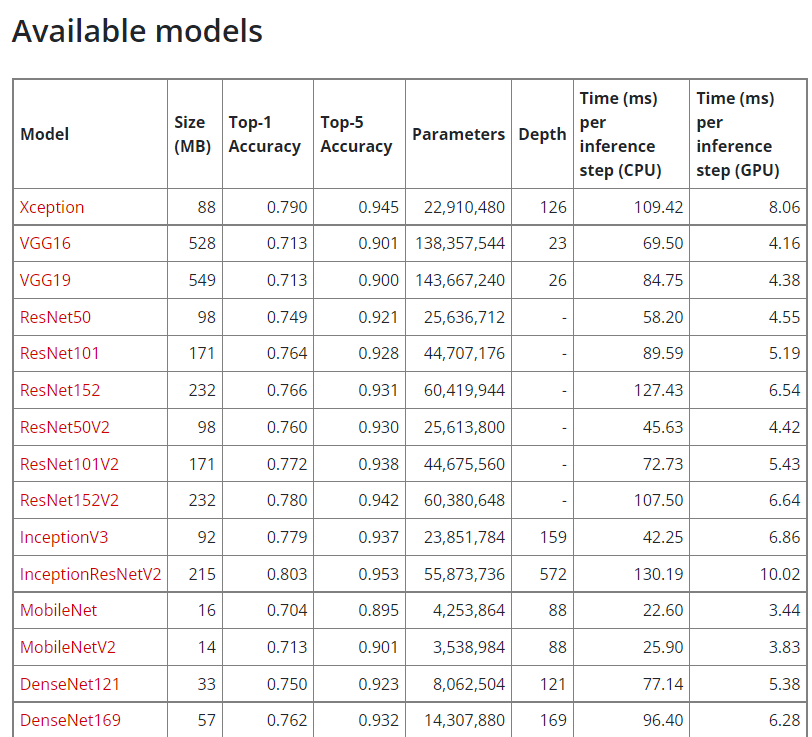
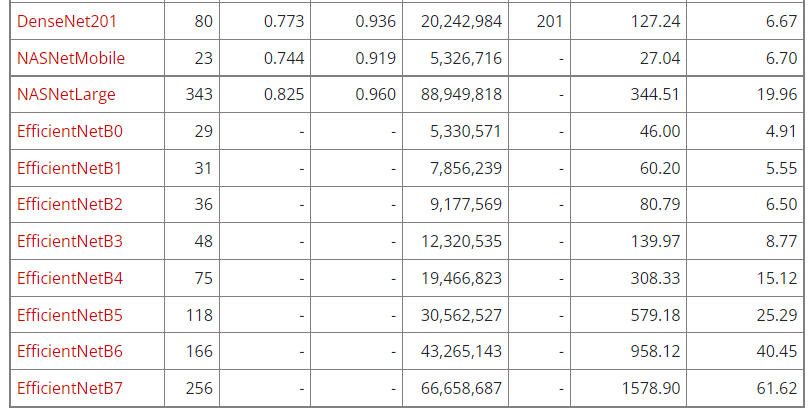
저번에 현호님이랑 사용했던 EfficientNetB0도 있다
음.. 속도측면에서는 ResNet이 빠른 것 같다 ㅋㅋ parameter와 depth가 적어서 그런가보다..(잘은 모르겠다)
대신 정확도는 표에서 아래쪽으로 갈 수록(속도가 느린) 애들이 더 정확하다.

colab에서 사용가능한 GPU,CPU를 확인한다. 나중에 Use_Multiprocessing을 True로 하려면 여기에 여러 개의 처리프로세서들이 잡혀야 할 것으로 보인다.

그 다음은 모델 저장 경로 설정
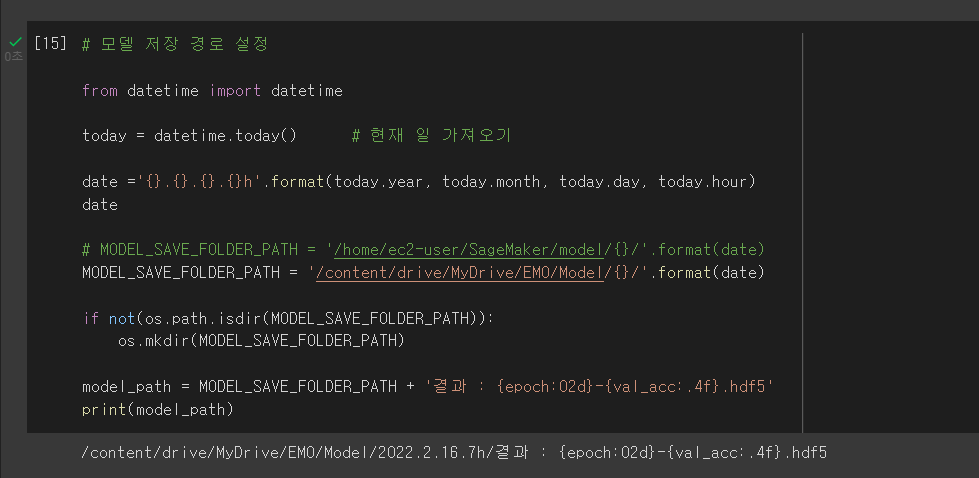

구글 드라이브에 저장되게 일단 해놨는데, colab은 런타임연결시간이 있어 아마 날아가기 전에 미리 저장을 해줘야 할 것이다.
모델 수정 : InceptionV3 모델에 마지막 층을 빼고 다음과 같은 층을 추가한다.
그리고 거기에 image_generator들을 투입한다.
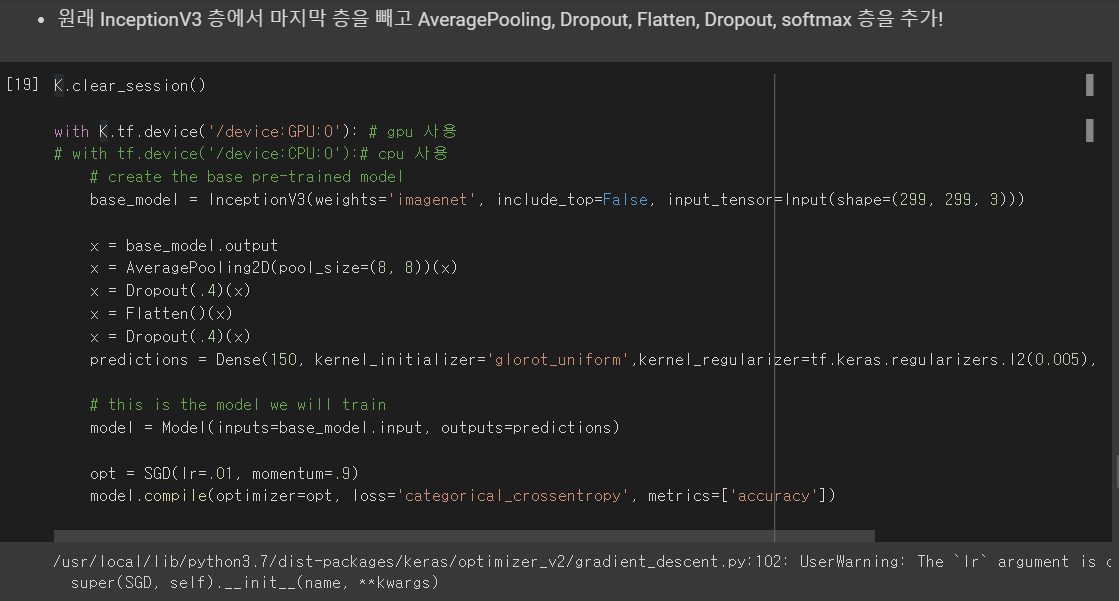
일단 케라스에서 제공해주는 weight와 모델을 채용해서 시작을 했고, input_tensor도 잘 지정해주었다.
그 다음, 그 모델의 마지막층만 저렇게 수정을 해준 모습이다. -> base_model.output으로 가져온다
그리고 저렇게 Avgpool, Dropout 등등 필요한 레이어들 추가해주고,
model.compile을 시켜서 optimizer로는 SGD, loss측정방법으로는 categorical_crossentropy, 측정할 것으로는 accuracy를 metrics에 추가한다.
그 다음 fit할 때 필요한 콜백함수들을 정의


그 다음 lr_scheduler라는 작업도 추가로 해줘서 cost_function이 최적값주변에서 맴도는 것을 완화한다.
그리고 드디어 지금 엄청 오래 걸리는.. model.fit을 진행한다. keras에서는 model.fit과 model.fit_generator를 모두 제공하는데
fit : 전체 데이터셋을 한번에 fit method로 통과시킴
fit_generator : x와 y를 직접적으로 통과시키지 않고, generator를 통해 데이터를 불러온다.
generator는 보통 큰 데이터셋에 적용하며
일반 데이터셋과 다르게 multiprocessing을 진행할 때 데이터 중복을 막기 위해 사용한다고 한다..?

ver 1 과 ver 2가 있는데 ver1는 매 epoch마다 콜백함수를 실행시켜서 early stop이나 checkpoint 저장 등을
진행하는 코드고
ver 2는 그냥 0~10 epoch까지 한번에 돌리고 끝나고 나면 save model을 하는 코드이다
(아 use_multiprocessing은 cpu,gpu 둘다 잡히니 ver1, ver2 둘다 True로 해도 된다.)

지금 보면 1시간 돌렸는데도.. 200까지밖에 못했다. 1epoch이 3700까지 돌려야하는데.. 1시간당 200밖에 못 한다니
팀원분인 수현님네 학교의 연구실 컴퓨터 GPU 빵빵한 걸로 일단 fit을 시켜야 할 것 같다.
그리고 나서 나온 model을 load_model 해서 써야될 것 같다.