2022. 3. 3. 13:39ㆍ프로젝트/KFood
원작자 inference 실행 코드
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream우리 팀 inference 실행 코드
python team07_test.py
원작자의 detect.py vs 우리 팀의 detect_y5.py



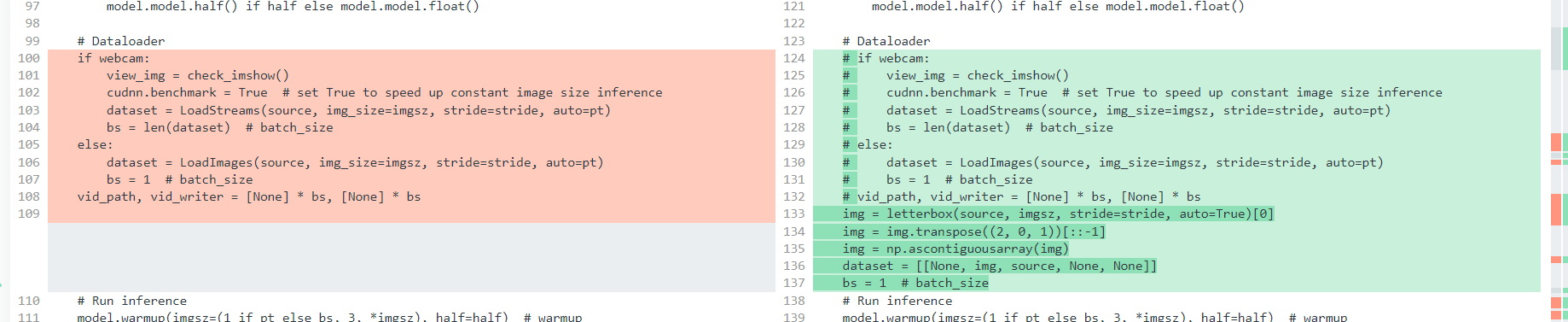

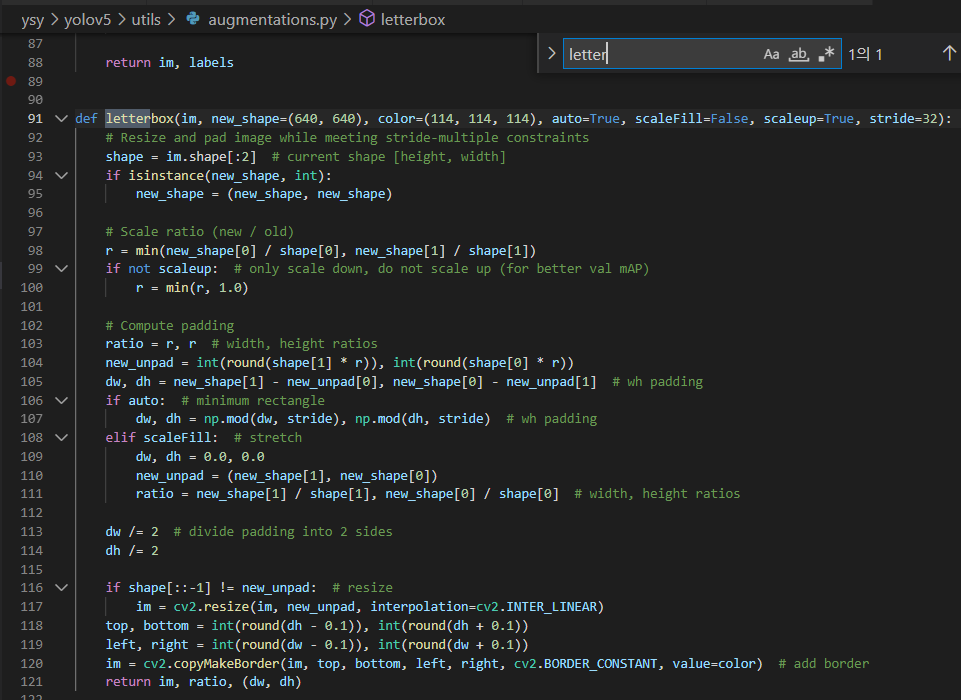

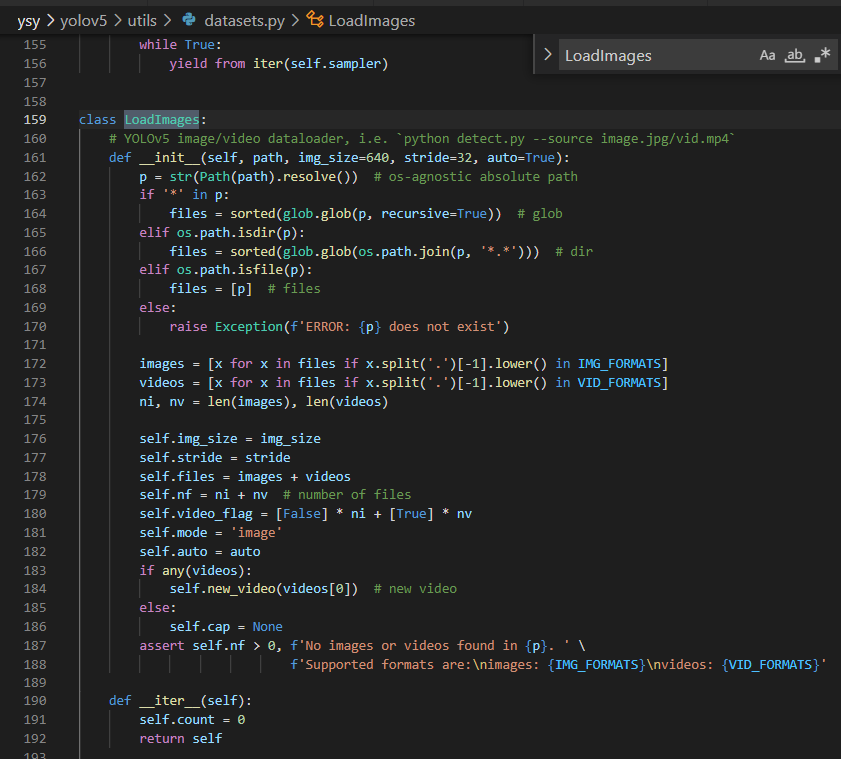



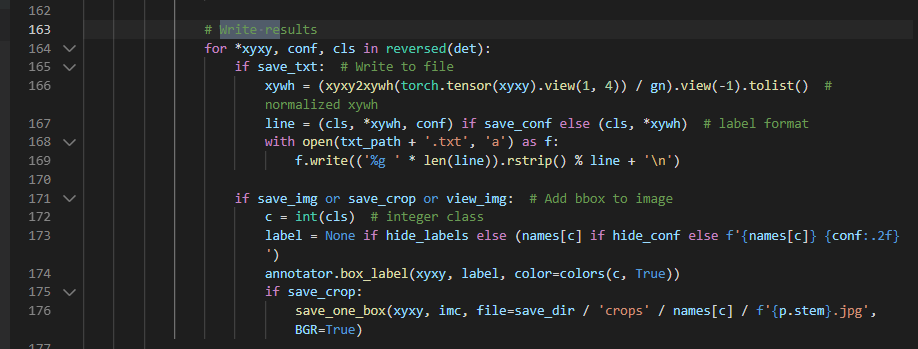
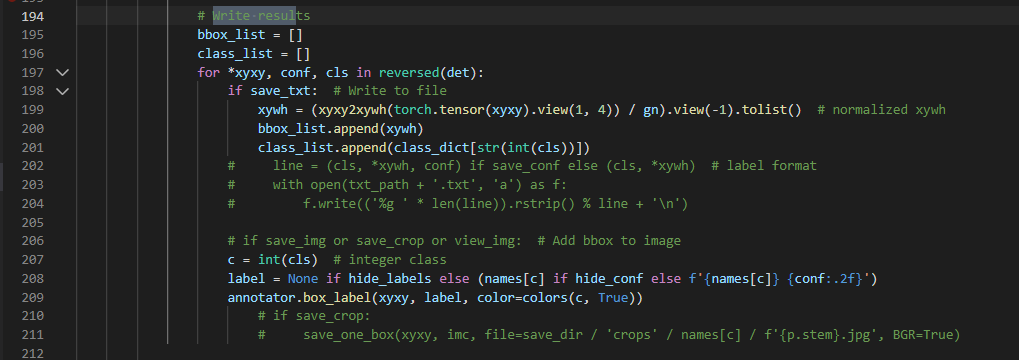


우리 팀의 team_07.py 코드
import detect_y5 as detect
import base64
import cv2
import numpy as np
from PIL import Image
from io import BytesIO
import json
from pathlib import Path
from utils.general import print_args
FILE = Path(__file__).resolve()
# import os
# os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#테스트할 이미지의 파일 경로 설정
filepath = './data/images/foods_2.jpg'
with open(filepath, 'rb') as img:
base64_string = base64.b64encode(img.read())
#Model Detect.py RUN
opt = detect.parse_opt()
#cpu설정
opt.device = 'cpu'
#weights 설정 (default = 'yolov3.pt)
opt.weights = './runs/train/batch_16_0.004_epoch_50_v5x6/weights/best.pt'
# opt.weights = './custom_weights/best copy.pt'
detect.check_requirements(exclude=('tensorboard', 'thop'))
print_args(FILE.stem, opt)
output_dict = detect.run(**vars(opt), source=base64_string)
#image, bbox, class 확인 (image는 일부만 확인)
print(f"image : {output_dict['image'][0]} bbox : {output_dict['bbox']}, class : {output_dict['class']}")
#Save output image (bbox 그려져있는 image)
output_image = output_dict['image']
output_img_name = filepath.split('/')[-1][:-4]
cv2.imwrite(f'./test_result/{output_img_name}.jpg', output_image)
print('-------------end-------------')