2022. 3. 2. 18:37ㆍ프로젝트/KFood

YOLO란 You Only Look Once라는 약어로, 이미지를 grid system으로 하는 object detection algorithm이다.
grid의 각 cell은 오브젝트를 detect하기 위하여 있다. YOLO의 장점은 매우 빠르고(실시간 동영상에서 가능), 뿐만 아니라 정확한 편에 속한다는 것이다.
YOLO의 역사
YOLOv1 https://arxiv.org/abs/1506.02640
2015년 6월 8일
YOLOv2 https://arxiv.org/abs/1612.08242v1
2016년 12월 25일
YOLOv3 https://arxiv.org/abs/1804.02767v1
2018년 4월 8일
YOLOv4 https://arxiv.org/abs/2004.10934v1 -> 안들어가짐
2020년 4월 23일
YOLOv5 https://github.com/ultralytics/yolov5
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
2020년 5월 18일
------------------------------------------------------------------------------------------------------------------------
YOLO 첫번쨰 논문을 한번 보자(YOLOv1)
You Only Look Once: Unified, Real-Time Object Detection
Abstract
1. Introduction
현재의 detection system은 classfier를 사용한다. 그것으로는 DPM(Deformable Parts Models)나 R-CNN같은 것이 있다.(기존의 classfier). R-CNN은 먼저 bbox를 만들고, 그 다음 classfier를 돌리고, 그 다음 bbox를 후처리하고, 중복된 detection을 제거한 후, box에 대한 점수를 다시 매겨서 detection을 마무리한다.
이런 복잡한 pipeline 과정은 느리고, optimize하기가 힘들다.
그래서 나온 것이 YOLO이다. 이 논문에 따르면 object detection을 하기 위해 위처럼 여러 과정을 거치는 것이 아니라, 이미지 픽셀에서 bbox 좌표와 class prob(확률)을 이용해 단일 회귀 문제(single regression problem)으로 만들었다고 한다. 즉, 이미지를 한번 보고 물체가 어디있는지 예측할 수 있다는 것이다.

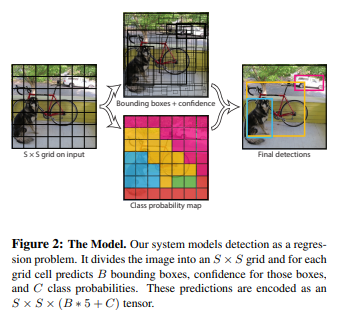
위 Fig1을 참조하여 보면, YOLO는 매우 간단하다. 단일 convolution network는 그려지는 bbox들에 대한 여러개의 bbox와 class prob를 동시에 예측한다. 그래서 통합된 모델(unified)이라고 부른다. 그러므로 여러 과정을 거치는 것보다 훨씬 빠르다.( 1초에 45 frame이 나온다고 하고, Fast YOLO는 더 빠르다고 함)
2. Unified Detection
object detection의 각 구성요소들을 하나의 neural network로 통합했기에 unified detection이라고 부른다. YOLO network는 전체 이미지의 feature를 사용하여 각 bbox를 predict한다.
또한 모든 class에 걸쳐 모든 bbox를 동시에 예측한다. 즉, YOLO의 network가 full image(전체 이미지)와 이미지의 모든 objects에 대한 예측을 처리한다는 말?
YOLO 시스템은 input image를 SxS grid로 나눈다. 만약 물체의 중심(center)이 grid cell에 놓여있다면 그 grid cell에게는 물체를 탐지하는 데 책임을 가한다.
각 grid cell은 B(bbox)와 해당 상자에 대한 신뢰점수(confidence score)를 예측한다. 이러한 신뢰점수는 얼마나 정확하게 box에 object가 포함되어 있냐를 나타내는 점수이다.
confidence 공식은 다음과 같다.
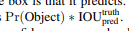
confidence score :
- box안에 아무 object가 없다면 confidence score는 0.
- 그렇지않으면(Otherwise) predict box와 실제값(ground truth)사이의 IOU(Intersection Over Union)으로 준다.
각 bbox는 5개의 predict값이 있다. (x,y,w,h,confidence)
- (x,y) : box의 center 좌표(grid cell의 경계에 상대적인 상자의 중심?)
- w와 h : 전체 영상(image)을 기준으로 예측
- confidence : predict box와 ground truth box사이의 IOU
각 grid cell은 C(conditional class probabilities), Pr(Cls | Obj) 이라는 predict값이 있다.
- 이 확률값들은 grid cell이 object를 포함하고 있는가?에 대한 확률이다.
- 상자 B의 갯수에 관계없이 grid cell 당 class probability 세트 하나만 예측한다.
- 나중에 test를 할 때, conditional class probability와 각 box의 confidence prediction을 곱하여 각 상자에 대한 클래스별 신뢰 점수를 구한다. 이 점수는 상자에 나타나는 class의 확률과 predicted box가 얼마나 잘 맞느냐를 확인한다.
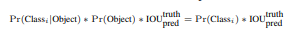
3. Network Design
YOLO의 구조는 GoogleNet의 모델에서 영감을 받아져 짜여졌다. YOLO는 2개의 fully connected layers 뒤에 24개의 convolutional layers가 있다. GoogleNet과는 다르게 3x3 convoluational layer를 쓴 뒤에 1x1 reduction layaer를 사용한다.

Conclusion
YOLO는 object detection을 위한 통합된 모델이다. 이 모델은 full image를 바로 train시킬 수 있다. 기존의 classifier과는 다르게 YOLO는 detection performance에 영향을 미치는 loss function을 바로 도입할 수 있다.
그리고 Fast YOLO는 가장 빠른 범용 목적의 object detecion 모델이다. 따라서 범용적으로 여러 분야(음식,자율주행,미술 등등)에 사용될 수 있다.