2022. 3. 1. 13:34ㆍ프로젝트/KFood
Metrics/Loss 중 더 중요하게 봐야 할 것
Precison, Recall - 실제로 맞췄냐 아니냐
loss - 정답과 예측값 차이를 계산한 것
자율 주행의 경우 loss가 낮아야 하지만 우리의 경우 precision, recall을 더 중요하게 봐야 함.
Threshold를 낮추면 신뢰성은 좀 떨어지지만 detection을 할 수 있음.
val loss
obj_loss가 class 맞추는 것
box_loss가 bbox 맞추는 것
cls_loss가 두 가지 다 보는 것
mAP 간단히
mAP_0.5 → 0.5는 IOU, 0.5 이상인 것
mAP_0.5:0.95 → 0.5 이상인 것, 0.95 이상인 것 각각 구해서 평균을 구하는 것
⇒ 지금은 mAP 0.5만 보면 될 것 같다.
----------------------------------------------------------------------------------------------------------------------------------
남은 공간 보기
df -hGPU 사용량 보기
nvidia-smi
-----------------------------------------------------------------------------------------------------------------------------------
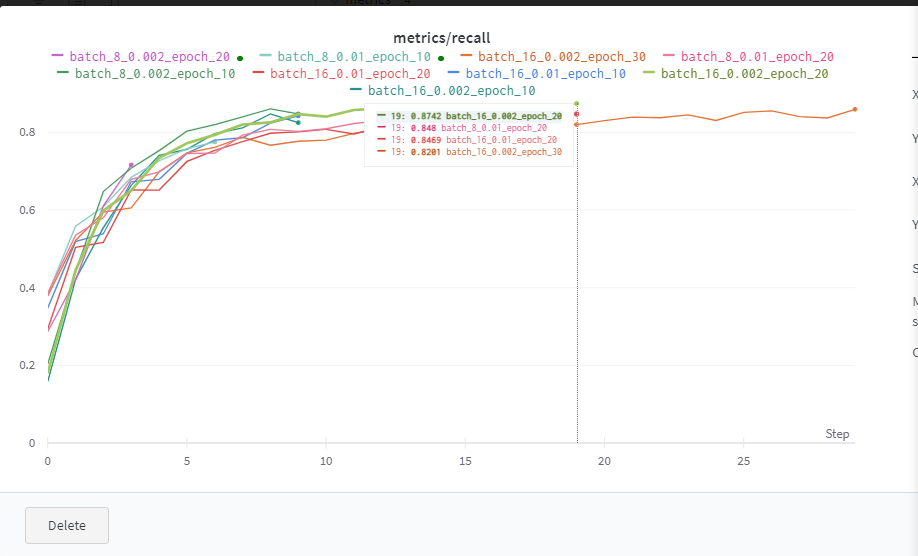
YOLOv3 wandb 결과들(loss, lr, recall, precision, mAP)
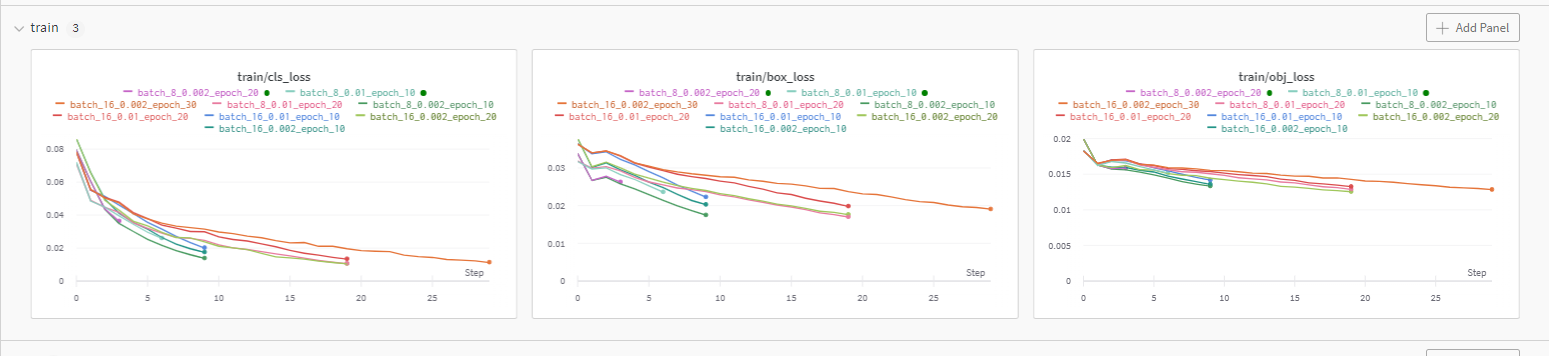
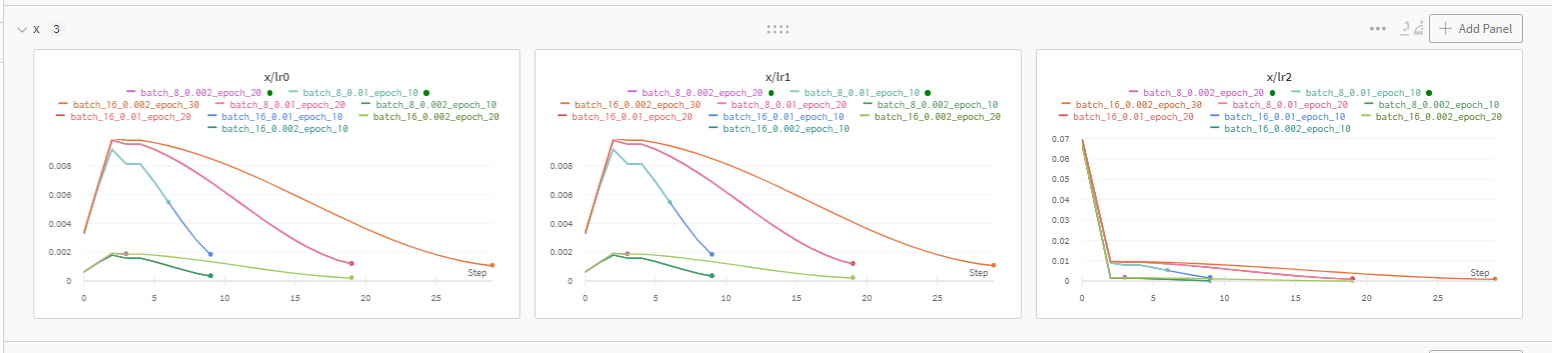

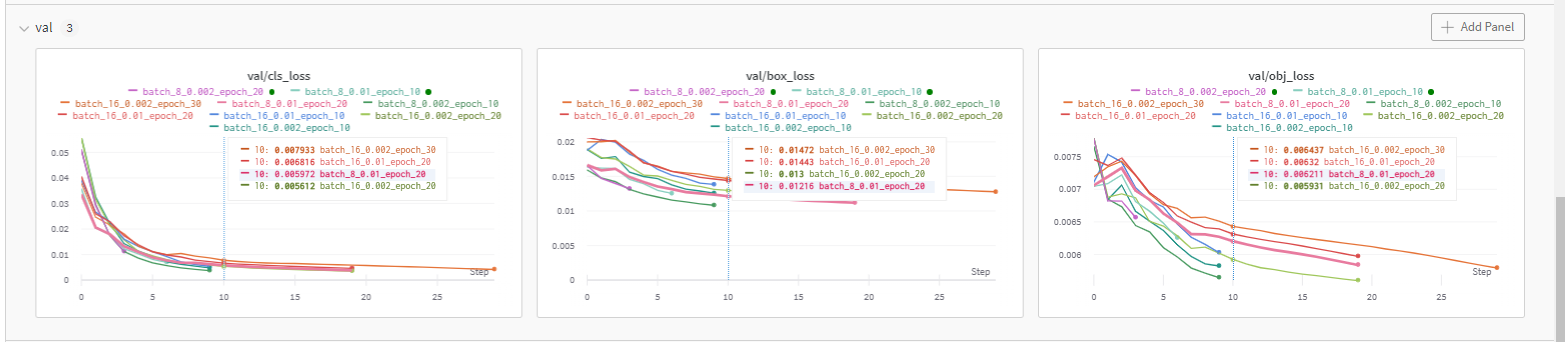
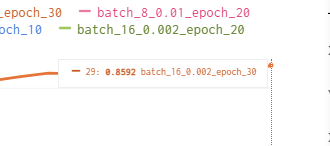
난 여기서 epoch 10이 더 낮고 좋은 성능인 것도 있는 줄 알았는데, 멀리보니까 epoch 30이 더 좋은 경우들이 있었음
대강 추이만 보지말고 좌표랑 smooth도 잘 확인하기 (이런식으로)

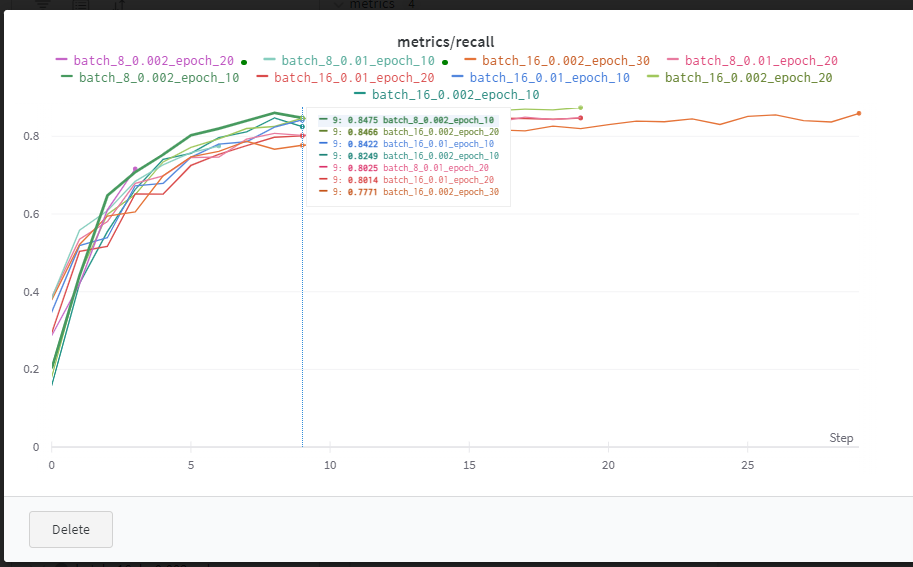
---------------------------------------------------------------------------------------------------------------------------------
YOLO v5 -> yolov3가 inference가 별로 개선되고 있는 것 같지 않아서 yolov5로 training 해보자는 얘기가 나왔음.
yolo v5는 v5 nano, small, medium, large, xlarge가 있고, 커질수록 용량과 inference time?이 증가하는 대신 정확도(mAP)가 향상한다. 저 뒤에 붙은 6은 더 최신버전?이라는 뜻인 것 같았다.


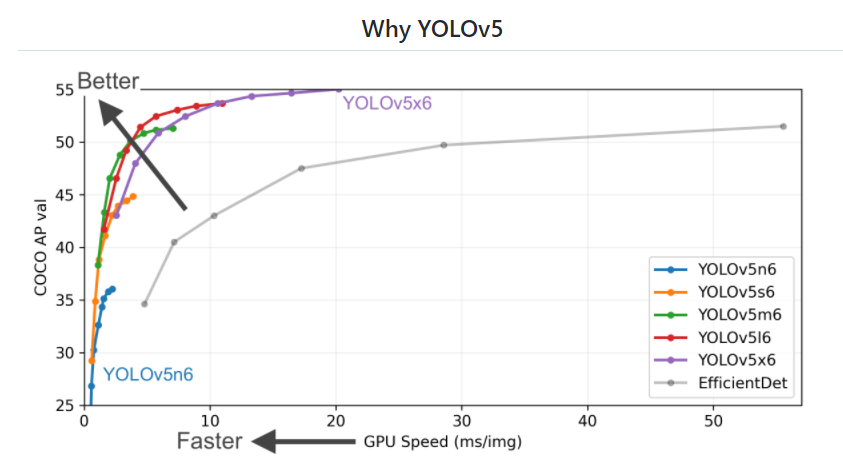

https://docs.ultralytics.com/ -> 원작자님 사이트
YOLOv5 Documentation
Introduction To get started right now check out the Quick Start Guide What is YOLOv5 YOLO an acronym for 'You only look once', is an object detection algorithm that divides images into a grid system. Each cell in the grid is responsible for detecting objec
docs.ultralytics.com
---------------------------------------------------------------------------------------------------------------------------------
YOLOv5로 갈아끼워서 학습시키기 -> YOLOv5 GitHub에서 해야 된다. 다음포스팅 참고.
1. 선정한 모델 다운로드하기
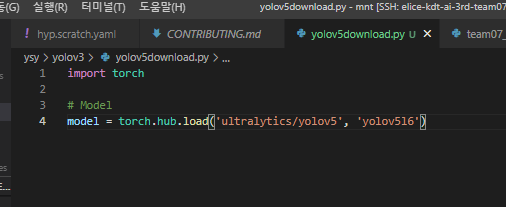
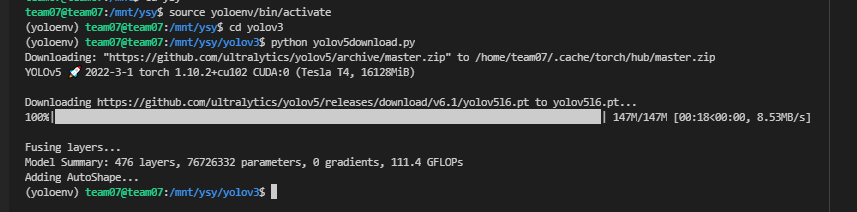

2. 코드 실행
- lr 0.002 epochs 10 , batch 8 (batch 16보다 더 정교,그러나 오래걸림) weights yolov5l6.pt
- lr을 0.002로 하는 이유는 0.01보다 더 좋은 성능이 나왔기 때문! (우리 데이터셋을 사용하면 COCO 데이터셋을 학습시킬 때보다 global minimum loss function을 찾아갈 때 보폭을 조금 더 작게)
python train.py --img 640 --batch 8 --epochs 10 --data kfood.yaml --weights yolov5l6.pt --name batch_8_0.002_epoch_5_v5l6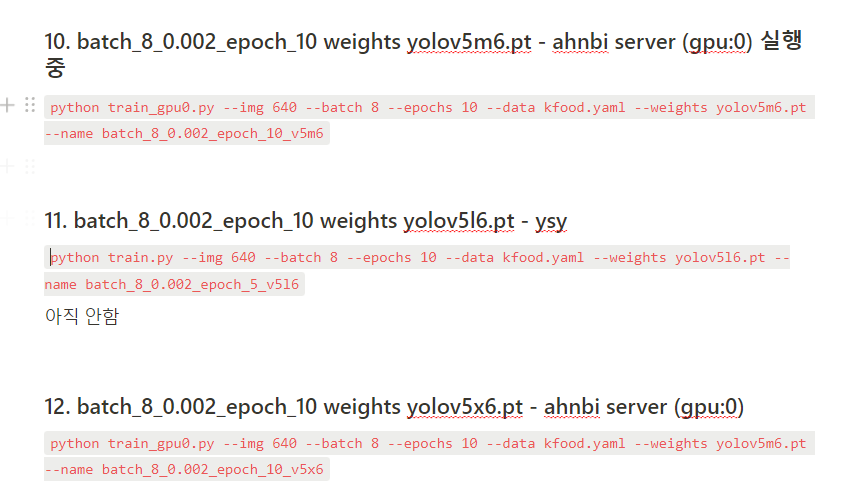



---------------------------------------------------------------------------------------------------------------------------------
Recall(metrics/mAP_0.5)
| batch 16, lr=0.01 | batch 16, lr=0.002 | batch 8, lr=0.01 | batch 8, lr=0.002 | |
| yolov3 epochs=10 |
r : 0.8422 m : 0.8164 |
r : 0.8249 m : 0.8228 |
r : 0.8475 m : 0.8328 |
|
| yolov3 epochs=20 |
r : 0.8469 m : 0.8294 |
r : 0.8742 m : 0.8382 |
r : 0.848 m : 0.8333 |
r : 0.8703 m : 0.856 |
| yolov3 epochs=30 |
r : 0.8592 m : 0.8421 |
|||
| yolov5x6 epochs=20 |
Precision(val/cls_loss)
| batch 16, lr = 0.01 | batch 16, lr = 0.002 | batch 8, lr = 0.01 | batch 8, lr = 0.002 | |
| yolov3 epochs = 10 |
0.005606 | 0.004957 | X | 0.003889 |
| yolov3 epochs = 20 |
0.004772 | 0.003695 | 0.003997 | 0.002719 |
| yolov3 epochs = 30 |
0.004433 | |||
| yolov5x6 epochs = 20 |

YOLOv3에서는 lr 0.002가 epoch 20 , batch 8,16에서 모두 좋은 결과를 나타냈으나 실제 inference를 해보면 그렇게 잘 잡지는 못하는 상황이었다. 따라서 YOLOv5로 모델을 변경해 training 을 진행해보자.