2022. 2. 26. 20:02ㆍ프로젝트/KFood
일단 전이학습 할 weights : yolov3.pt <- ImageNet이라는 어마어마한 대용량 빅데이터셋으로 사람,차,의자 등등을 detection training해놓은 모델
우리의 데이터셋 : 음식분류데이터셋(직접 만듦) train : test : val = 65000:8000:8000 정도 됨.
epoch : 5 (0~4 epoch)
batch_size : 16 (8의 배수로 해야되고, GPU memory?가 딸린다면 더 늘릴 수 없다)
따라서 yolov3를 처음 train시킬 때의 lr값인 0.01에서 1/10으로 줄여보기로 함(데이터셋 개수도 적으니 보폭도 줄인다.)
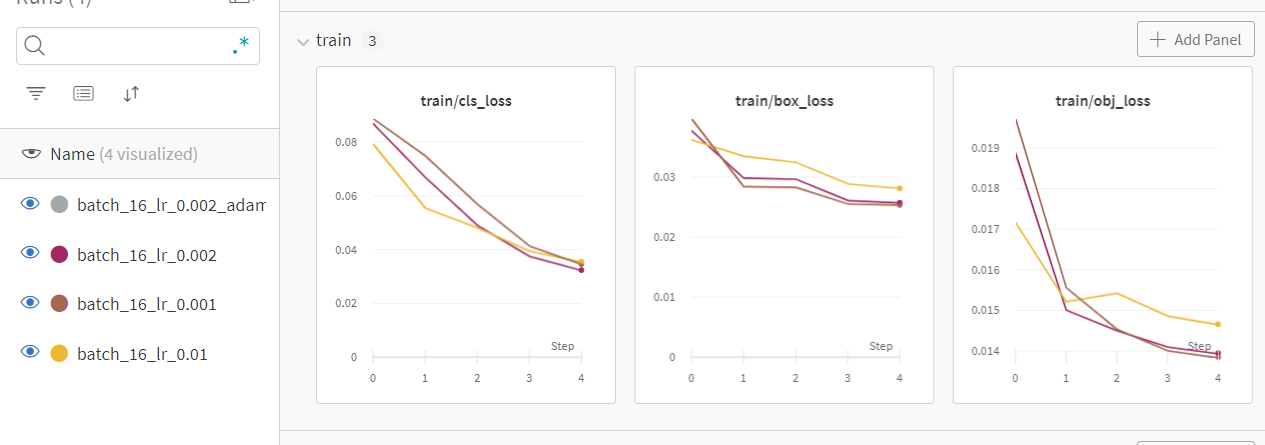

recall 이 높은 것은 lr이 0.002일 때이다.(자주색)

우리는 recall(검출률)이 더 중요하므로 box loss와 obj loss를 중점적으로 보면 val(답을 모르는 이미지들에 대한 detect) 에서는 lr이 0.002인 경우가 제일 loss가 낮아서 좋았다.(자주색)
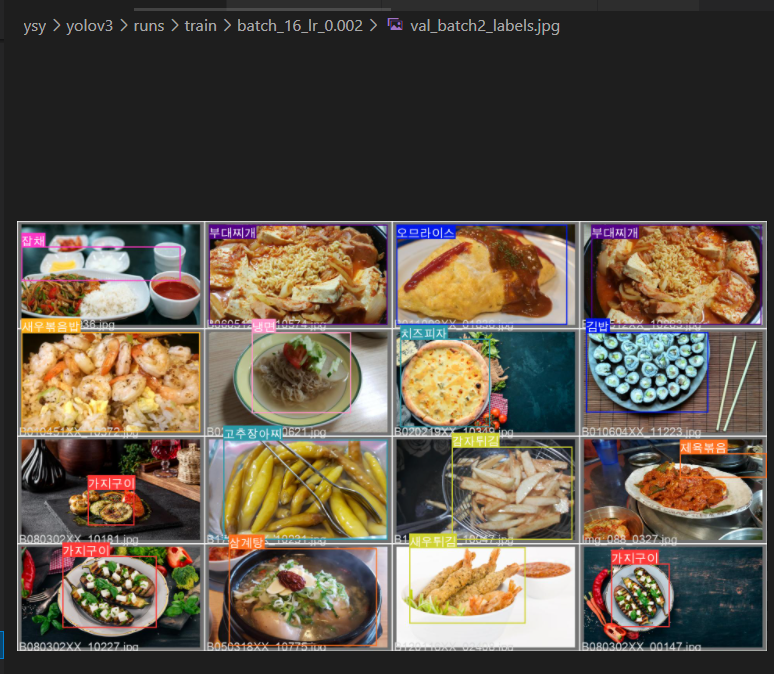

그리고 lr_0.002일 떄의 모델로 inference도 한번 진행해 봤다.
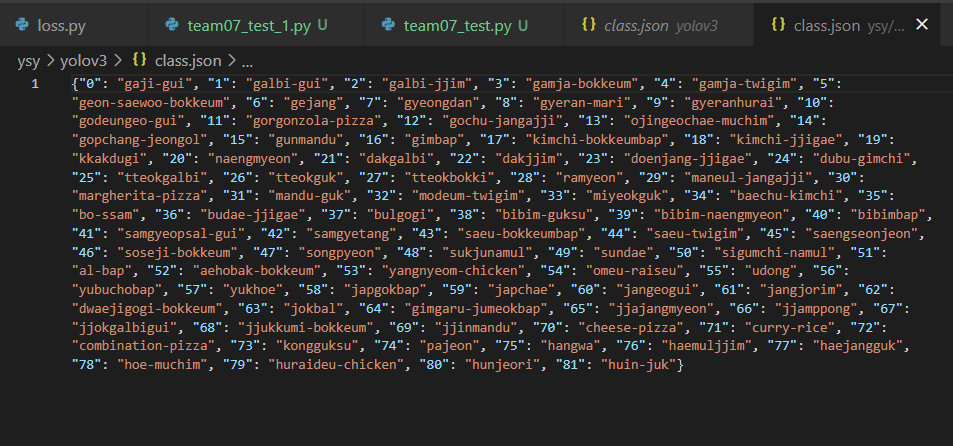
못 본 사이에 class.json이 생겼다.

class_list의 출력을 위한 class.json 파일인 것 같다
그럼 이제 inference 코드 실행(원래는 python detect.py --weights 원하는모델 인데 우리는 이렇게 수정했다)
python team_07_test.py --weights 원하는모델 # 여기서는 best_lr_0.002.pt
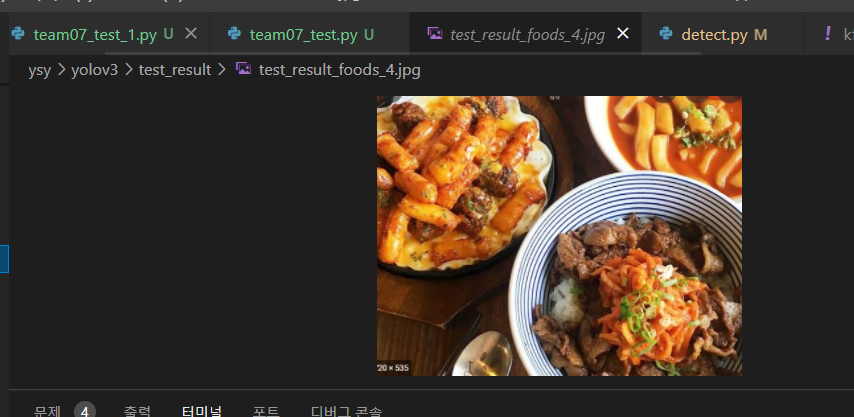
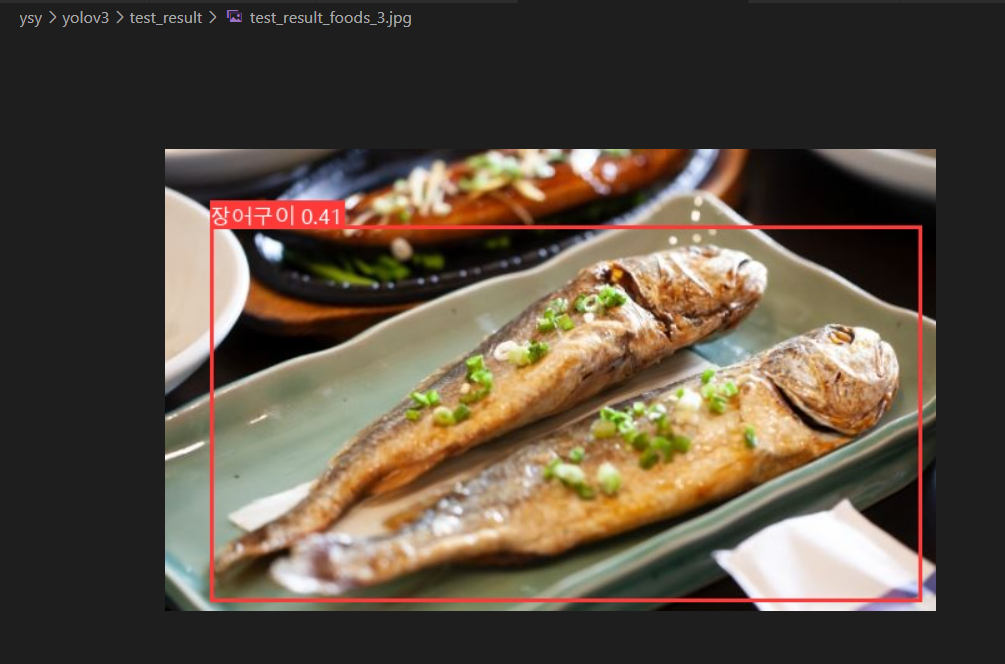
lr이 0.002로 학습된 모델도 역시나 음식이 여러개 있는 건 잡지 못했다.
이번엔 한개인 음식
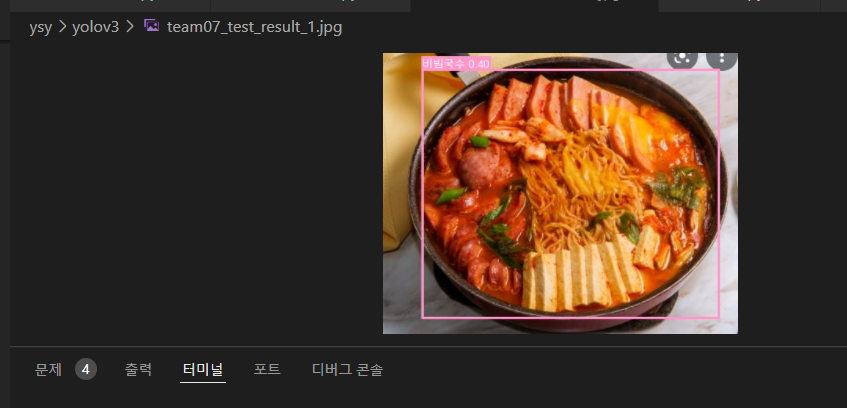

엥..!! 잘 잡던 애도 못잡아졌다..
+ 엥.. 다시 실행해보니 잘 된다. VM이 귀신들린 것 같다 ㅋㅋ


-----------------------------------------------------------------------------------------------------------------------------------
따라서 lr은 0.002로 고정시키고 이번엔 다른 요소를 바꿔보기로 했다.
1. optimizer (default = SGD) -> adam
2. epochs = 5 -> epochs = 10
1번쨰 방법은 지금 tmux에서 돌아가고 있고!

python train.py --img 640 --batch 16 --epochs 5 --data kfood.yaml --weights yolov3.pt --name batch_16_lr_0.002_adam --adam
2번째 방법은 우리 VM이 GPU가 1개밖에 없어서 수현님 연구실네 컴퓨터에서 돌려보기로 했다.
이 결과는 다음 포스팅에 작성하겠다!
++
코치님 말씀 : lr 0.002는 상승곡선이 좀 느리다.. smoothing
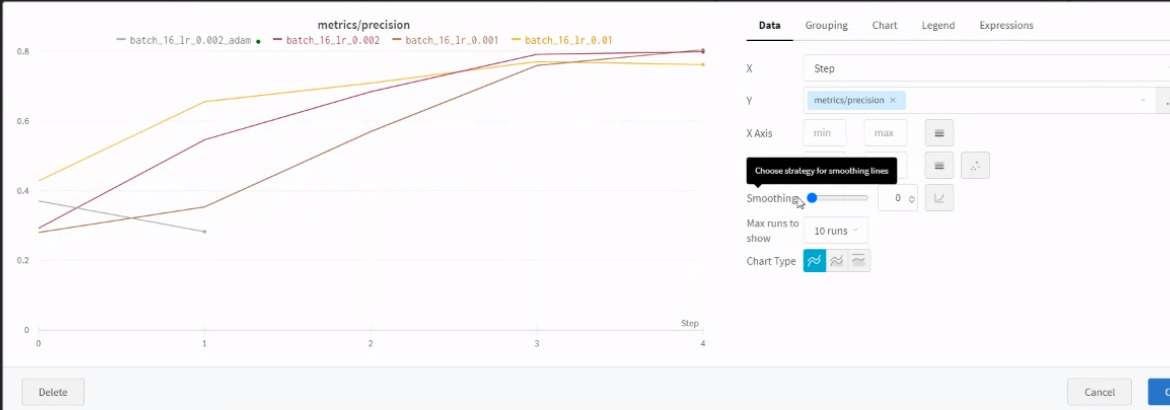
따라서 lr은 0.001, 0.01로 고정시키고 이번엔 다른 요소를 바꿔보기로 했다.
1. optimizer (default = SGD) -> adam
2. epochs = 5 -> epochs = 10
3. batch_size = 16 -> 8 더 낮춰보자
우리는 loss(0.8~0.6 오차)를 보는 것도 중요하지만, 일단은 음식을 몇 개 맞추느냐가 중요하므로
loss보다는 precision, recall을 보는 게 더 좋다.
그리고 있었던 문제점 : 음식 여러개는 못 잡았던 경우

해결 1 . 일단 학습을 더 오래 해본다.(epoch을 늘리고, 여러 fitting을 해보기) -> 학습이 많이 되면 틀릴지언정 많이 잡아낸다. 아예 bbox가 안잡히는 건 학습이 덜 된 것이다!
해결 2 . 정 안되면 threshold를 0.2~정도로 낮추자.
+ 전이학습 (pretrained) 과
처음에 하이퍼 파라미터를 찾을 떄는 : yolov3.pt를 사용
5epoch부터만 하이퍼파라미터를 바꿔주면 최적을 찾아갈 수 있을 거 같아 : best.pt 사용 -> 6epoch부터 이어서 학습

conf_thres : 클래스를 맞추는 거(김치볶음밥이냐 오뎅국이냐) 0.25이상이면 OK (obj_loss)
iou_thres : 이 bbox 안에 음식이 있는지 없는지 0.45 이상이면 OK (bbox_loss)
-> 이건 inference할 때 설정하는 것도 괜찮다.
cls_loss = obj_loss , bbox_loss를 모두 맞힌 경우?
+mAP 0.5 0.5:0.95
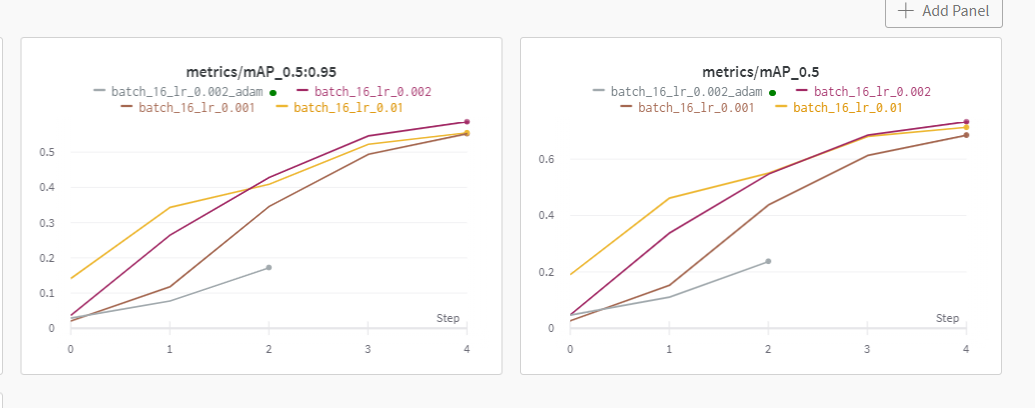
mAP 0.5 : bbox 중에서 50%이상 정답인 것만
mAP 0.5:0.95 : bbox 중에서 50%이상 정답인 것과 95% 이상 정답인 것의 평균
++ 내일 할 것 정리

wandb로 핸드폰으로도 들어가보기