2022. 1. 16. 17:41ㆍ작업/머신러닝
1. 학습 속도 문제 ( 최적화 알고리즘 ) - 전체 학습 데이터셋을 사용해 손실함수를 계산하기 떄문에 계산량이 너무 많아짐 -> 부분데이터만 활용해서 손실함수를 계산하자(SGD)

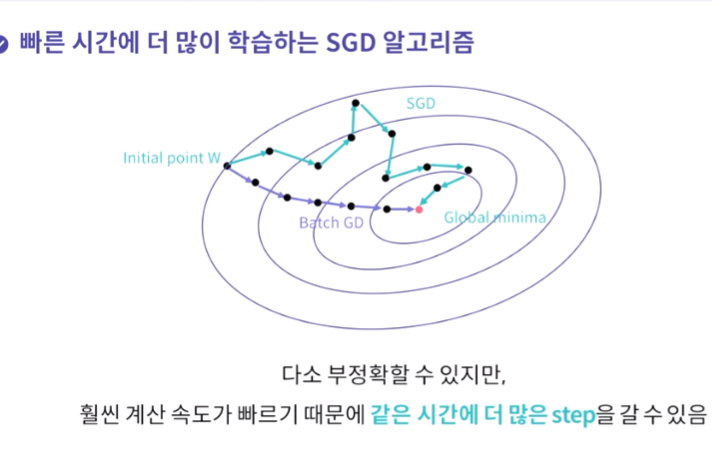
그러나 SGD도 한계가 있긴 하다.
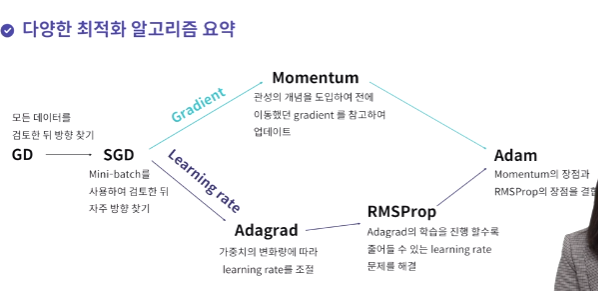
그래서 최적화 알고리즘이 GD -> SGD, momentum, adagrad, RMSProp, adam 등 여러 알고리즘들이 등장했다.
momentum : 과거에 이동했던 방식을 기억하면서 그 방향으로 일정 정도를 추가적으로 이동하는 방식
adagrad : 많이 변화하지 않은 변수는 learning rate를 크게하고, 많이 변화한 변수들은 leargnin rate를 작게 하는 것
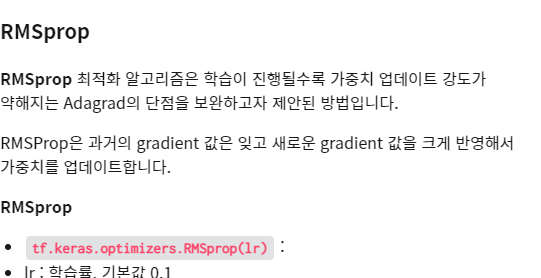
RMSProp : 기억을 하긴 하는데 과거의 기울기는 잊고 최근 기울기 정보를 크게 반영
adam : 가장 최근의 알고리즘.
verbose

import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. GD를 적용할 모델을 자유롭게 생성합니다.
'''
def GD_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, input_shape=(word_num,), activation = 'relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return model
'''
2. SGD를 적용할 모델을 GD를 적용할 모델과 똑같이 생성합니다.
'''
def SGD_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, input_shape=(word_num,), activation = 'relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return model
'''
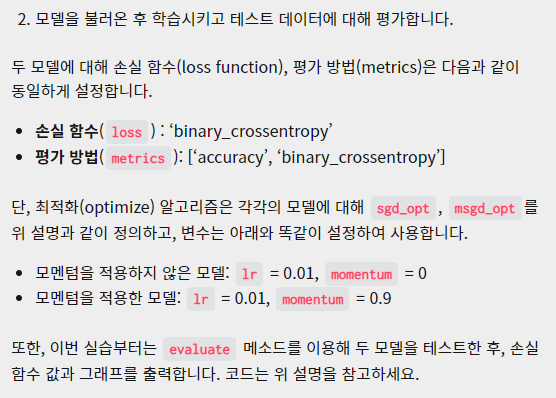
3. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. GD 함수와 SGD 함수를 이용해
두 모델을 불러옵니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 각각 학습시킵니다.
검증용 데이터도 설정해주세요.
'epochs'는 20으로 설정합니다.
GD를 적용할 경우 학습 시
전체 데이터 셋(full-batch)을
사용하므로 'batch_size'를
전체 데이터 개수로 설정합니다.
SGD를 적용할 경우 학습 시
미니 배치(mini-batch)를 사용하므로
'batch_size'를 전체 데이터 개수보다
작은 수로 설정합니다.
여기선 500으로 설정하겠습니다.
Step05. 학습된 두 모델을 테스트하고
binary crossentropy 값을 출력합니다.
둘 중 어느 모델의 성능이 더 좋은지 확인해보세요.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
gd_model = GD_model(word_num) # GD를 사용할 모델입니다.
sgd_model = SGD_model(word_num) # SGD를 사용할 모델입니다.
gd_model.compile(loss = 'binary_crossentropy', optimizer = 'sgd',
metrics = ['accuracy', 'binary_crossentropy'])
sgd_model.compile(loss = 'binary_crossentropy', optimizer = 'sgd',
metrics = ['accuracy', 'binary_crossentropy'])
gd_model.summary()
sgd_model.summary()
gd_history = gd_model.fit(train_data, train_labels, epochs=20, batch_size = data_num, validation_data = (test_data, test_labels), verbose = 0)
print('\n')
sgd_history = sgd_model.fit(train_data, train_labels, epochs=20, batch_size = 500, validation_data = (test_data, test_labels), verbose = 0)
scores_gd = gd_history.history['val_binary_crossentropy'][-1]
scores_sgd = sgd_history.history['val_binary_crossentropy'][-1]
print('\nscores_gd: ', scores_gd)
print('scores_sgd: ', scores_sgd)
Visulaize([('GD', gd_history),('SGD', sgd_history)])
return gd_history, sgd_history
if __name__ == "__main__":
main()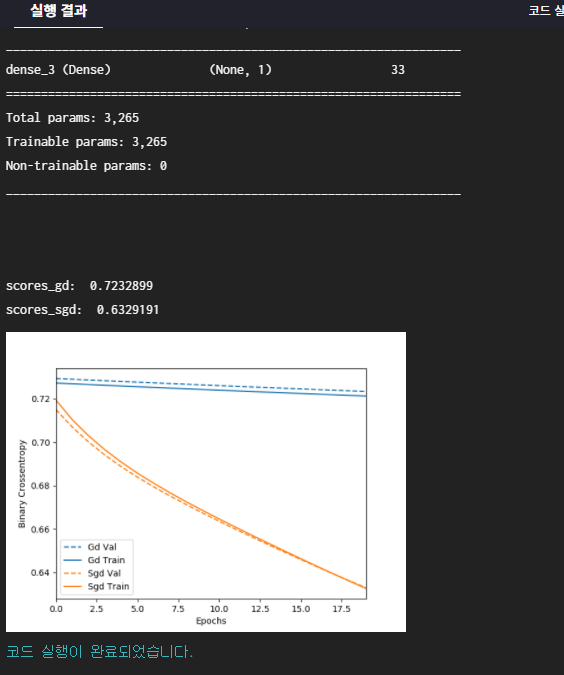

import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 모멘텀(momentum)을 적용/비적용 할 하나의 모델을 자유롭게 생성합니다.
'''
def Momentum_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(32,input_shape = (word_num,), activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return model
'''
2. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. Momentum_model 함수를 이용해
두 모델을 불러옵니다. 모두 동일한 모델입니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 각각 학습시킵니다.
검증용 데이터도 설정해주세요.
두 모델 모두 'epochs'는 20, 'batch_size'는
500으로 설정합니다.
Step05. 학습된 두 모델을 테스트하고
binary crossentropy 값을 출력합니다.
둘 중 어느 모델의 성능이 더 좋은지 확인해보세요.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
sgd_model = Momentum_model(word_num) # 모멘텀을 사용하지 않을 모델입니다.
msgd_model = Momentum_model(word_num) # 모멘텀을 사용할 모델입니다.
sgd_opt = tf.keras.optimizers.SGD(lr=0.1, momentum=0)
sgd_model.compile(loss = 'binary_crossentropy',
optimizer=sgd_opt,
metrics=['accuracy','binary_crossentropy'])
msgd_opt = tf.keras.optimizers.SGD(lr=0.01, momentum=0.5)
msgd_model.compile(loss = 'binary_crossentropy',
optimizer=msgd_opt,
metrics=['accuracy','binary_crossentropy'])
sgd_model.summary()
msgd_model.summary()
sgd_history = sgd_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
msgd_history = sgd_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
scores_sgd = sgd_model.evaluate(test_data,test_labels)
scores_msgd = msgd_model.evaluate(test_data,test_labels)
print('\nscores_sgd: ', scores_sgd[-1])
print('scores_msgd: ', scores_msgd[-1])
Visulaize([('SGD', sgd_history),('mSGD', msgd_history)])
return sgd_history, msgd_history
if __name__ == "__main__":
main()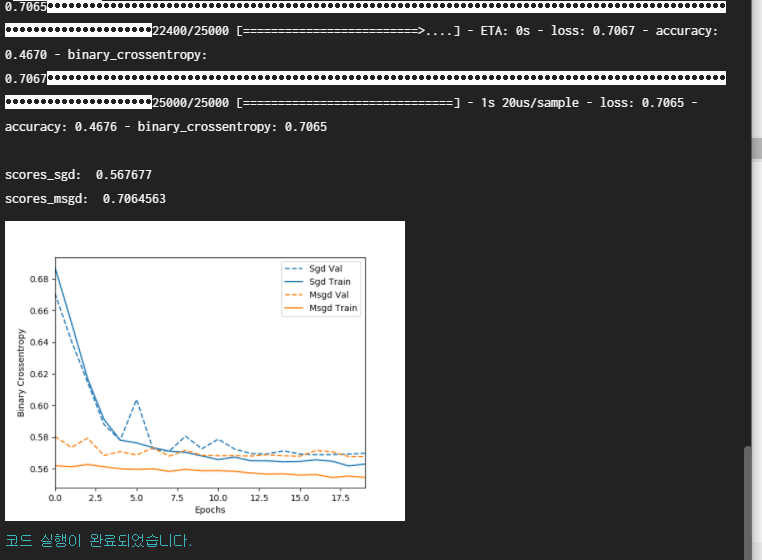


import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. Adagrad, RMSprop, Adam 최적화 알고리즘을 적용할 하나의 모델을 자유롭게 생성합니다.
'''
def OPT_model(word_num):
model = tf.keras.Sequential([
tf.keras.layers.Dense(32,input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
return model
'''
2. 세 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. OPT_model 함수를 이용해 세 모델을 불러옵니다.
모두 동일한 모델입니다.
Step02. 세 모델의 손실 함수, 최적화 방법,
평가 방법을 설정합니다.
Step03. 세 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 세 모델을 각각 학습시킵니다.
세 모델 모두 'epochs'는 20, 'batch_size'는
500으로 설정합니다.
Step05. 세 모델을 테스트하고
binary crossentropy 점수를 출력합니다.
셋 중 어느 모델의 성능이 가장 좋은지 확인해보세요.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
adagrad_model = OPT_model(word_num) # Adagrad를 사용할 모델입니다.
rmsprop_model = OPT_model(word_num) # RMSProp을 사용할 모델입니다.
adam_model = OPT_model(word_num) # Adam을 사용할 모델입니다.
adagrad_opt = tf.keras.optimizers.Adagrad(lr=0.01, epsilon=0.00001, decay=0.4)
adagrad_model.compile(loss='binary_crossentropy',
optimizer=adagrad_opt,
metrics=['accuracy','binary_crossentropy'])
rmsprop_opt = tf.keras.optimizers.RMSprop(lr=0.001)
rmsprop_model.compile(loss='binary_crossentropy',
optimizer=rmsprop_opt,
metrics=['accuracy','binary_crossentropy'])
adam_opt = tf.keras.optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999)
adam_model.compile(loss='binary_crossentropy',
optimizer=adam_opt,
metrics=['accuracy','binary_crossentropy'])
adagrad_model.summary()
rmsprop_model.summary()
adam_model.summary()
adagrad_history = adagrad_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
rmsprop_history =rmsprop_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
adam_history = adam_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
scores_adagrad = adagrad_model.evaluate(test_data, test_labels, verbose=0)
scores_rmsprop = rmsprop_model.evaluate(test_data, test_labels, verbose=0)
scores_adam = adam_model.evaluate(test_data, test_labels, verbose=0)
print('\nscores_adagrad: ', scores_adagrad[-1])
print('scores_rmsprop: ', scores_rmsprop[-1])
print('scores_adam: ', scores_adam[-1])
Visulaize([('Adagrad', adagrad_history),('RMSprop', rmsprop_history),('Adam', adam_history)])
return adagrad_history, rmsprop_history, adam_history
if __name__ == "__main__":
main()
2. 기울기 소실 문제
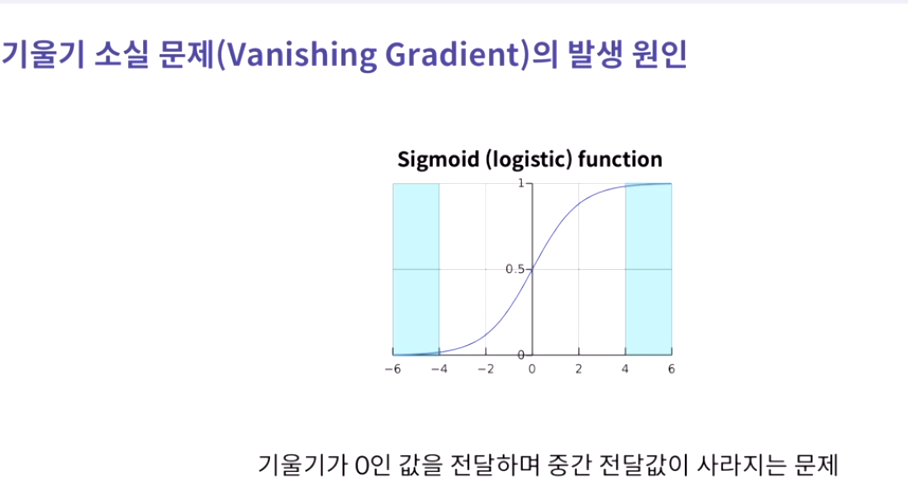
-> hidden layer에 활성화 함수를 ReLU 함수를 사용해서 해결

import tensorflow as tf
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
'''
1. 활성화 함수는 출력층만 그대로 두고
나머지 히든층들은 `relu`로 설정하세요.
'''
def make_model_relu():
model_relu = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(32,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model_relu
'''
2. 활성화 함수는 출력층만 그대로 두고
나머지 히든층들은 `sigmoid`로 설정하세요.
'''
def make_model_sig():
model_sig = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(64,activation='sigmoid'),
tf.keras.layers.Dense(32,activation='sigmoid'),
tf.keras.layers.Dense(32,activation='sigmoid'),
tf.keras.layers.Dense(32,activation='sigmoid'),
tf.keras.layers.Dense(32,activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model_sig
'''
3. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. model_relu와 model_sig 불러옵니다.
Step02. 두 모델의 최적화 방법과 손실 함수를
똑같이 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
우리가 만든 모델이 얼마나 깊은지 확인해보세요.
Step04. 두 모델을 학습시킵니다.
'epochs'는 5로 설정합니다.
검증용 데이터는 설정하지 않습니다.
'verbose'는 0으로 설정합니다.
Step05. 두 모델을 테스트하고 점수를 출력합니다.
둘 중 어느 모델의 성능이 더 좋은지 확인해보세요.
'''
def main():
# MNIST 데이터를 불러오고 전처리합니다.
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model_relu = make_model_relu() # 히든층들의 활성화 함수로 relu를 쓰는 모델입니다.
model_sig = make_model_sig() # 히든층들의 활성화 함수로 sigmoid를 쓰는 모델입니다.
model_relu.compile(loss = 'sparse_categorical_crossentropy',
optimizer= 'adam', metrics=['accuracy'])
model_sig.compile(loss = 'sparse_categorical_crossentropy',
optimizer= 'adam', metrics=['accuracy'])
model_relu.summary()
model_sig.summary()
model_relu_history = model_relu.fit(x_train, y_train, epochs=5, batch_size=500, verbose = 0)
print('\n')
model_sig_history = model_sig.fit(x_train, y_train, epochs=5, batch_size=500, verbose = 0)
scores_relu = model_relu.evaluate(x_test, y_test, verbose = 0)
scores_sig = model_sig.evaluate(x_test, y_test, verbose = 0)
print('\naccuracy_relu: ', scores_relu[-1])
print('accuracy_sig: ', scores_sig[-1])
return model_relu_history, model_sig_history
if __name__ == "__main__":
main()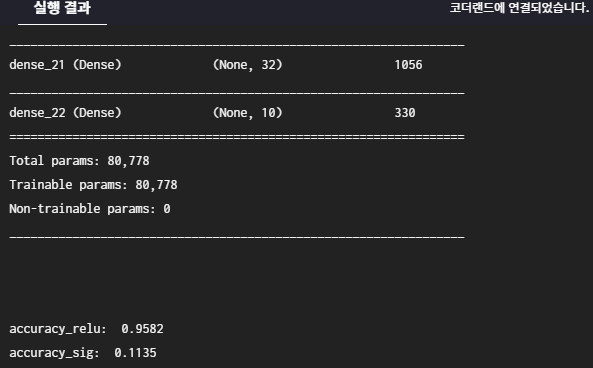
활성화함수 다르게 적용하기
import tensorflow as tf
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
'''
1. 활성화 함수는 출력층만 그대로 두고
나머지 히든층들은 'sigmoid'로 설정하세요.
'''
def make_model_sig():
model_sig = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(64, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model_sig
'''
2. 활성화 함수는 출력층만 그대로 두고
나머지 히든층들은 'relu'로 설정하세요.
'''
def make_model_relu():
model_relu = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model_relu
'''
3. 활성화 함수는 출력층만 그대로 두고
나머지 히든층들은 'tanh'로 설정하세요.
'''
def make_model_tanh():
model_tanh = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model_tanh
'''
4. 세 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. make_model_sig, make_model_relu, make_model_tanh 함수를 이용해 세 모델을 불러옵니다.
Step02. 세 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 세 모델의 구조를 확인하는 코드를 작성합니다.
우리가 만든 모델이 얼마나 깊은지 확인해보세요.
Step04. 세 모델을 학습시킵니다.
'epochs'는 5로 설정합니다.
검증용 데이터는 설정하지 않습니다.
Step05. 세 모델을 테스트하고 accuracy 값을 출력합니다.
셋 중 어느 모델의 성능이 가장 좋은지 확인해보세요.
'''
def main():
# MNIST 데이터를 불러오고 전처리합니다.
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model_sig = make_model_sig() # 히든층들의 활성화 함수로 sigmoid를 쓰는 모델입니다.
model_relu = make_model_relu() # 히든층들의 활성화 함수로 relu를 쓰는 모델입니다.
model_tanh = make_model_tanh() # 히든층들의 활성화 함수로 tanh를 쓰는 모델입니다.
model_sig.compile(loss = 'sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_relu.compile(loss = 'sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_tanh.compile(loss = 'sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model_sig.summary()
model_relu. summary()
model_tanh.summary()
model_sig_history = model_sig.fit(x_train, y_train, epochs=5, batch_size = 500, verbose=0)
print('\n')
model_relu_history = model_relu.fit(x_train, y_train, epochs=5, batch_size = 500, verbose=0)
print('\n')
model_tanh_history = model_tanh.fit(x_train, y_train, epochs=5, batch_size = 500, verbose=0)
scores_sig = model_sig.evaluate(x_test,y_test, verbose=0)
scores_relu = model_relu.evaluate(x_test,y_test, verbose=0)
scores_tanh = model_tanh.evaluate(x_test,y_test, verbose=0)
print('\naccuracy_sig: ', scores_sig[-1])
print('accuracy_relu: ', scores_relu[-1])
print('accuracy_tanh: ', scores_tanh[-1])
return model_sig_history, model_relu_history, model_tanh_history
if __name__ == "__main__":
main()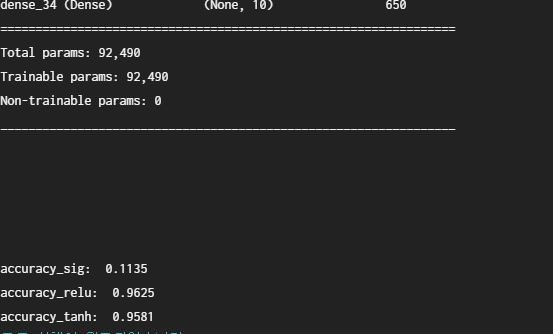
3. 초기값 설정 문제




import numpy as np
from visual import *
np.random.seed(100)
def sigmoid(x):
result = 1 / (1 + np.exp(-x))
return result
'''
1. 입력 데이터를 정의하세요.
2. 가중치를 정의하세요.
3. sigmoid를 통과할 값인 'a_1', 'a_2'를 정의하세요.
'''
def main():
x_1 = np.random.randn(1000,100)
x_2 = np.random.randn(1000,100)
node_num = 100
hidden_layer_size = 5
activations_1 = {}
activations_2 = {}
for i in range(hidden_layer_size):
if i != 0:
x_1 = activations_1[i-1]
x_2 = activations_2[i-1]
w_1 = np.random.randn(100,100)
w_2 = np.random.randn(100,100)*0.01
a_1 = np.dot(x_1, w_1)
a_2 = np.dot(x_2, w_2)
z_1 = sigmoid(a_1)
z_2 = sigmoid(a_2)
activations_1[i] = z_1
activations_2[i] = z_2
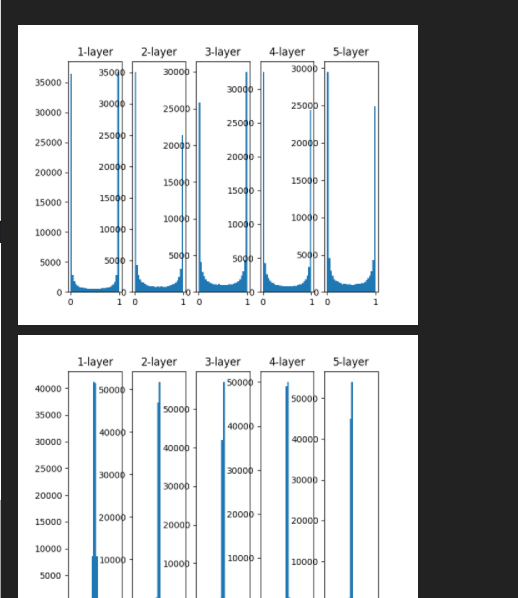
Visual(activations_1,activations_2)
return activations_1, activations_2
if __name__ == "__main__":
main()시각화된 활성화 결괏값들의 분포를 확인해보세요. 값들이 골고루 퍼져있나요? 아니면 어느 한 쪽으로 몰려있나요? 한 쪽으로 몰려있다면 학습 시 어떤 문제가 발생할까요?

import numpy as np
from visual import *
np.random.seed(100)
def sigmoid(x):
result = 1 / (1 + np.exp(-x))
return result
def relu(x):
result = np.maximum(0,x)
return result
'''
1. 입력 데이터를 정의하세요.
2. 가중치 초깃값 설정 부분을 왼쪽 설명에 맞게 바꿔보세요.
Numpy의 연산 메서드를 사용할 수 있습니다.
3. sigmoid와 relu를 통과할 값인 'a_sig', 'a_relu'를 정의하세요.
'''
def main():
x_sig = np.random.randn(1000,100)
x_relu = np.random.randn(1000,100)
node_num = 100
hidden_layer_size = 5
activations_sig = {}
activations_relu = {}
for i in range(hidden_layer_size):
if i != 0:
x_sig = activations_sig[i-1]
x_relu = activations_relu[i-1]
w_sig = np.random.randn(100,100) * (1/np.sqrt(node_num))
w_relu = np.random.randn(100,100) * (1/np.sqrt(node_num))
a_sig = np.dot(x_sig, w_sig)
a_relu = np.dot(x_relu, w_relu)
z_sig = sigmoid(a_sig)
z_relu = relu(a_relu)
activations_sig[i] = z_sig
activations_relu[i] = z_relu
Visual(activations_sig, activations_relu)
return activations_sig, activations_relu
if __name__ == "__main__":
main()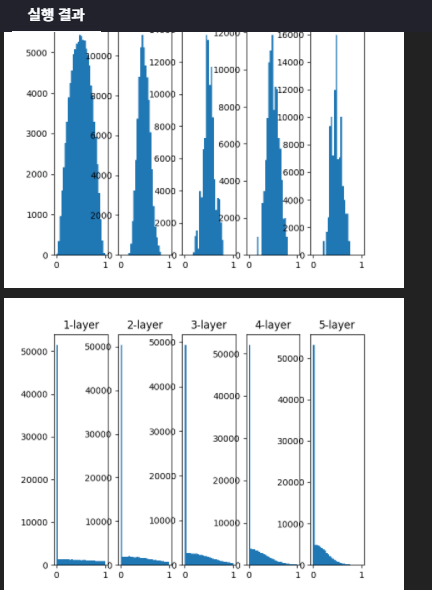

import numpy as np
from visual import *
np.random.seed(100)
def relu(x):
result = np.maximum(0,x)
return result
'''
1. 입력 데이터를 정의하세요.
2. 가중치 초깃값 설정 부분을 왼쪽 설명에 맞게 바꿔보세요.
Numpy의 연산 메서드를 사용할 수 있습니다.
3. relu를 통과할 값인 'a_relu'를 정의하세요.
'''
def main():
x_relu = np.random.randn(1000,100)
node_num = 100
hidden_layer_size = 5
activations_relu = {}
for i in range(hidden_layer_size):
if i != 0:
x_relu = activations_relu[i-1]
w_relu = np.random.randn(100,100) * np.sqrt(2/node_num)
a_relu = np.dot(x_relu, w_relu)
z_relu = relu(a_relu)
activations_relu[i] = z_relu
Visual(activations_relu)
return activations_relu
if __name__ == "__main__":
main()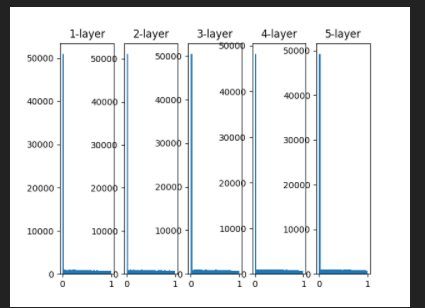
4. overfitting 문제
과적화(overfitting) 해결 방안
- 정규화
- 드롭아웃
- 배치 정규화

과적합
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 과적합 될 모델과 비교하기 위해 기본 모델을
마크다운 설명과 동일하게 생성합니다.
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([ tf.keras.layers.Dense(256, activation = 'relu', input_shape=(word_num,)), tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return basic_model
'''
2. 기본 모델의 레이어 수와 노드 수를 자유롭게 늘려서
과적합 될 모델을 생성합니다.
'''
def Overfitting(word_num):
overfit_model = tf.keras.Sequential([
tf.keras.layers.Dense(1024, activation = 'relu', input_shape=(word_num,)),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return overfit_model
'''
3. 두 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. basic_model와 overfit_model 함수를 이용해
두 모델을 불러옵니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 학습시킵니다.
검증용 데이터도 설정해주세요.
기본 모델은 'epochs'를 20,
과적합 모델은 'epochs'를 300이상으로 설정합니다.
'batch_size'는 두 모델 모두 500으로 설정합니다.
Step05. 두 모델을 테스트하고
binary crossentropy 값을 출력합니다.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델입니다.
overfit_model = Overfitting(word_num) # 과적합시킬 모델입니다.
basic_model.compile(loss = 'binary_crossentropy', optimizer = 'adam',
metrics = ['accuracy','binary_crossentropy'])
overfit_model.compile(loss = 'binary_crossentropy', optimizer = 'adam',
metrics = ['accuracy','binary_crossentropy'])
basic_model.summary()
overfit_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size=500,validation_data=(test_data, test_labels), verbose=0)
print('\n')
overfit_history = overfit_model.fit(train_data, train_labels, epochs=300, batch_size=500,validation_data=(test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose = 0)
scores_overfit = overfit_model.evaluate(test_data, test_labels, verbose = 0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_overfit: ', scores_overfit[-1])
Visualize([('Basic', basic_history),('Overfitting', overfit_history)])
return basic_history, overfit_history
if __name__ == "__main__":
main()



다른 정규화 기법들과 상호보완적으로 사용가능 drop된 뉴런은 backpropagation떄 신호를 차단, test때는 모든 뉴런에 신호 전달.
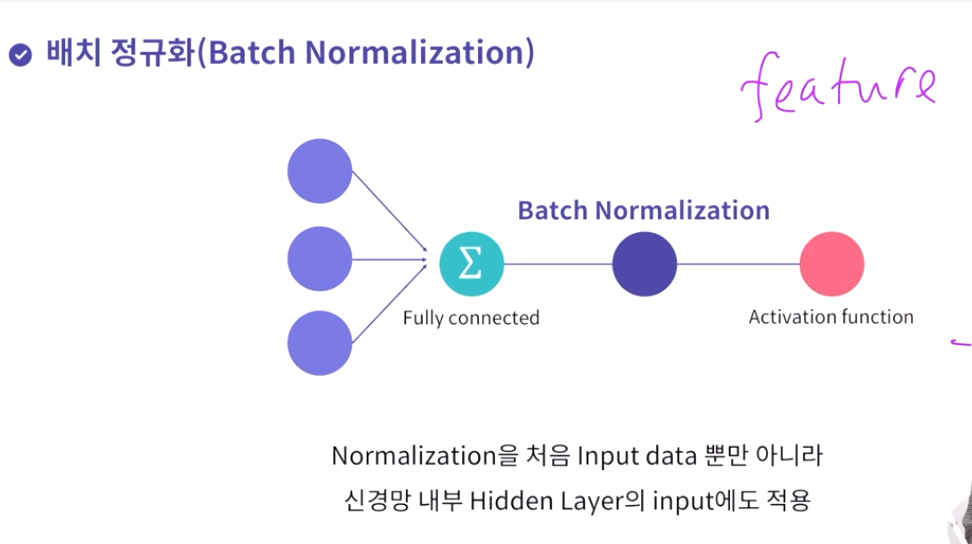
-> 매 layer마다 정규화를 진행하므로 가중치 초기값에 크게 의존하지 않아 초기화 중요도를 줄일 수 있다는 장점이 있다.
또한 과적합 억제(드롭아웃, L1,L2 정규화 필요성이 감소된다) , 학습속도가 향상된다.
과적합이 발생하는 원인
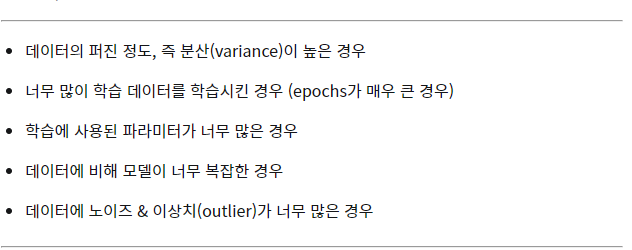
import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 과적합 될 모델과 비교하기 위해 기본 모델을
마크다운 설명과 동일하게 생성합니다.
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([ tf.keras.layers.Dense(256, activation = 'relu', input_shape=(word_num,)), tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return basic_model
'''
2. 기본 모델의 레이어 수와 노드 수를 자유롭게 늘려서
과적합 될 모델을 생성합니다.
'''
def Overfitting(word_num):
overfit_model = tf.keras.Sequential([ tf.keras.layers.Dense(256, activation = 'relu', input_shape=(word_num,)), tf.keras.layers.Dense(128, activation = 'relu'),tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(512, activation = 'relu'),
tf.keras.layers.Dense(1, activation= 'sigmoid')])
return overfit_model
'''
3. 두 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. basic_model와 overfit_model 함수를 이용해
두 모델을 불러옵니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 학습시킵니다.
검증용 데이터도 설정해주세요.
기본 모델은 'epochs'를 20,
과적합 모델은 'epochs'를 300이상으로 설정합니다.
'batch_size'는 두 모델 모두 500으로 설정합니다.
Step05. 두 모델을 테스트하고
binary crossentropy 값을 출력합니다.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델입니다.
overfit_model = Overfitting(word_num) # 과적합시킬 모델입니다.
basic_model.compile(loss = 'binary_crossentropy', optimizer = 'adam',
metrics = ['accuracy','binary_crossentropy'])
overfit_model.compile(loss = 'binary_crossentropy', optimizer = 'adam',
metrics = ['accuracy','binary_crossentropy'])
basic_model.summary()
overfit_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size=500,validation_data=(test_data, test_labels), verbose=0)
print('\n')
overfit_history = overfit_model.fit(train_data, train_labels, epochs=300, batch_size=500,validation_data=(test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose = 0)
scores_overfit = overfit_model.evaluate(test_data, test_labels, verbose = 0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_overfit: ', scores_overfit[-1])
Visualize([('Basic', basic_history),('Overfitting', overfit_history)])
return basic_history, overfit_history
if __name__ == "__main__":
main()


import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. L1, L2 정규화를 적용한 모델과 비교하기 위한
하나의 기본 모델을 자유롭게 생성합니다.
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([tf.keras.layers.Dense(128, input_shape= (word_num,), activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')])
return basic_model
'''
2. 기본 모델에 L1 정규화를 적용합니다.
입력층과 히든층에만 적용하세요.
'''
def L1(word_num):
l1_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape= (word_num,), activation='relu',kernel_regularizer = tf.keras.regularizers.l1(0.001)),
tf.keras.layers.Dense(128, activation='relu', kernel_regularizer=tf.keras.regularizers.l1(0.001)),
tf.keras.layers.Dense(1, activation='sigmoid')])
return l1_model
'''
3. 기본 모델에 L2 정규화를 적용합니다.
입력층과 히든층에만 적용하세요.
'''
def L2(word_num):
l2_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape= (word_num,), activation='relu',kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dense(128, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dense(1, activation='sigmoid')])
return l2_model
'''
4. 세 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. Basic, L1, L2 함수를 이용해 세 모델을 불러옵니다.
Step02. 세 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 세 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 세 모델을 학습시킵니다.
세 모델 모두 'epochs'는 20,
'batch_size'는 500으로 설정합니다.
검증용 데이터도 설정해주세요.
Step05. 세 모델을 테스트하고
binary crossentropy 값을 출력합니다.
셋 중 어느 모델의 성능이 가장 좋은지 확인해보세요.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델입니다.
l1_model = L1(word_num) # L1 정규화를 적용할 모델입니다.
l2_model = L2(word_num) # L2 정규화를 적용할 모델입니다.
basic_model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy', 'binary_crossentropy'])
l1_model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy', 'binary_crossentropy'])
l2_model.compile(loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy', 'binary_crossentropy'])
basic_model.summary()
l1_model.summary()
l2_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
l1_history = l1_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
l2_history = l2_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose=0)
scores_l1 = l1_model.evaluate(test_data, test_labels, verbose=0)
scores_l2 = l2_model.evaluate(test_data, test_labels, verbose=0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_l1: ', scores_l1[-1])
print('scores_l2: ', scores_l2[-1])
Visulaize([('Basic', basic_history),('L1 Regularization', l1_history), ('L2 Regularization', l2_history)])
return basic_history, l1_history, l2_history
if __name__ == "__main__":
main()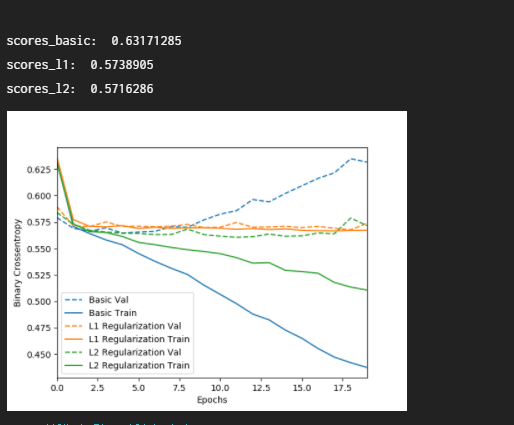


import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# 데이터를 전처리하는 함수
def sequences_shaping(sequences, dimension):
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0
return results
'''
1. 드롭 아웃을 적용할 모델과 비교하기 위한
하나의 기본 모델을 자유롭게 생성합니다.
'''
def Basic(word_num):
basic_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return basic_model
'''
2. 기본 모델에 드롭 아웃 레이어를 추가합니다.
일반적으로 마지막 히든층과 출력층 사이에 하나만 추가합니다.
드롭 아웃 적용 확률은 자유롭게 설정하세요.
'''
def Dropout(word_num):
dropout_model = tf.keras.Sequential([
tf.keras.layers.Dense(128, input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(128, input_shape=(word_num,), activation='relu'),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return dropout_model
'''
3. 두 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. Basic, Dropout 함수를 이용해 두 모델을 불러옵니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 학습시킵니다.
두 모델 모두 'epochs'는 20,
'batch_size'는 500으로 설정합니다.
검증용 데이터도 설정해주세요.
Step05. 두 모델을 테스트하고
binary crossentropy 점수를 출력합니다.
둘 중 어느 모델의 성능이 더 좋은지 확인해보세요.
'''
def main():
word_num = 100
data_num = 25000
# Keras에 내장되어 있는 imdb 데이터 세트를 불러오고 전처리합니다.
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.imdb.load_data(num_words = word_num)
train_data = sequences_shaping(train_data, dimension = word_num)
test_data = sequences_shaping(test_data, dimension = word_num)
basic_model = Basic(word_num) # 기본 모델입니다.
dropout_model = Dropout(word_num) # 드롭 아웃을 적용할 모델입니다.
basic_model.compile(loss='binary_crossentropy', optimizer='adam', metrics = ['accuracy', 'binary_crossentropy'])
dropout_model.compile(loss='binary_crossentropy', optimizer='adam', metrics = ['accuracy', 'binary_crossentropy'])
basic_model.summary()
dropout_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
dropout_history = dropout_model.fit(train_data, train_labels, epochs=20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose = 0)
scores_dropout = dropout_model.evaluate(test_data, test_labels, verbose = 0)
print('\nscores_basic: ', scores_basic[-1])
print('scores_dropout: ', scores_dropout[-1])
Visulaize([('Basic', basic_history),('Dropout', dropout_history)])
return basic_history, dropout_history
if __name__ == "__main__":
main()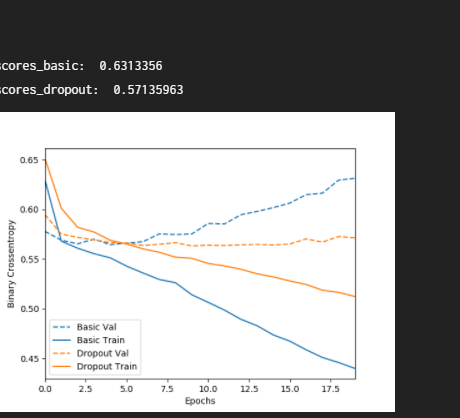


import numpy as np
import tensorflow as tf
from visual import *
import logging, os
logging.disable(logging.WARNING)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
np.random.seed(200)
tf.random.set_seed(200)
# 배치 정규화를 적용할 모델과 비교하기 위한 기본 모델입니다.
def Basic():
basic_model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(64),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return basic_model
'''
1. 기본 모델에 배치 정규화 레이어를 적용한
모델을 생성합니다. 입력층과 출력층은 그대로 사용합니다.
'''
def BN():
bn_model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(512),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(64),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(256),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return bn_model
'''
2. 두 개의 모델을 불러온 후 학습시키고 테스트 데이터에 대해 평가합니다.
Step01. Basic, BN 함수를 이용해 두 모델을 불러옵니다.
Step02. 두 모델의 손실 함수, 최적화 알고리즘,
평가 방법을 설정합니다.
Step03. 두 모델의 구조를 확인하는 코드를 작성합니다.
Step04. 두 모델을 학습시킵니다.
두 모델 모두 'epochs'는 20,
'batch_size'는 500으로 설정합니다.
검증용 데이터도 설정해주세요.
Step05. 두 모델을 테스트하고 accuracy 값을 출력합니다.
둘 중 어느 모델의 성능이 더 좋은지 확인해보세요.
'''
def main():
# MNIST 데이터를 불러오고 전처리합니다.
mnist = tf.keras.datasets.mnist
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data, test_data = train_data / 255.0, test_data / 255.0
basic_model = Basic() # 기본 모델입니다.
bn_model = BN() # 배치 정규화를 적용할 모델입니다.
basic_model.compile(loss = 'sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
bn_model.compile(loss = 'sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
basic_model.summary()
bn_model.summary()
basic_history = basic_model.fit(train_data, train_labels, epochs = 20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
print('\n')
bn_history = bn_model.fit(train_data, train_labels, epochs = 20, batch_size=500, validation_data = (test_data, test_labels), verbose=0)
scores_basic = basic_model.evaluate(test_data, test_labels, verbose=0)
scores_bn = bn_model.evaluate(test_data, test_labels, verbose=0)
print('\naccuracy_basic: ', scores_basic[-1])
print('accuracy_bn: ', scores_bn[-1])
Visulaize([('Basic', basic_history),('Batch Normalization', bn_history)])
return basic_history, bn_history
if __name__ == "__main__":
main()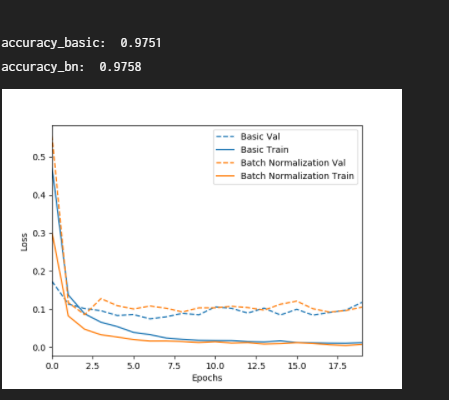
'작업 > 머신러닝' 카테고리의 다른 글
| 22.01.14 드디어 프로젝트 배포 (0) | 2022.01.14 |
|---|---|
| 22.01.13 텐서플로우와 딥러닝 (0) | 2022.01.13 |
| 22.01.12 딥러닝 개론 (0) | 2022.01.12 |
| 21.12.19 모의테스트 (0) | 2021.12.19 |
| 21.12.18 나이브베이즈 분류 (0) | 2021.12.19 |