2021. 12. 19. 20:40ㆍ작업/머신러닝
기상 정보(구름양, 풍속)을 활용해 해당 공항의 연착 여부를 예측하기 ( No, Yes )

분류 : 주어진 입력값이 어떤 클래스에 속할지에 대한 결과값을 도출하는 알고리즘
일반적인 회귀 알고리즘은 분류 문제에 사용할 수 없다.
-> 해당 클래스에 속할 확룔인 0 또는 1 사이의 값만 내보낼 수 있도록 선형 회귀 알고리즘을 수정한다.

로지스틱 회귀(Logistic Regression) : 분류 문제에 적용하기 위해 출력값의 범위를 수정한 회귀
주로 이진 분류 문제를 해결하기 위한 모델, 최소값0 최대값1로 결과값을 수렴시키기 위해 Sigmoid(logistic) 함수를 사용함
Sigmoid 함수

결정 경계 : 데이터를 분류하는 기준값, 일반적으로 출력값 0.5를 기준으로

실습 1 로지스틱 회귀
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 데이터를 생성하고 반환하는 함수입니다.
def load_data():
np.random.seed(0)
X = np.random.normal(size = 100)
y = (X > 0).astype(np.float)
X[X > 0] *= 5
X += .7 * np.random.normal(size = 100)
X = X[:, np.newaxis]
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 100)
return train_X, test_X, train_y, test_y
"""
1. 로지스틱 회귀 모델을 구현하고,
학습 결과를 확인할 수 있는 main() 함수를 완성합니다.
Step01. 데이터를 불러옵니다.
Step02. 로지스틱 회귀 모델을 정의합니다.
Step03. 학습용 데이터로 로지스틱 회귀 모델을
학습시킵니다.
Step04. 테스트용 데이터로 예측한 분류 결과를
확인합니다.
"""
def main():
train_X, test_X, train_y, test_y = load_data()
logistic_model = LogisticRegression()
logistic_model.fit(train_X,train_y)
predicted = logistic_model.predict(test_X)
# 예측 결과 확인하기
print("예측 결과 :", predicted[:10])
plot_logistic_regression(logistic_model, train_X, train_y)
return logistic_model
if __name__ == "__main__":
main()
SVM (Support Vector Machine) : 딥러닝이 발전하기 전까지 인기있었던 분류 알고리즘

최적의 결정 경계는 데이터 군으로부터 최대한 멀리 떨어지는 것
마진을 최대한 넓게.. 마진 : 결정 경계 (보라색선)과 서포트벡터(초록선) 사이 거리

Hard Margin, Soft Margin 마진 안에 어느 정도 데이터가 들어갈 수도 있음.
SVM 특징

실습 2 SVM
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
"""
1. data 폴더 내에 있는 dataset.csv파일을 불러오고,
학습용 데이터와 테스트용 데이터를 분리하여
반환하는 함수를 구현합니다.
Step01. pandas의 read_csv() 함수를 이용하여
data 폴더 내에 있는 dataset.csv파일을
불러옵니다.
Step02. 데이터 X와 y를 분리합니다.
데이터 폴더에 있는 dataset.csv 파일을
확인하고,
X 데이터와 y 데이터를 분리하여 각 변수에
저장합니다.
"""
def load_data():
data = pd.read_csv('data/dataset.csv')
X = data.drop('Class', axis=1)
y = data['Class']
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 0)
print(X, y)
return train_X, test_X, train_y, test_y
"""
2. SVM 모델을 불러오고,
학습용 데이터에 맞추어 학습시킨 후,
테스트 데이터에 대한 예측 결과를 반환하는 함수를
구현합니다.
Step01. SVM 모델을 정의합니다.
Step02. SVM 모델을 학습용 데이터에 맞추어
학습시킵니다.
Step03. 학습된 모델을 이용하여
테스트 데이터에 대한 예측을 수행합니다.
"""
def SVM(train_X, test_X, train_y, test_y):
svm = SVC()
svm.fit(train_X,train_y)
pred_y = svm.predict(test_X)
return pred_y
# 데이터를 불러오고, 모델 예측 결과를 확인하는 main 함수입니다.
def main():
train_X, test_X, train_y, test_y = load_data()
pred_y = SVM(train_X, test_X, train_y, test_y)
# SVM 분류 결과값을 출력합니다.
print("\nConfusion matrix : \n",confusion_matrix(test_y,pred_y))
print("\nReport : \n",classification_report(test_y,pred_y))
if __name__ == "__main__":
main()
나이브 베이즈 분류 : 10만개의 메일 중 스팸메일과 정상메일을 분류하고 싶다면?
(메일은 독립사건으로 정의)
각 특징들이 독립적, 즉 서로 영향을 미치지 않을 것이라는 가정 설정, 베이즈 정리를 활용한 확률 통계학적 분류 알고리즘

나이브베이즈 분류 특징

실습3 베이즈 정리로 나이브 베이즈 분류 구현
import numpy as np
"""
1. "확인" 이라는 키워드가 등장했을 때
해당 메일이 스팸 메일인지 정상 메일인지
판별하기 위한 함수를 구현합니다.
"""
def bayes_theorem():
# 1. P(“스팸 메일”) 의 확률을 구하세요.
p_spam = 8/20
# 2. P(“확인” | “스팸 메일”) 의 확률을 구하세요.
p_confirm_spam = 5/8
# 3. P(“정상 메일”) 의 확률을 구하세요.
p_ham = 12/20
# 4. P(“확인” | "정상 메일" ) 의 확률을 구하세요.
p_confirm_ham = 2/12
# 5. P( "스팸 메일" | "확인" ) 의 확률을 구하세요.
p_spam_confirm = p_confirm_spam * p_spam / (7/20)
# 6. P( "정상 메일" | "확인" ) 의 확률을 구하세요.
p_ham_confirm = p_confirm_ham * p_ham / (7/20)
return p_spam_confirm, p_ham_confirm
def main():
p_spam_confirm, p_ham_confirm = bayes_theorem()
print("P(spam|confirm) = ",p_spam_confirm, "\nP(ham|confirm) = ",p_ham_confirm, "\n")
# 두 값을 비교하여 확인 키워드가 스팸에 가까운지 정상 메일에 가까운지 확인합니다.
value = [p_spam_confirm, p_ham_confirm]
if p_spam_confirm > p_ham_confirm:
print( round(value[0] * 100, 2), "% 의 확률로 스팸 메일에 가깝습니다.")
else :
print( round(value[1] * 100, 2), "% 의 확률로 일반 메일에 가깝습니다.")
if __name__ == "__main__":
main()

실습 4 사이킷런을 활용한 나이브베이즈 분류
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
"""
1. 데이터를 불러오고,
불러온 데이터를 학습용, 테스트용 데이터로
분리하여 반환하는 함수를 구현합니다.
Step01. 사이킷런에 저장되어 있는 데이터를
(X, y) 형태로 불러옵니다.
Step02. 불러온 데이터를
학습용 데이터와 테스트용 데이터로 분리합니다.
학습용 데이터 : 80%, 테스트용 데이터 : 20%,
일관된 결과 확인을 위해 random_state를
0 으로 설정합니다.
"""
def load_data():
X, y = load_wine(return_X_y = True)
print("데이터 확인해보기 :\n", X[:1])
train_X, test_X, train_y, test_y = train_test_split(X,y,test_size = 0.2, random_state = 0)
return train_X, test_X, train_y, test_y
"""
2. 가우시안 나이브 베이즈 모델을 불러오고,
학습을 진행한 후 테스트 데이터에 대한
예측값을 반환하는 함수를 구현합니다.
Step01. 가우시안 나이브 베이즈 모델을 정의합니다.
Step02. 학습용 데이터에 대해 모델을 학습시킵니다.
Step03. 테스트 데이터에 대한 모델 예측을 수행합니다.
"""
def Gaussian_NB(train_X, test_X, train_y, test_y):
model = GaussianNB()
model.fit(train_X, train_y)
predicted = model.predict(test_X)
return predicted
# 데이터 불러오기, 모델 예측 결과를 확인할 수 있는 함수입니다.
def main():
train_X, test_X, train_y, test_y = load_data()
predicted = Gaussian_NB(train_X, test_X, train_y, test_y)
## 모델 정확도를 통해 분류 성능을 확인해봅니다.
print("\nModel Accuracy : ")
print(accuracy_score(test_y, predicted))
if __name__ == "__main__":
main()
KNN K-Nearest Neighbor
영화 평점 데이터를 기준으로 새로 유입된 고객을 기준에 따라 분류하고자 하는 경우
기존 데이터 가운데 가장 가까운 k개 이웃의 정보로 새로운 데이터를 예측하는 방법론
(유사한 특성을 가진 데이터는 유사 범주에 속하는 경향이 있다는 가정 하에 분류)
KNN 원리

KNN 특징

분류 알고리즘 평가 지표
1. 혼동 행렬(Confusion Matrix)
TP, TN, FP, FN
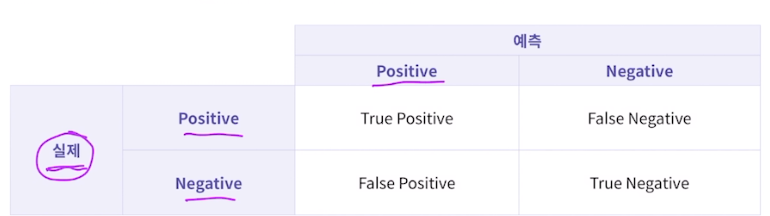

1형오류, 2형오류
정확도 (Accuracy)
전체 데이터 중에서 제대로 분류된 데이터의 비율, 그러나 클래스 비율이 불균형할 경우 평가 지표의 신뢰성 잃음

실습5 혼동행렬
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import warnings
warnings.filterwarnings(action='ignore')
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
# 데이터를 불러와 학습용, 테스트용 데이터로 분리하여 반환하는 함수입니다.
def load_data():
X, y = load_wine(return_X_y = True)
class_names = load_wine().target_names
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size =0.3, random_state=0)
return train_X, test_X, train_y, test_y, class_names
# Confusion matrix 시각화를 위한 함수입니다.
def plot_confusion_matrix(cm, y_true, y_pred, classes, normalize=False, cmap=plt.cm.OrRd):
title = ""
if normalize:
title = 'Normalized confusion matrix'
else:
title = 'Confusion matrix'
classes = classes[unique_labels(y_true, y_pred)]
if normalize:
# 정규화 할 때는 모든 값을 더해서 합이 1이 되도록 각 데이터를 스케일링 합니다.
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print(title, ":\n", cm)
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=cmap)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=classes, yticklabels=classes,
title=title,
ylabel='True label',
xlabel='Predicted label')
# label을 45도 회전해서 보여주도록 변경
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
# confusion matrix 실제 값 뿌리기
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
plt.savefig('confusion matrix.png')
elice_utils.send_image('confusion matrix.png')
"""
1. 혼동 행렬을 계산하고,
시각화하기 위한 main() 함수를 완성합니다.
Step01. 데이터를 불러옵니다.
Step02. 분류 예측 결과를 평가하기 위한 혼동 행렬을 계산합니다.
Step03. confusion matrix를 시각화하여 출력합니다.
plot_confusion_matrix 함수의 인자를 참고하여
None을 채워보세요.
3-1. 혼동 행렬 시각화 결과를 확인합니다.
3-2. 함수의 인자 normalize값을 True로 설정하여
정규화된 혼동 행렬 시각화 결과를 확인합니다.
"""
def main():
train_X, test_X, train_y, test_y, class_names = load_data()
# SVM 모델로 분류기를 생성하고 학습합니다.
classifier = SVC()
y_pred = classifier.fit(train_X, train_y).predict(test_X)
cm = confusion_matrix(test_y, y_pred) # 정답,예측값
plot_confusion_matrix(cm, test_y, y_pred, classes=class_names)
# 정규화 된 혼동 행렬을 시각화합니다.
plot_confusion_matrix(cm, test_y, y_pred, classes=class_names, normalize = True)
return cm
if __name__ == "__main__":
main()
분류 알고리즘 평가 지표
정밀도(Precision) : 모델이 Positive라고 분류한 데이터 중 실제로 Positive인 데이터 비율

ex) negative가 중요한 경우 사용(일반 메일을 스팸메일로 잘못 분류하면 중요한 메일을 못 받을 수도 있음)
재현율(Recall, TPR)
실제로 Positive인 데이터 중 모델이 Positive로 분류한 데이터의 비율
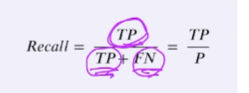
ex) positive가 중요한 경우 사용(악성 종양을 양성 종양으로 잘못 예측하는 경우 제 때 치료 못받으니 위험)
FPR(False Positive Rate)
실제로 Nega중에서 모델이 Pos로 분류한 데이터의 비율
ex) 비정상 행동을 찾아낼때(게임에서 비정상 사용자 검출.. FPR이 높다) 선의의 사용자도 피해를 입을 확률 있음
ROC Curve, AUC
x축이 FPR, y축이 Recall

실습6 정확도,정밀도,재현율
import pandas as pd
def main():
# 실제 값
y_true = pd.Series(
["not mafia", "not mafia", "mafia", "not mafia", "mafia",
"not mafia", "not mafia", "mafia", "not mafia", "not mafia"]
)
# 예측된 값
y_pred = pd.Series(
["mafia", "mafia", "not mafia", "not mafia", "mafia",
"not mafia", "not mafia", "mafia", "not mafia", "not mafia"]
)
print("1. 혼동 행렬 :\n",pd.crosstab(y_true, y_pred, rownames=['실제'], colnames=['예측'], margins=True))
"""
1. 실행 버튼을 클릭하여
마피아(mafia)와 시민(not mafia)으로 분류된 혼동 행렬을 확인합니다.
"""
"""
2. 실행 결과값을 토대로
마피아를 제대로 분석했는 지에 대한
accuracy, precision, recall을 구합니다.
"""
accuracy = (2+5)/10
precision = 2/4
recall = 2/3
print("\naccuracy : ", accuracy)
print("precision : ", precision)
print("recall : ", recall)
return accuracy, precision, recall
if __name__ == "__main__":
main()

'작업 > 머신러닝' 카테고리의 다른 글
| 21.12.19 모의테스트 (0) | 2021.12.19 |
|---|---|
| 21.12.18 나이브베이즈 분류 (0) | 2021.12.19 |
| 21.12.18 회귀분석 (0) | 2021.12.19 |
| 21.12.18 선형대수 / Numpy (0) | 2021.12.19 |
| 21.12.18 머신러닝 회귀(Regression) (0) | 2021.12.19 |