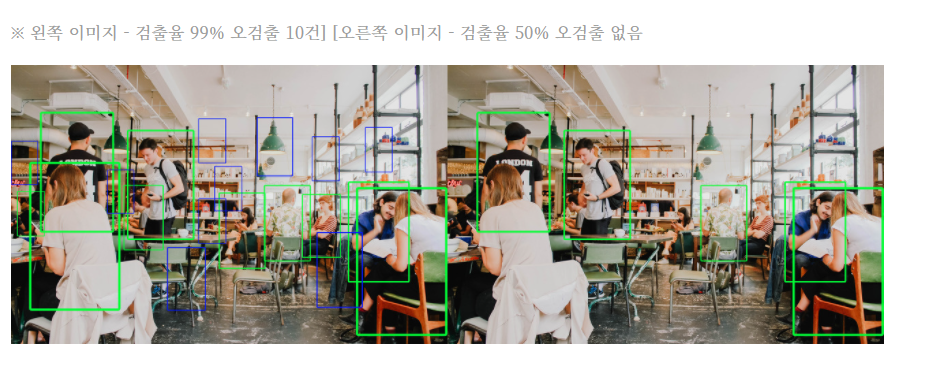
2022. 2. 25. 17:48ㆍ프로젝트/KFood
training에 사용한 것들 : tmux, wandb, Tesla gpu가 있는 원격서버. tmux, wandb를 사용하면 컴퓨터를 꺼놓고도 계속 잘 돌아간다.
- 목차
- 돌린 코드
- training 스크린샷
- wandb 결과(아직 4epoch 진행중)
- precision, recall, mAP
- box, obj, cla loss
- lr0, lr1, lr2
- 우리 데이터셋
(여기에 구글드라이브 추가하기)
https://github.com/ultralytics/yolov3
GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
YOLOv3 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov3 development by creating an account on GitHub.
github.com
- 사용한 깃허브
돌린 코드 : 일단 weight는 전이학습된 yolov3.pt를 사용.
python train.py --img 640 --batch 16 epochs 5 --data kfood.yaml --weights yolov3.pt --name batch_16_lr_0.01tmux의 'guri'라는 session에서 컴퓨터를 끄고도 training 되고 있는 중
tmux at -t guri로 다시 켜져있던 session에 잠깐 들어가 확인해보니 잘 training 되고 있다.
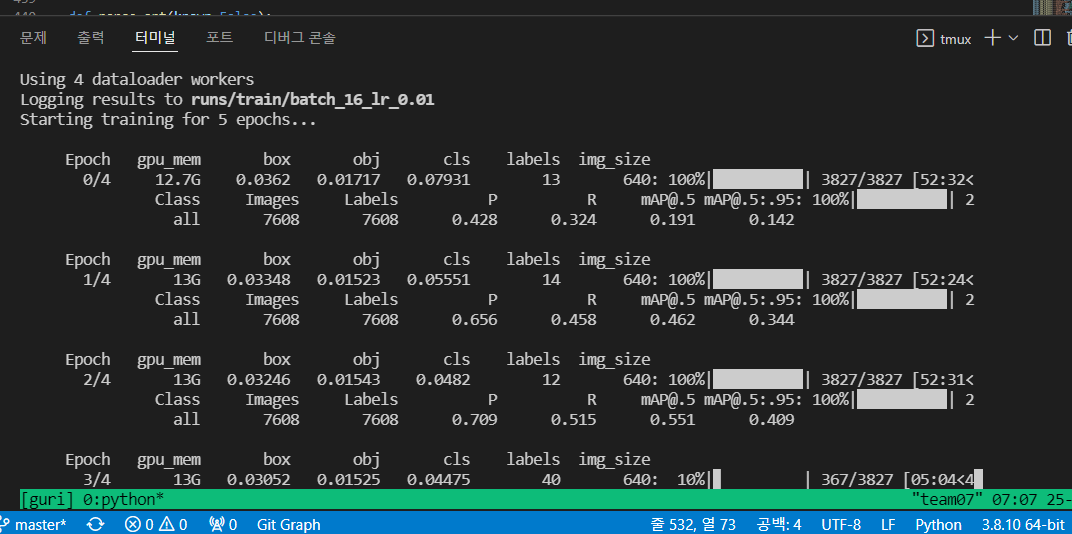
----------------------------------------------------------------------------------------------------------------------------------
그리고 아래는 wandb 결과이다. metrics의 항목으로 recall, precision, mAP가 있고
train/ val 각각 box, obj ,cla loss가 있다.
그리고 x에 대해서는 lr0, lr1, lr2가 있다. 현재 3epoch(0~2)까지 완료해서 step이 3개밖에 없다.
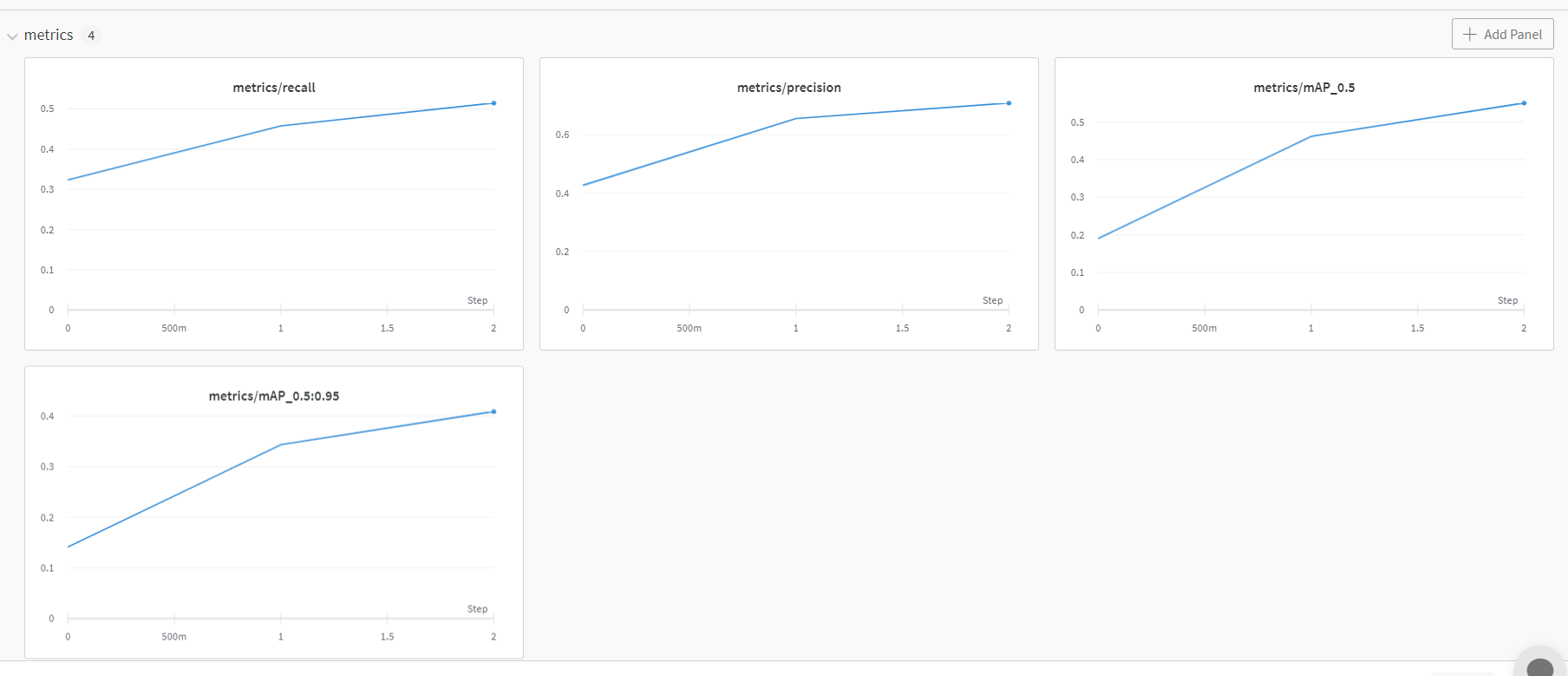
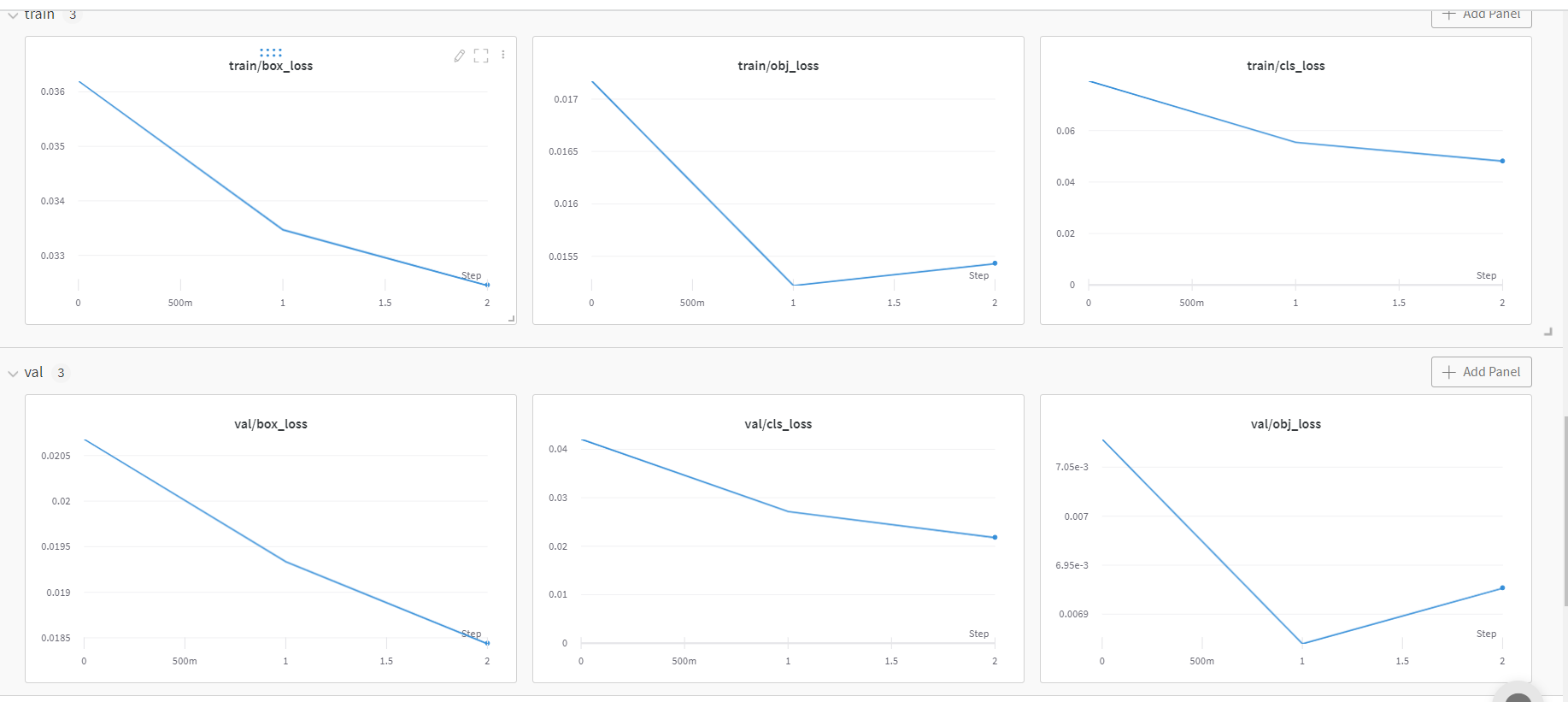
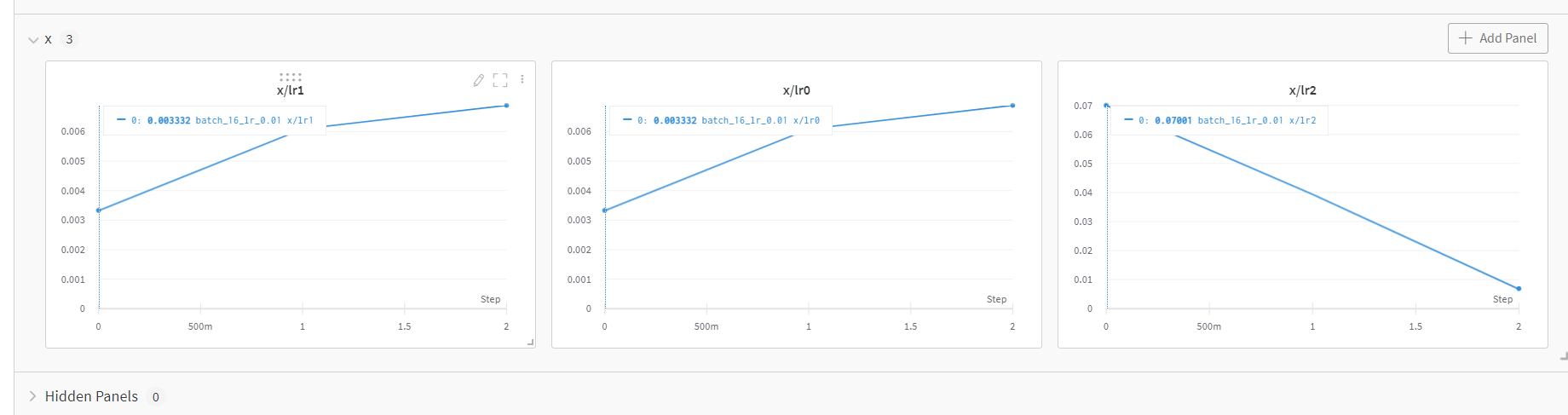
잠깐 recall과 precision 코치님 설명
---------------------------------------------------------------------------------------------------------------------------------
성능 : 빠른 것, 정확한 것 기준이 여러 개다.
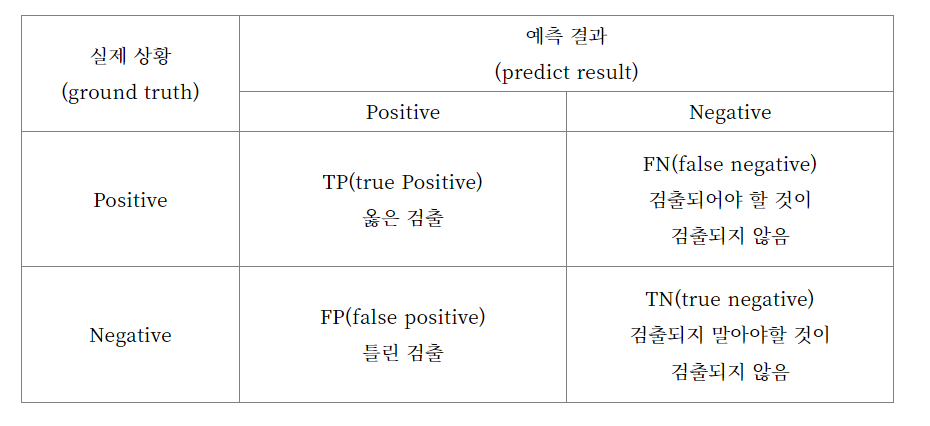
Detection 모델에서는 평가 지표가 따로 있다.
- Precision(정밀도) : 맞힌 것 중에서 정답인 것
- Recall(재현율) : 정답인 것 중에서 맞힌 것
ex. 고양이 5개 강아지 5개
- 고양이들 중에서 얼마나 고양이를 잘 찾아냈냐 (recall)
- 다 고양이로 맞혔을 때 고양이에 대한 recall은 높음
- but 강아지에 대한 recall은 낮음 ?
Precision과 Recall 중 중요도를 정해야 한다. (정답은 없음)
- Recall이 높으면 ?
- 일단은 답을 뱉어내긴 함.
- 음식은 다 찾아 내는데 정확도는 안 좋을 수 있음.
- Precision이 높으면 ?
- 음식을 다 못 찾아내도 정확도는 좋음
ex. 자율주행의 경우 틀리더라도 뭐든 찾아내야하기 때문에 Recall이 중요
우리는 Precision이 좋아야 한다라고 결정!
모델을 평가할 때 Precision에 더 중점을 두고 평가
즉, F1 평균을 높게 하되 자세히는 Precision이 높은 것으로 하자 !
-------------------------------------------------------------------------------------------------------------------------
mAP와 precision, recall에 대한 정리 블로그
mAP(Mean Average Precision) 정리
☞ 문서의 내용은 가장 하단 참고문헌 및 사이트를 참고하여 필자가 보기 쉽도록 정리한 내용입니다. ☞ 틀린 내용 및 저작권 관련 문의가 있는 경우 문의하시면 수정 및 삭제 조치하겠습
ctkim.tistory.com
합성곱 신경망(CNN)의 모델 성능평가를 할 때 정확도 면에서 필요한 요소로 precision, recall, AP(Average Precision)이 있다고 한다.
IoU 옳게 검출된 영역(tbox와 pbox의 영역의 비율?) IoU값이 0.5이상이면 제대로 검출(TP)되었다고 한다. 0.5미만이면 잘못 검출(FP)라고 한다
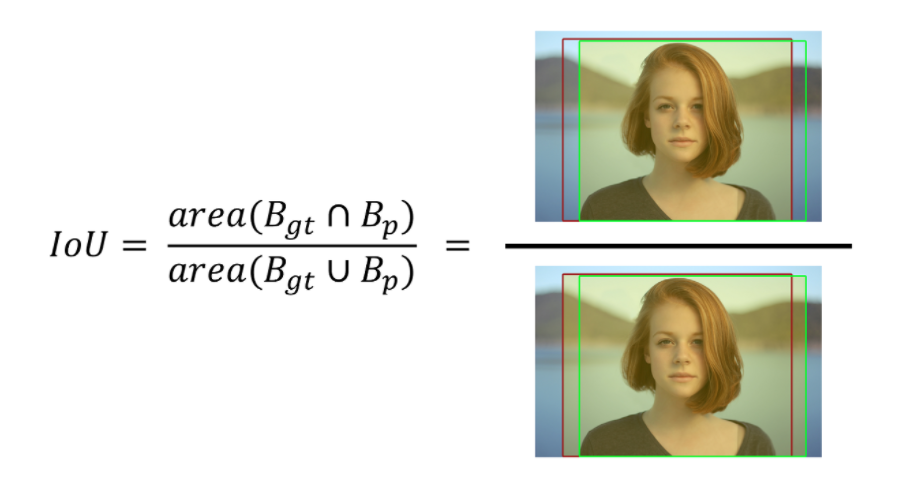
recall: 검출율 , 실제 옳게 검출된 결과물 중 옳다고 예측한 것의 비율
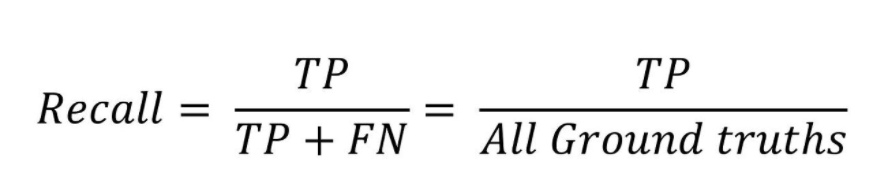
precision: 정확도, 검출 결과들 중 옳게 검출한 비율
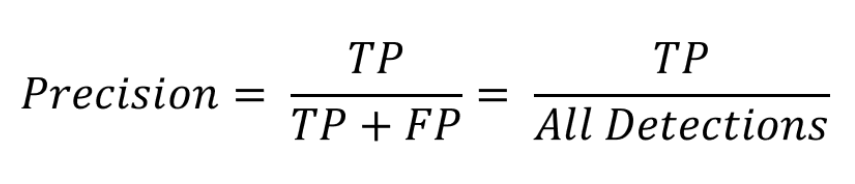
일반적으로 precision과 recall은 trade-off가 있고 반비례 성향이 있다고 한다. 정확도 낮아지면 검출율 높아지고, 검출율 높아지면 정확도가 낮아진다. 따라서 두 개를 적절히 성능 비교하려면 precision-recall 그래프(PR곡선 - x축이 recall, y축이 precision)가 필요하다.
F1 score : Precision과 Recall의 조화평균
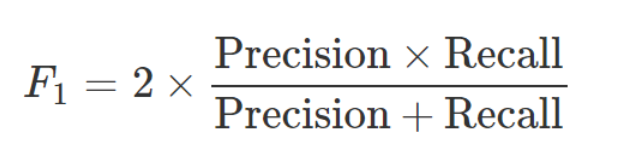
AP : PR 그래프는 알고리즘의 성능을 파악하기엔 좋으나 두 알고리즘의 성능을 정량적으로 비교하긴 어려움. ->
PR 그래프에서 그래프 선 아래 쪽 면적으로 계산한다. 컴퓨터 비전 분야의 Object Detection은 거의 AP로 평가한다.
mAP : mean Average Precision 물체 클래스가 여러 개인 경우 각 클래스 당 AP를 구하고, 그걸 모두 합한 다음 클래스 개수로 나눠주는 것.
----------------------------------------------------------------------------------------------------------------------------
기본적인 머신러닝 정확도 개념
아래는 YOLOv3 의 utils/loss.py 와 wandb에 나오는 개념이다.
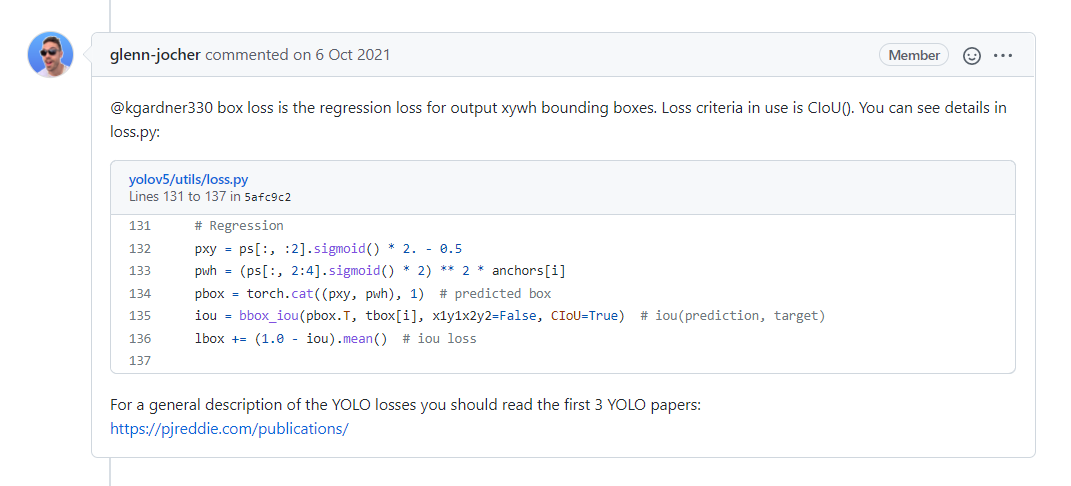
아래 box, cla, obj loss가 도통 뭔지 몰라서 쳐봤는데 원작자의 YOLOv5 깃허브 이슈에 비슷한 사항이 있어서 loss.py를 한번 보려고 한다. box loss는 output xywh bbox의 regression loss라고 한다.
여기서 grid랑 anchor이 뭘까
-------------------------------------------------------------------------------------------------------------------------
grid 와 anchor box
Object Detection의 문제 중 하나는 각각의 grid는 오직 한 개의 object만을 detect할 수 있는 것이다.
만약 각 grid에서 여러개의 object를 검출하려면 어떻게 해야 할까? -> anchor box 이용
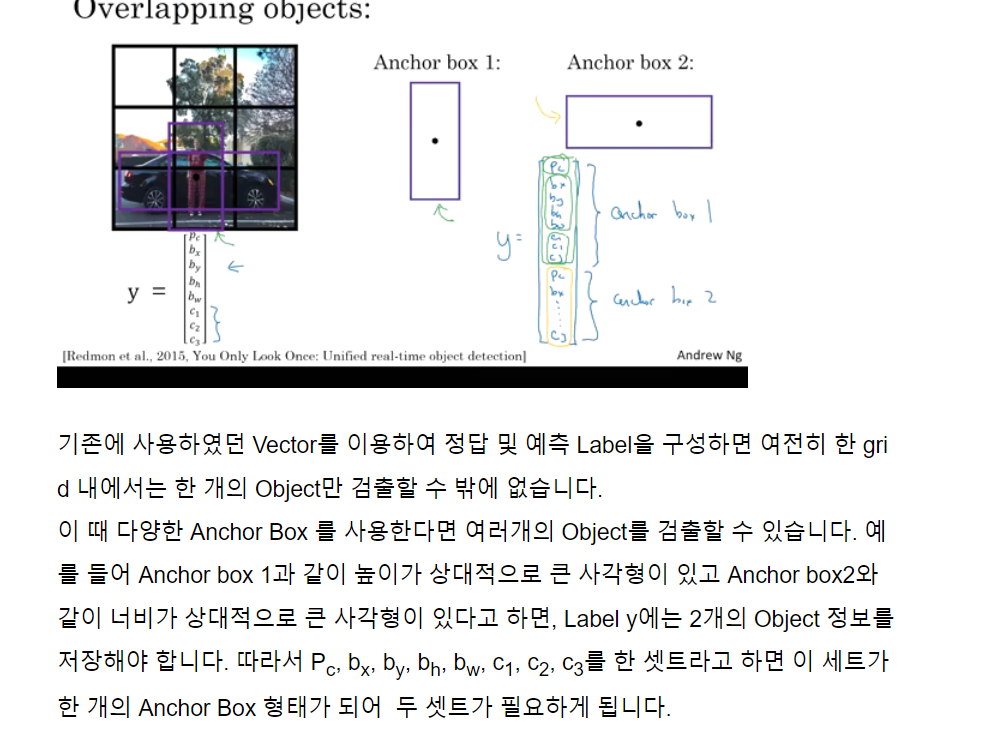
정리해 보면, Anchor Box를 적용하지 않은 상태에서 각각의 Object는 간단히 Object의 midpoint를 포함하는 grid에 할당된다. 반면 Anchor box를 여러개 적용한 경우에서 각각의 Object는 midpoint를 포함하는 grid 중 Anchor box들과 가장 큰 IOU를 가지는 grid에 Object가 할당된다.

위의 예에서 빨간색 박스가 Object라고 하고 세로로 긴 보라색 박스가 Anchor box 1, 가로로 긴 보라색 박스가 Anchor box2라고 하면 Anchor box1의 IOU가 더 크기 때문에 Anchor box1이 선택됩니다.
이 때 Output의 결과를 보면 Anchor box를 두개 사용하였기 때문에 3 x 3 x 8이 아닌 3 x 3 x 16(2 x 8)이 됩니다.
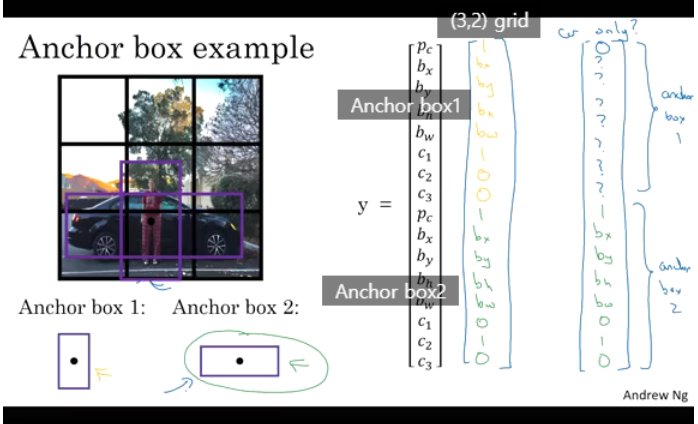
위에서 Pedestrian은 Anchor box1에 좀더 가깝다. 그리고 Car은 Anchor box2에 좀 더 가깝다. 이 때 (3, 2)의 grid cell의 label을 살펴보면 위의 Anchor box1과 Anchor box2에 대하여 Detection한 결과를 나타내고 있다.
만약에 Car만 있다고 하면 Anchor box1의 Pc는 0이되고 나머지 값은 ?(don't care)가 되고 Anchor box2의 정보만 label에 저장된다.
anchor box의 한계
1. 한 grid 내에서 Anchor box의 갯수보다 많은 Object가 있으면 모든 Object를 검출하기 어렵다.
2. 같은 Anchor box에 해당하는 2개 이상의 Object가 있으면 모든 Object를 검출하기 어렵다.
위의 두가지 한계에 해당하는 경우가 발생한다면, 완벽히 Detection을 하기는 어렵고 사실상 위 경우가 발생하지 않기를 바래야 한다. 위의 예제에서는 설명을 위하여 3 x 3 grid를 사용하였지만 일반적으로 훨씬 더 큰 grid 크기를 사용할 것이고 위와 같은 한계 상황은 잘 발생하지 않는다.
Anchor box를 잘 활용하면 정사각형에 가깝지 않은 특이 케이스들, 예를 들어 Pedestrian 같이 height가 상대적으로 크고 width가 상당히 작은 경우나, Car와 같이 width가 큰 경우를 잘 찾을 수 있다.
anchor box를 어떻게 정할까?
Anchor box 갯수를 여러개로 정한 뒤(예를 들어 5 ~ 10개) 사이즈를 직접 정하는 경우가 있을 수 있습니다. 이 때 사이즈는 여러가지 shape을 처리할 수 있도록 정하면 효율적입니다.
좀 더 효과적인 방법으로는 K-means 알고리즘을 이용하여 찾으려고 하는 Object의 shape 끼리 group한 다음 그 group에 알맞는 Anchor box를 사용하면 좀 더 다양한 Object를 대표하는 Anchor box를 찾을 수 있습니다.
----------------------------------------------------------------------------------------------------------------------------------
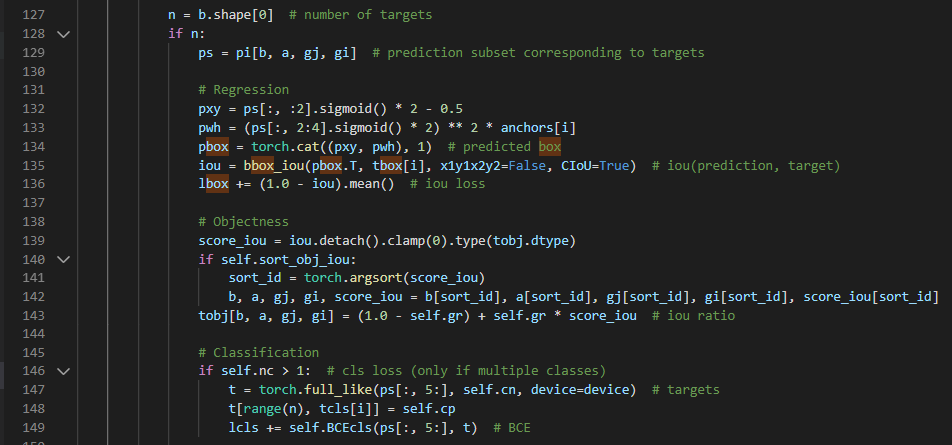
box_loss: pbox(predict box = output box)와 tbox(training box? true box? 실제 정답) 사이의 iou를 구함.
cla_loss: 클래스 개수가 2개 이상일 때(detection 뿐 아니라 classification까지 할 때) prediction subset와 target의 class로 BCE(binary cross entropy, loss함수 종류) 를 구한다?
obj_loss: torch.argsort 사용 : 텐서를 오름차순으로 정렬하는 인덱스를 반환. 그렇게 해서 id를 구하고 target object의 image, anchor, gridx, gridy를 구한다?
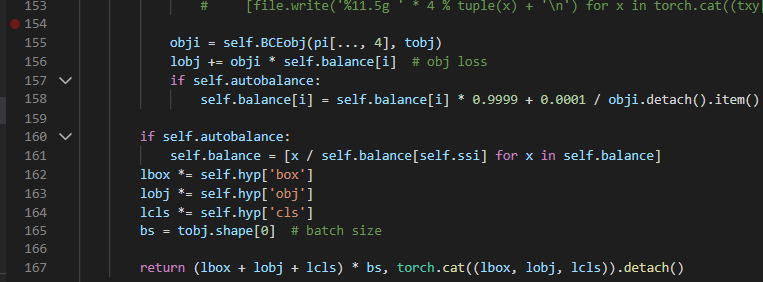
여기서 hyp는 train.py의 parse_opt함수 안에서 하이퍼파라미터를 말하는 듯..??

옵션 안주면 기본값인 저 hyp.scratch.yaml 파일
torch.ones, torch.zeros, torch.zero_like(0으로 채워진 텐서), torch.full_like(특정 수 하나로 채워진 텐서) 등 예제와 설명
Pytorch Tensor(텐서) 만들기
<!DOCTYPE html> torch_tensor Pytorch의 Tensor(텐서) 조작하기 1¶ import torch import numpy as np Tensor(텐서) 를 만드는 다양한 방법¶ empty¶ 주어진 크기의 아무값으로도 초기화되지 않은 텐서를 만든다..
tempdev.tistory.com
----------------------------------------------------------------------------------------------------------------------
하이퍼파라미터는 train.py에서 이 부분에서 설정하는 것 같다.(optimizer와 scheduler 등등 사용)
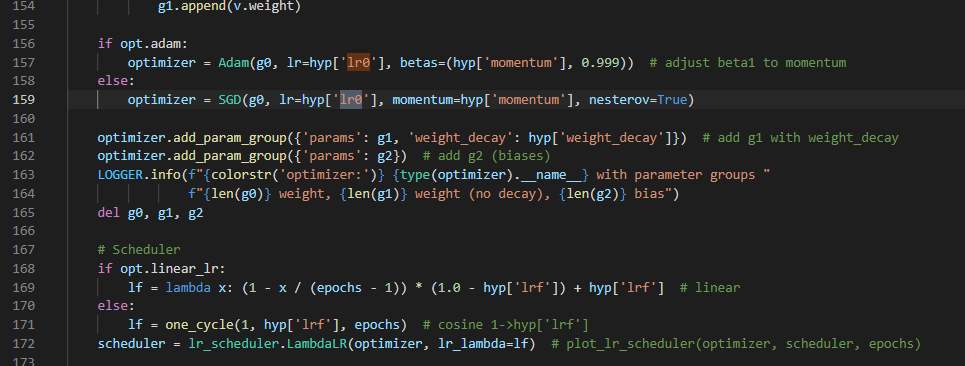
그리고 default 하이퍼파라미터는 data/hyps.hyp.scratch.yaml 파일에 있다.
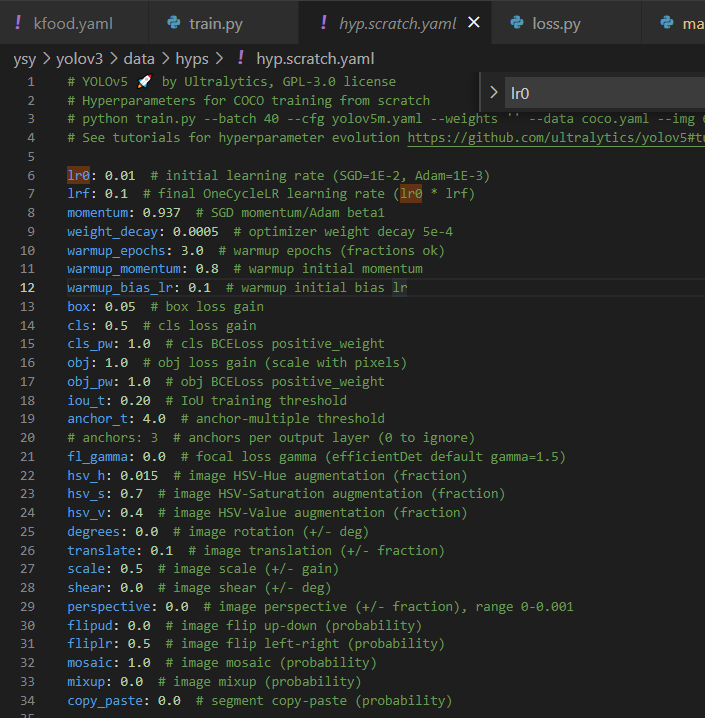
lr0: initial learning rate . 초기 보폭
lrf: final one-cycle learning rate . (lr0 * lrf) 최종 한 사이클 돌고 나서의 보폭?
lr1: 왠지 1epoch후 lr
lr2: 2epoch후 lr일 것 같은데 아직 모르겠음.
-----------------------------------------------------------------------------------------------------------------------
runs/train/batch_16_lr_0.01 폴더에
train_batch0.jpg
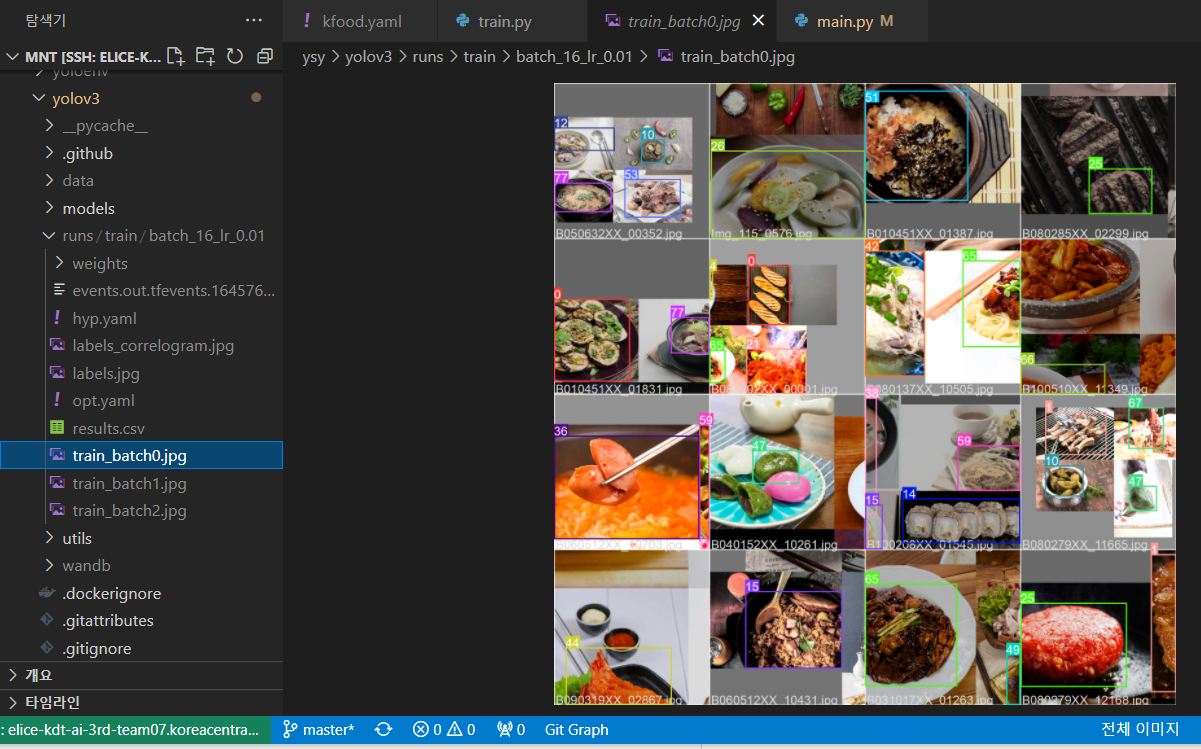
batch_size = 16이어서 다음과 같이 각 클래스 당 16개의 사진이 있는건가?
일단 5epoch 다 돌고 나면 다음 포스팅을 쓰겠다.