2022. 2. 25. 00:24ㆍ프로젝트/KFood

학습을 할 떄 learning rate를 크게도 작게도 해줘야 한다. learning rate : 보폭
learning rate가 너무 작으면 학습이 늦게되거나 local minmum에 빠짐
learning rate가 너무 크면 학습이 안 되거나 (발산?) 튄다.
Gradient Descent로 제일 loss가 작은 곳으로 가야한다.
-> learning rate를 일정하게 가져가면 안된다. 계속 바꾸가면서 학습의 방향성을 찾아야 한다.
-> learning rate schduler : 코싸인모양, 계단함수모양 등등 다양함
1. learning rate scheduler : learning rate를 계속 바꿔줘야 해서
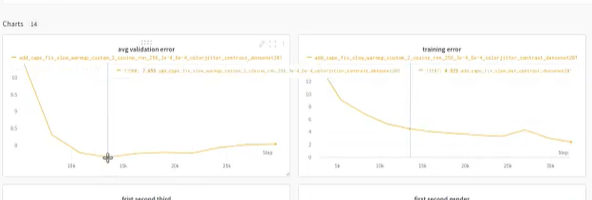
2. overfitting : overfitting를 판단하는 방법 : trainin error는 줄고, validation error는 증가한다
즉 저 둘의 절충점을 찾는 게 좋다. -> 학습을 무조건 오래하는 게 좋은 게 아니라 적정한 곳에서 끊어야 한다.
-> wandb를 좀더 custom하게 사용해보자

일단 metric은 다 있으니 그냥 쓰자
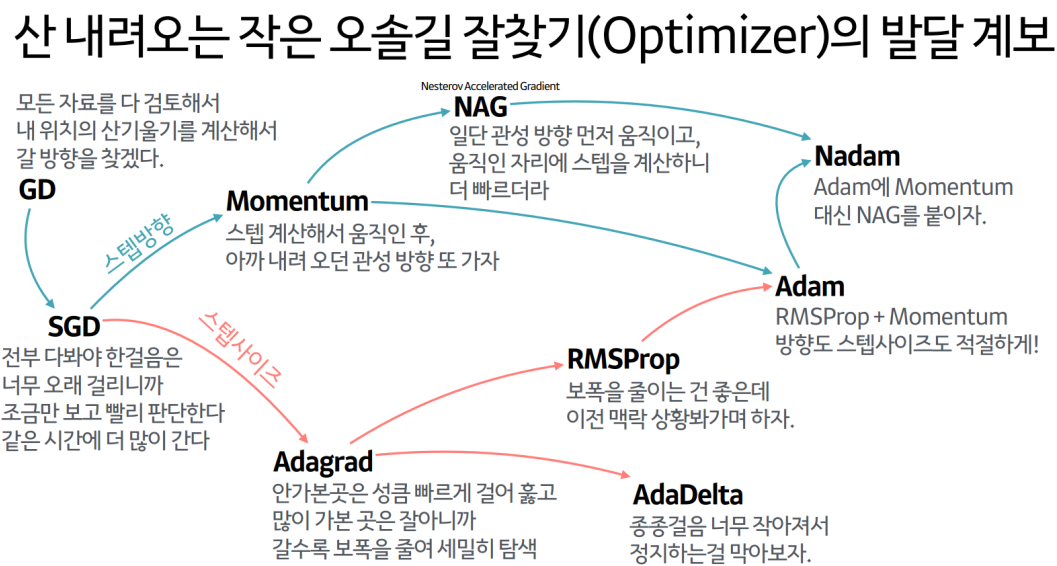
학습에 영향을 주는 것: lr(보폭), scheduler(lr을 어떻게 정해나갈 것이냐), optimizer(minimum을 어떻게 찾을 것인가)
-> 이런 거 필요없고, (우리가 쓸 모델) github 나 원저자의 논문을 보면 가장 학습이 잘 된
batch size, learning rate, 등등을 알려준다.
우리가 쓸 것 YOLOv3 github
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Da
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ) - GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object ...
github.com
-> lr는 전이학습 vs scratch가 있다. 우리는 지금 전이학습을 한다. yolov3.pt
전이학습 하는 이유: pretrained weight는 어마어마한 양으로 학습한 애한테 가르치는 게 더 쉽기 때문. 지금 우리가 가진 custom data로만 한 것보다(음식만 하는) 것보다 의자,자전거 등 여러개를 배우고 온 애한테 배우는 게 더 쉽다.
그래서 전이학습을 한다.
-> 전이학습 할 떄 lr을 크게 주면? 기존에 해놓은 학습도 해칠 수가 있다.
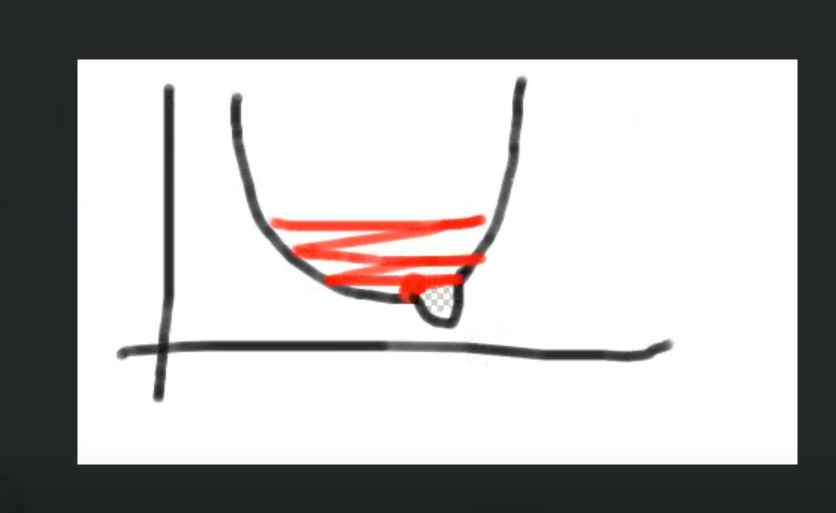
보통 전이학습을 할 떄는 원래 학습하던 것 lr의 1/10만 준다.
그래야지 저 작은 혹으로 들어갈 수 있다. (작은 혹: 우리 새로운 custom data로 인해 바뀐 형상, 우리가 가진 데이터는 전이학습의 데이터에 비하면 엄청엄청 작은 혹이다)
YOLO v3 는 기본이 0.01이다 -> 그러면 우리는 0.001로 해본다.
batch size : 64라고 하면 한번에 64장을 보는 것이다
예를 들어 batch size는 64, lr=0.01이 좋았다면?
batch size를 늘릴수록 trainnig 속도가 빨라지는 장점이 있어서 batchsize를 128로 늘렸다. lr도 2배인 0.02가 되어야 한다.
데이터가 2배로 늘었으니 보폭도 2배로 늘어야 한다.
최적의 lr을 찾는 게 데이터분석/머신러닝의 사명이다
팁: tmux Ctrl + B + PageUP과 Down하면 터미널창 스크롤 할 수 있다.
일단 batch size는 그대로 두고 learning rate를 여러개 주면서 정확도를 비교하자
4 epoch씩 학습하자.
lr 1 배 1/10배 1/2배 등등 여러 테스트를 해보자.
이제 optimizer도 바꾸고, scheduler도 바꿔보고, 최고로 높은 accuracy를 찾아가자.
일단 이번 프로젝트에서 우리가 할 건 이게 다!

optimizer

scheduler
그리고 학습 다 되면 거기서 받은 weight 로 inference 돌려보는 것도 해보기
epoch은 300이 기준이라는데..?? 몇으로 하나요?
이건 scratch 용일떄!
-> 우리는 전이학습이기 때문에 4~5epoch 최대 10 epoch 으로 한다.


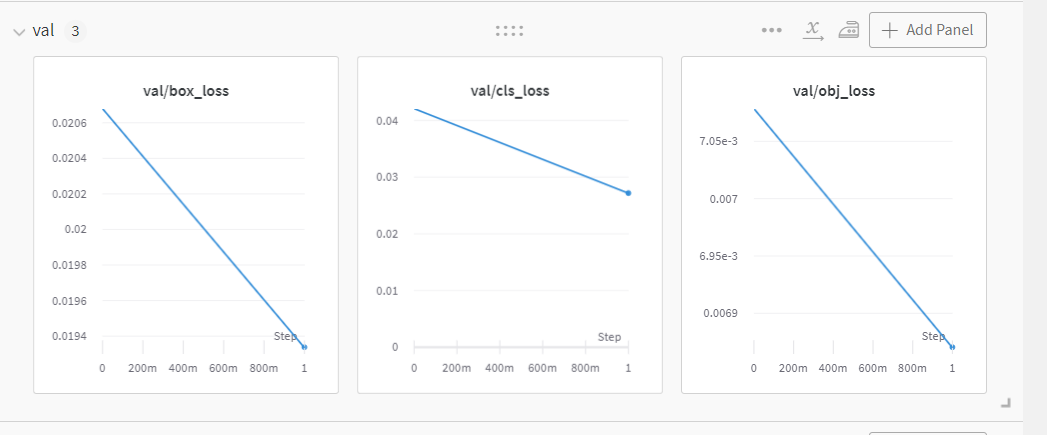

일단 2 epoch까지 됐을 때 wandb 결과!
wandb.init 찾기
batch size는 메모리가 부족하면 더 늘릴 순 없다 우린 현재 16인데 32로 더 늘릴 순 X