2022. 4. 24. 21:17ㆍ인턴/Quantization
딥러닝 모델 압축 방법론과 BERT 압축
딥러닝(Deep Learning)은 뛰어난 성능과 높은 모델의 확장성(Scalability)으로 인해 많은 주목을 받았고, 요즘 산업계에서도 활발하게 적용되고 있습니다. 하지만 모델의 높은 확장성은 또 다른 문제를
blog.est.ai
https://blogs.nvidia.co.kr/2020/02/20/bert/
End-to-End BERT: 만능 모델 BERT 학습부터 추론 - NVIDIA Blog Korea
자연어 처리 모델 버트(BERT)의 속도 향상을 위해 적용된 엔비디아 기술과 학습에서 추론에 이르는 전 과정에 대해 알아볼까요?
blogs.nvidia.co.kr
Network Compression과 BERT 모델
- 딥러닝 모델은 그 크기가 클 수록 성능이 향상되는 경향을 보여왔다. 컴퓨터비전 모델의 경우는 거대한 이미지 데이터셋을 이용해 미리 학습시키고 이를 특정 응용 분야에 맞춰 새로 학습(미세조정 또는 전이학습)하는 방식으로 거대한 모델을 감당했다. 그러나 자연어처리 분야는 순차데이터를 다루는 RNN을 사용하는데,
데이터가 길 수록 Gadient Vanishing 문제1
다음 입력 데이터 처리를 위해 이전 데이터가 필요하므로 병렬화가 어렵다는 문제2가 발생한다.
따라서 RNN 모델이 가진 한계로 인해 자연어처리에서는 컴퓨터비전만큼 모델을 거대화하기가 어렵다.
컴퓨터비전에서는 ImageNet에서 분류학습을 한 모델이 다른 분야에서도 필요한 특징을 잘 추출한 반면, 자연어 처리는 ImageNet만큼 거대한 데이터셋과 다른 분야에서 특징을 잘 뽑아내기 위한 사전학습방법이 잘 알려져 있지 않아, 이미 학습된 모델이 다른 분야에 활용되기가 어려웠다. 자연어 처리 분야에서 사전 학습은 거대한 말뭉치(Corpus)에서 단어 임베딩을 학습하여 재사용하는 정도에 그쳤다.
그러나 2018년에 BERT(Bidirectional Enocder Representations from Transformers)가 발표되며 자연어 처리 분야에서도 이처럼 거대한 모델의 사전학습-재학습이 가능해졌고, 성능도 다양한 문제에서 좋았다.
그래서 BERT는 현재 NLP 연구의 주류가 되었으며, 현재 NLP 연구는 거대한 모델을 만들고, 많은 데이터를 이용해 모델을 사전학습한 후 응용분야에 맞춰 재학습하는 접근방식을 취하고 있다.
딥러닝 모델이 커짐에 따라 발생하는 문제 4가지
1. Memory Limitation : BERT의 파생 모델들의 사이즈가 점점 커지면서 하나의 GPU에서 큰 모델을 학습하는 것이 점점 어려워지고 있다. 또한 자연어처리 분야에서 큰 배치사이즈가 학습에 효과적이라는 의견이 나오면서, 사전학습에 사용되는 배치크기가 점점 커지는 추세를 보이고 있고, 배치사이즈의 증가는 메모리에 큰 부담이 되고 있다.
2. Training/Inference Speed : 학습에 필요한 Gradient는 모델의 크기에 비례하기 때문에 분산 학습을 통해 학습속도를 올리더라도, 모델이 커짐에 따라 학습에 보다 많은 시간이 소요된다. 학습은 1번만 진행하므로 시간이 오래걸려도 괜찮지만 추론시간은 오래걸리면 서비스, 연구 시 문제가 된다.
3. Worse Performance : 위 같은 문제점을 해결하기 위해 분산학습을 진행한다. 데이터 병렬화, 모델 병렬화와 같은 방식으로 여러 개의 GPU를 사용한 학습으로 문제를 해결하려 했으나, 분산 학습으로 모델을 학습시켜도 여전히 문제가 남는다. 같은 데이터에서 단순히 모델 만을 키운다고 성능이 계속 증가하지는 않기 때문이다.
지나치게 큰 모델은 과적합 하기 쉽고, 이를 막기 위해서는 더 많은 데이터를 사용하거나 정규화를 도입해야 한다.
4. 실질적으로 GPU를 많이 쓰기 어려울 수 있다. : 분산 학습을 한다 하더라도 모델이 커짐에 따라 많은 GPU를 준비해야 하는 것은 비용적으로 작은회사/연구실/대학원 등 부담이 될 수 있다. 또한 모바일, 자동차 같은 환경에서는 휴대성, 전력소모로 인해 GPU 사용에 제한을 받는 등 실용적 문제가 있다. -> Model Compression
Model Compression의 6가지 접근 방법 (by Gordan)
1. Pruning 가지치기 : 학습 후 불필요한 부분을 제거하는 방식으로, 가중치의 크기에 기반한 제거, 어텐션 헤드 제거, 레이어 제거 등 여러 방법 사용. (layer dropout)
2. Weight Factorization 가중치 분해 : 가중치 행렬을 분해하여 두 개의 작은 행렬곱으로 근사하는 방법. 이 방법은 행렬이 낮은 랭크(RANK)를 가지도록 하는 제약조건이 도입됐다. 가중치 분해는 토큰 임베딩 / feed-forward / self-attention layer의 파라미터에 적용할 수 있다.
3. Weight Sharing 가중치 공유 : 모델의 일부 가중치들을 다른 파라미터와 공유하는 방식. 예를 들어 ALBERT는 BERT의 self-attention layer와 같은 가중치 행렬들을 사용하고 있다. (BERT보다 가볍고 처리속도가 높아짐)
4. Knowledge Distillation 지식 증류 : 미리 잘 학습된 큰 네트워크(Teacher Network)로부터 실제로 사용하고자 하는 작은 네트워크(Student Network)를 학습시키는 방법이다. 훨씬 작은 Transformer 모델을 pre-training / downstream-data에 대해 기본부터 학습시킨다. 원래대로라면 학습이 잘 안 되나, fully sized model의 값을 soft label로 사용하면 최적화가 더 잘 이루어진다. 몇몇 방법들은 추론 시간을 더 빠르게 하기 위해 BERT를 다른 형태의 모델(ex LSTM) 으로 증류하기도 한다.
5. Quantization 양자화 : 부동 소수점 값을 잘라내서 더 적은 비트만을 사용하는 방식. 양자화된 값은 학습 과정 중에 배울 수도 있고, 학습 후에 양자화될 수도 있다.
6. Pretrain vs Downstream : 일부 방법은 BERT를 특정 downstream task에만 맞게 압축하지만, BERT를 task와 무관하게 압축하는 방법들도 있다.
맨 위에 링크 건 첫 번쨰 블로그에 들어가면 다음과 같은 BERT 압축에 대한 다양한 방법 논문들에 대해 볼 수 있음.
다른 포스팅으로 작성하기. ALBERT, DistilBERT, MobileBERT, Q-BERT, LayerDrop, RPP 등..
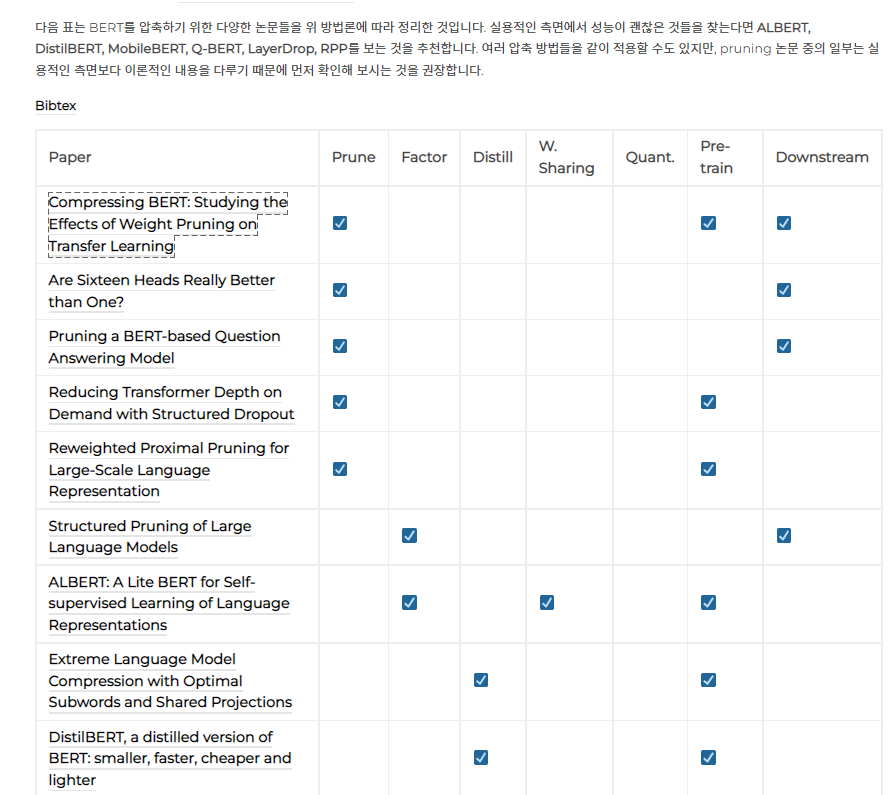
그 중에서도 눈여겨 볼 만한 논문 두 가지의 개요만 보자. ( 1 큰 모델압축률, 2 기존 pruning에 대한 문제제기와 새로운 연구제시 )
1. ALBERT
- 구글에서 2019년에 발표한 논문, 기존 BERT 압축을 위한 두 가지 parameter-reduction 방법과 pretrain 단계의 새로운 loss를 도입하는 것.
- ALBERT의 기본적인 아이디어는 'BERT의 파워는 컨텍스트를 고려한 hidden-layer embedding에서 나온다'는 것이다. 따라서 ALBERT에서는 컨텍스트 영향을 받지 않는(context-independent) WordPiece embedding의 크기를 줄이고, 이렇게 줄어든 크기로 hidden layer를 늘리는 방법을 사용한다.
- ALBERT에서 모델 압축을 위해 두 가지 방법을 사용함.
1-1 factorized embedding parameterization
- 기존 BERT는 각 WordPiece 별로 embedding을 만들어서 O(VtimesH) 크기의 embedding parameter를 가졌는데 이를 두 개의 행렬로 나누어 O(VtimesE + EtimesH)로 만들었다. 이를 통해 WordPiece embedding과 hidden layer size의 크기를 분리하고, hidden layer를 크게 만들 수 있었다.
1-2 cross layer parameter sharing
- ALBERT에서는 전체 layer들이 모든 (FFN, Attention) 파라미터를 공유한다. Hidden layer들의 파라미터가 공유되기 때문에 layer의 크기가 커지는 것의 부담을 줄이고, 네트워크 파라미터를 안정화시킬 수 있다.
-> 이러한 방법으로 ALBERT는 기존 BERT-large와 비슷한 설정에서 5% 정도의 파라미터를 가지고 1.7배 빠른 training이 가능토록 하였다.
2. THE LOTTERY TICKET HYPOTHESIS
- 2019년에 ICLR에 발표된 논문으로 lottery ticket 가설을 기반으로 효과적인 weight pruning 알고리즘을 제안하고 있다. lottery ticket 가설은 '가지치기를 통해 만들어진 모델은 처음부터 학습하기 어렵고, 원래 모델보다 낮은 정확도를 보인다' 는 기존 실험들의 -> '랜덤하게 초기화 된 fully connected에 convolution으로 구성된 네트워크를 같은 파라미터로 초기화하면 기존 모델보다 더 빨리 학습하고, 비슷하거나 보다 높은 정확도에서 훨씬 적은 파라미터로 구성된 모델이 존재'하게 된다는 것이다.
그래서 다음과 같은 알고리즘을 제안

저자들은 논문에서 Lenet, VGG variants, Resnet18을 대상으로 위 제안된 알고리즘을 이용해 파라미터를 원래 모델의 10~20% 정도로 줄였다. 이 결과는 위에서 언급한 ALBERT와 같은 가중치 pruning에 비하면 실용적인 측면에서는 아쉬울 수 있으나, 위 알고리즘은 일반적인 네트워크에 적용가능한 방법이고, 기존 모델 압축에 제기된 '왜 처음부터 작은 모델을 만들어서 학습하지 않고 큰 모델을 만들어 압축을 해야하는가'에 대한 가설을 제시하고 있다는 점에서 의의가 있다.
BERT가 무엇인지와 BERT의 압축(NVIDIA의 포스팅)
BERT 모델은 Bidirectional Encoder Representations from Transformers 의 약자로, 구글이 공개한 자연어 처리 모델이다. 기존의 SOTA(State of the Art) 모델이었던 ELMO(Embeddings from Language Model)의 성능을 크게 앞지르는 한편 Fine-tuning 만으로 범용적인 테스크에 모델을 적용할 수 있다는 가능성을 보여준 모델이다. 떄문에 오늘날 대부분의 자연어 처리 모델은 BERT를 기반으로 설계되고 있다.
하지만 BERT는 BERT-Large 모델을 Tesla V100 32G * 8 GPU 서버 한대로 pretraining 하면 약 2주간 학습을 해야하는 무거운 모델이다. 따라서 모델의 성능을 평가하고 향상시키는 과정을 감안했을 때 실제 BERT를 기반으로 서비스할 수 있는 모델을 구축하기에는 많은 비용과 시간이 필요하다.
또한 이렇게 무거운 모델을 바탕으로 서비스를 하는 것은 비용/반응속도 측면에서 실용적이지 못하여 BERT 모델의 크기를 줄이는 경우가 많고, 불가피하게 모델의 성능을 저하시키게 된다.
그래서 NVIDIA 사에서 BERT모델을 많은 사람들이 쉽게 사용하도록 모델을 최적화하고 이와 관련된 코드를 공개해왔다.따라서 동일한 조건에서 10일 이내로 학습 시간을 단축시킬 수 있으며 분산학습까지 적용하면 3시간 이내에 BERT를 학습하게 할 수 있다. 또한 BERT-Base모델을 기준으로 약 2.2ms의 지연시간으로 추론을 할 수 있어,
모델의 성능 저하 없이 효과적으로 BERT를 사용할 수 있다.
현 포스팅은 위와 같은 BERT 모델의 속도 향상을 위해 적용된 기술에 대해 소개하고, 학습에서 추론에 이르는 전 과정에 대한 실습 수준의 튜토리얼 설명을 적겠다. 이 내용을 바탕으로 BERT 모델의 학습과 서비스를 개발하면 개발 기간 단축과 함께 서비스 응답 속도 향상 및 모델 성능을 향상시킬 수 있다.
특히 NVIDIA는 BERT의 training, inference 시간 개선을 위한 기술들을 적용하고 있다.
(포스팅 작성하기)
NVIDIA의 BERT 모델 training 관련 코드 : https://github.com/NVIDIA-Korea/deeplearningexamples/blob/master/TensorFlow/LanguageModeling/BERT/notebooks/BERT_Training.ipynb
GitHub - NVIDIA-Korea/deeplearningexamples: NVIDIA BERT from Training to TensorRT inference example
NVIDIA BERT from Training to TensorRT inference example - GitHub - NVIDIA-Korea/deeplearningexamples: NVIDIA BERT from Training to TensorRT inference example
github.com
NVIDIA BERT 모델 inference 관련 코드 : https://github.com/NVIDIA-Korea/deeplearningexamples/blob/master/TensorFlow/LanguageModeling/BERT/notebooks/bert_squad_trt_inference_with_trtis.ipynb
GitHub - NVIDIA-Korea/deeplearningexamples: NVIDIA BERT from Training to TensorRT inference example
NVIDIA BERT from Training to TensorRT inference example - GitHub - NVIDIA-Korea/deeplearningexamples: NVIDIA BERT from Training to TensorRT inference example
github.com
학습 최적화 기술(Training 시간 감축)
1. Horovod 기반의 Multi-GPU 학습 : Horovod는 텐서플로우, 케라스, 파이토치, MXNet의 딥러닝 프레임워크에서 Multi-GPU를 활용한 분산학습을 지원하는 프레임워크이다. 특히 NVIDIA의 NCCL(NVIDIA Collective Comuunications Library)를 사용하여 효율적인 Multi-GPU 학습환경을 제공
2. AMP 학습 : Automatic Mixed Precision의 약자로, 텐서 코어는 Mixed precision 기반의 GEMM(General Matrix-to-Matrix Multiplication) 연산을 가속화하는 모듈로써 Volta 아키텍처부터 지원된다.
따라서 학습 시 Mixed precision 학습을 수행하게 될 경우 텐서 코어를 활용하여 학습 성능을 높일 수 있다.
이러한 Mixed Precision 학습을 보다 쉽고 편리하게 제공하기 위해서 NVIDIA는 AMP 기법을 제공하는데 특히 NGC에서 제공하는 텐서플로우는 추가적인 소스 코드변경 없이 Loss Scaling을 수행하여 학습시간을 단축해준다.
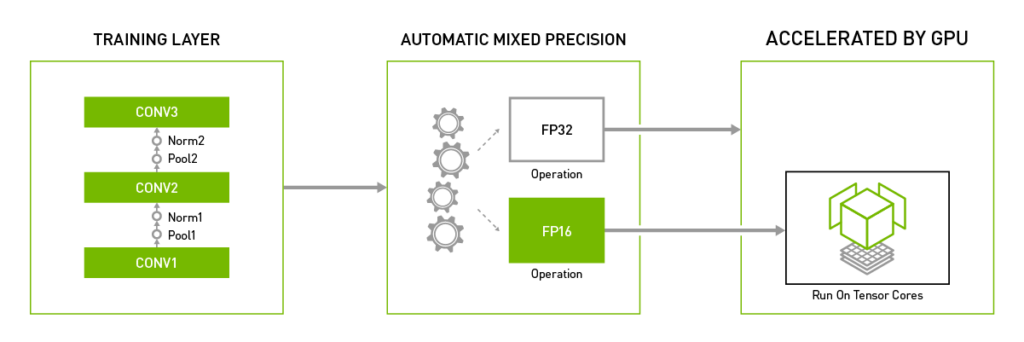
3. LAMB(Layer wise Adaptive Moments based optimizer for Batch)
LAMB는 BERT 모델의 Large 배치 최적화 기법으로 LARS(Layer-wise Adaptive Rate Scaling)기법과 Adam Optimizer를 확장한 기법이다. lr을 안정적으로 높일 수 있기 때문에 학습시간을 100배 가량 단축시킬 수 있는 Optimizer이다.
NVIDIA는 Gradient Pre-normalization과 Bias correction 추가한 별도의 LAMB를 적용하여 학습 속도를 더욱 가속시킴.
추론 최적화 기술(Inference 시간 감축)
1. TensorRT
TensorRT는 NVIDIA에서 추론하려는 딥러닝 모델을 GPU에 최적화해주는 소프트웨어이다. 자세한 것은 이전 포스팅에서 설명
2. TRTIS(TensorRT Inference Server) : TRTIS는 학습된 딥러닝 모델을 효율적으로 서빙하기 위한 플랫폼으로서 TensorRT 뿐만 아니라 다양한 딥러닝 프레임워크의 모델을 이용한 추론을 가능하게 한다. 또한 어플리케이션에 따라 다양한 스케쥴러를 제공하고, multi model에 대해서도 Multi GPU 추론을 제공하기에 서버에서 효율화 된 서빙 플랫폼을 구축할 수 있게 해준다.
BERT 모델의 학습과 추론의 성능 개선
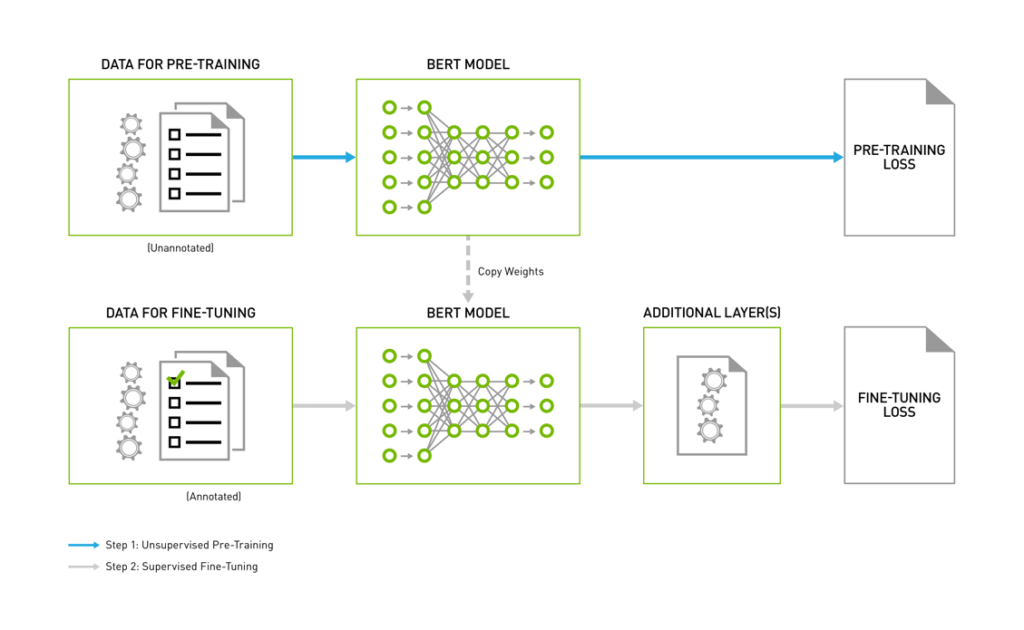
BERT 모델의 학습과정은 크게 Pre-training 단계와 Fine-tuning 단계로 구분된다.
Pre-training 단계에서는 방대한 데이터셋으로부터 언어와 문장 자체에 대한 이해도를 높이고,
Fine-tuning 단계에서는 Pre-trained 된 파라미터들을 Downstream 하여 특화된 작업을 처리할 수 있게 한다.
NVIDIA의 BERT 모델 학습 4단계 튜토리얼
1. 학습 환경 구성
2. 데이터셋 다운로드 및 TFRecordSet 구성
3. Pre-training 단계
4. Fine-tuning 단계
1. 학습환경 구성
- 도커 이미지 생성,빌드 CUDA 10.1, 텐서플로우 1.14.0 기반
2. 데이터셋 다운로드 및 TFRecordSet 구성
- Pre-training 시 사용할 데이터셋 구성 : BookCorpus 과 wikicorpus_en 데이터셋을 합치고 TFRecordSet으로 만듦.
그리고 Fine-tuning 시 SQuAD, GRUE 데이터셋을 다운로드.
data_datasets_from_start.sh와 create_datasets_from_start.sh는 TFRecodset 생성시 BERT 모델의 파라미터인 max_seq_length와 max_predictions_per_seq 설정에 주의해야 한다. 생성된 파라미터에 따라 BERT 모델의 input이 달라지기 때문에 학습할 BERT 모델의 파라미터를 고려해서 설정해야 한다.
3. Pre-training 단계
- BERT 모델은 언어 표현을 위해 Bidirectional Representations을 pre-training하게 디자인되었다. 엔비디아 튜토리얼에서는 wikipedia와 BookCorpus 문장을 기반으로 언어 표현을 이해하기 때문에 추가로 pre-training하고 싶은 문장이 있으면 데이터셋을 다운로드 하고 TFRecordSet을 구성한 뒤 진행.
NVIDIA는 pre-training을 위한 두 개의 optimizer (LAMB/Adam)을 이용한 학습 스크립트를 제공한다.
4. Fine-tuning 단계
- 기존의 Pre-trained BERT 모델에 하나의 최종 출력 레이어를 추가하여 Q&A 시스템문제, GLUE Benchmark 뿐 아니라 다양한 NLP 작업을 수행할 수 있다.
NVIDIA의 BERT 학습 모델 성능 향상
단일 노드에서 Pre-training 단계에서의 Mixed Precision을 비교(DGX-1이 전, DGX-2가 학습(training) 최적화 후)
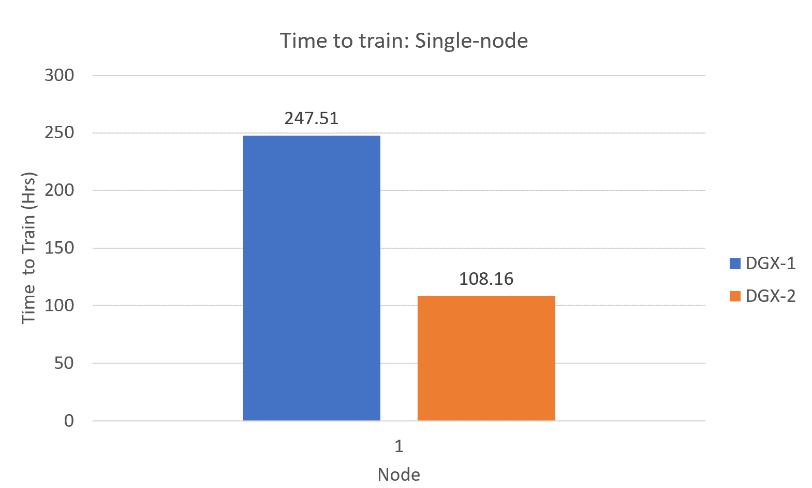
다중 노드(DGX-2H로 구성된 노드)에서 Pre-training 단계에서의 Single Precision과 Mixed Precision 학습 시간 비교(DGX-1이 전, DGX-2H가 학습(training) 최적화 후)
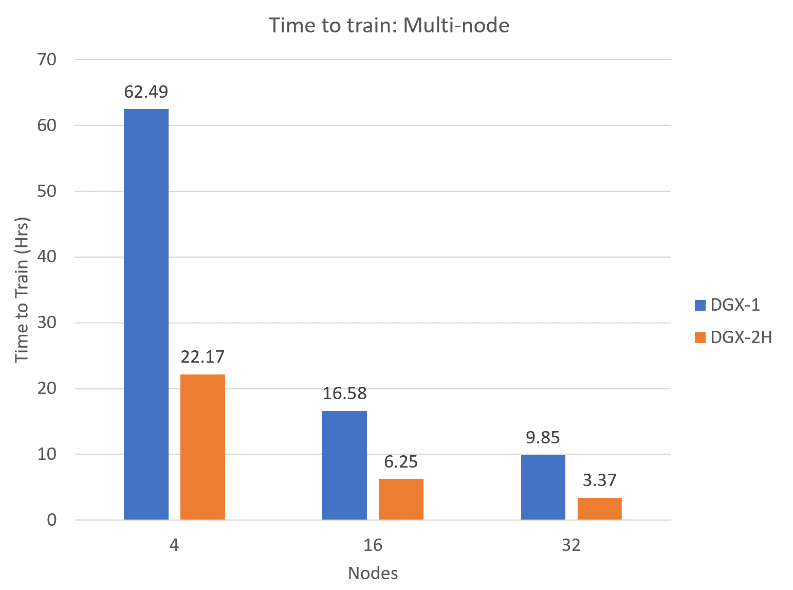
학습 시간을 3시간 이내로, 더 많은 GPU나 노드를 사용하면 학습시간을 더 빠르게 단축시킬 수 있음.
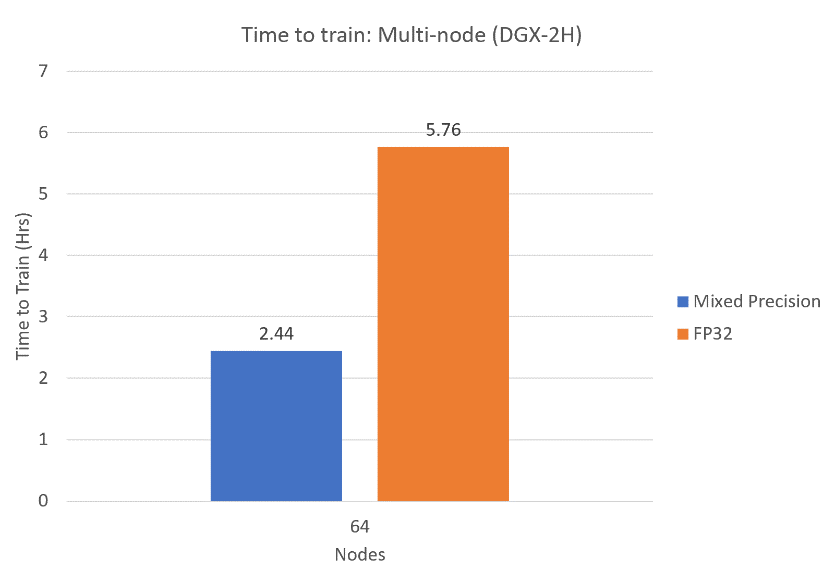
여기에 Mixed Precision까지 도입하면 더 속도가 향상됨.
TensorRT를 통한 BERT 모델 추론 최적화
아래는 TensorRT 최적화를 위한 BERT Encoder 레이어 구성이다.
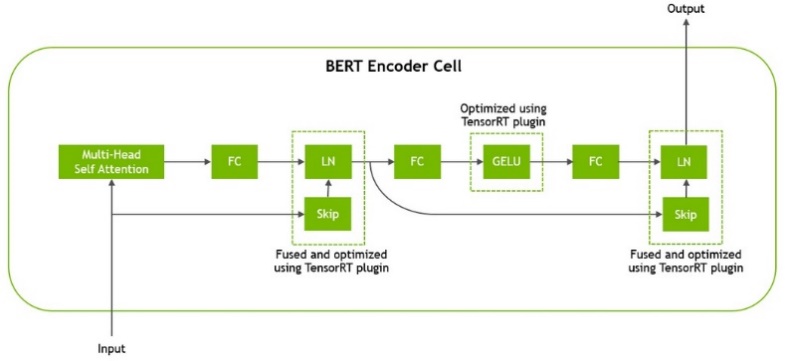
이렇게 압축한 모델은 기존의 모델을 대체하여 추론할 수 있으며, Pre-Processing과 Post-Processing 사이에서 기존의 구조를 그대로 사용할 수 있다.

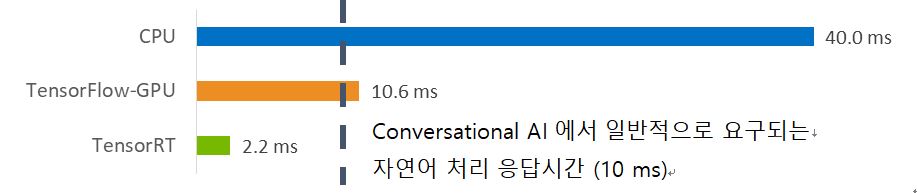
이렇게 TensorRT로 최적화한 모델은 최적화 없이 CPU 또는 텐서플로우로 돌린 결과를 비교해보았을 때 TensorRT를 적용한 경우 응답속도가 크게 향상된 것을 확인할 수 있다.
TensorRT Inference Server를 이용한 inference 서빙 플랫폼 구축
-BERT 모델을 기반으로 Q&A 서비스를 하기 위해 Server/Client 구조로 서빙 환경을 구축하는 방법을 알아보자
우선 사용자의 요청 및 context에 처리에 관한 처리를 하는 Pre-Processing/Post-Processing은 클라이언트로 두고, Model 서빙에 대해서는 TensorRT Inference Server에서 처리하게 한다
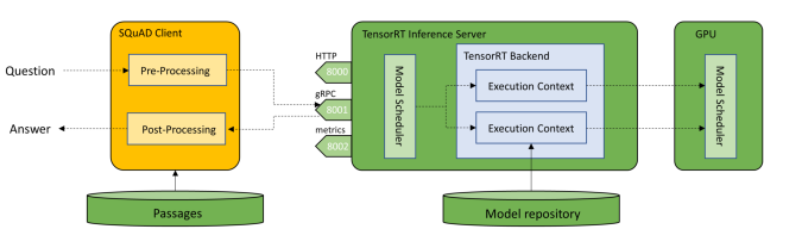
이렇게 구성하면 모델 서버는 모델의 추론만 관리하면 되므로 효율적인 플랫폼이 될 수 있다. 또한 클라이언트 구현 시 학습을 위해 쓴 코드를 재사용할 수 있다.
또한 BERT TensorRT 엔진의 batch size를 1로 구성했다고 해도 GPU의 용량에 따라 사용자가 증가해도 scalable한 플랫폼을 만들 수 있다는 장점이 있다.
'인턴 > Quantization' 카테고리의 다른 글
| 22.04.26 Quantization (0) | 2022.04.27 |
|---|---|
| 22.04.12 Deep Learning - Quantization (0) | 2022.04.24 |
| 22.04.11 tensorRT에 쓰이는 개념들 - 빨간글씨 꼭 읽어보기 (1) | 2022.04.12 |