2022. 4. 24. 19:02ㆍ인턴/Quantization
https://wooono.tistory.com/405
[DL] 양자화(Quantization)란?
들어가기 앞서, 모바일이나 임베디드 환경에서, 딥러닝 모델을 사용한 추론은 어렵습니다. 일반 PC 와 달리, 메모리, 성능, 저장공간 등의 제한이 있기 때문입니다. 따라서, 딥러닝에서는 모델 경
wooono.tistory.com
딥러닝 시 경량화 연구가 시작된 이유
- 모바일이나 임베디드 환경에서 딥러닝 모델을 사용한 추론은 어렵다.(메모리, 성능, 저장공간 등의 제한이 있기 때문)
- 그래서 딥러닝 모델을 가볍게 만드는 연구가 시작됨.
딥러닝 경량화 연구
크게 두 가지로 나뉨
1. 모델을 구성하는 알고리즘 자체를 효율적인 구조로 설계
2. 기존 모델의 파라미터들을 줄이거나 압축하는 연구
1. 모델을 구성하는 알고리즘 자체를 효율적인 구조로 설계
1-a. 모델 구조 변경(ResNet, DenseNet, SqueezeNet 등)
1-b. 효율적인 합성곱 필터 기술(채널을 분리시켜 연산량과 변수의 개수를 줄여 경량화. MobileNet, ShuffleNet..)
1-c. 경량 모델 자동 탐색 기술(자동 탐색 기법을 사용해 경량화할 수 있는 모델 구조와 합성곱 필터를 설계하는 방법(NetAdapt, MNAsNet 등)
2. 기존 모델의 파라미터들을 줄이거나 압축하는 연구
2-a. 가중치 가지치기(Weight Pruning)
- 결과에 영향을 미치는 파라미터들을 제외한 나머지 파라미터들을 0으로 설정
2-b. 양자화(Quantization)
- 부동소수점으로 표현되는 파라미터들을 특정 비트 수로 줄이는 방법
2-c. 이진화(Binarization)
- 파라미터들을 이진화함으로서 표현력은 줄어들지만 정확도의 손실은 최소로 하는 경량화 방법(ex -1과 1로만 표현)
그 중에서도 양자화(Quantization)에 대해 알아보자
양자화
- NN 모델 내부는 대부분 weight와 activation output으로 이뤄짐
- weight와 activation output은 모델의 정확도를 높이기 위해 32bit floating point(FP32)로 표현되고 있음.
- 32 bit floating point

- 전체적인 구조

- 리소스가 제한된 환경에서 모든 weight와 activation output을 32bit FP로 표현하는 모델은 추론에 사용하기 어려움
- 따라서 양자화는 weight와 activation output 표현에 사용되는 비트 수를 줄임으로써, 모델의 크기를 줄이는 것을 의미
- 기존 모델보다 성능은 떨어질 수 있지만, 모델의 크기가 줄어들어 제한된 리소스 환경에서도 사용할 수 있다.
양자화의 주 목적
- training 시간을 줄이는 것이 아닌 inference 시간을 줄이는 것이 목표이다.
양자화 예제
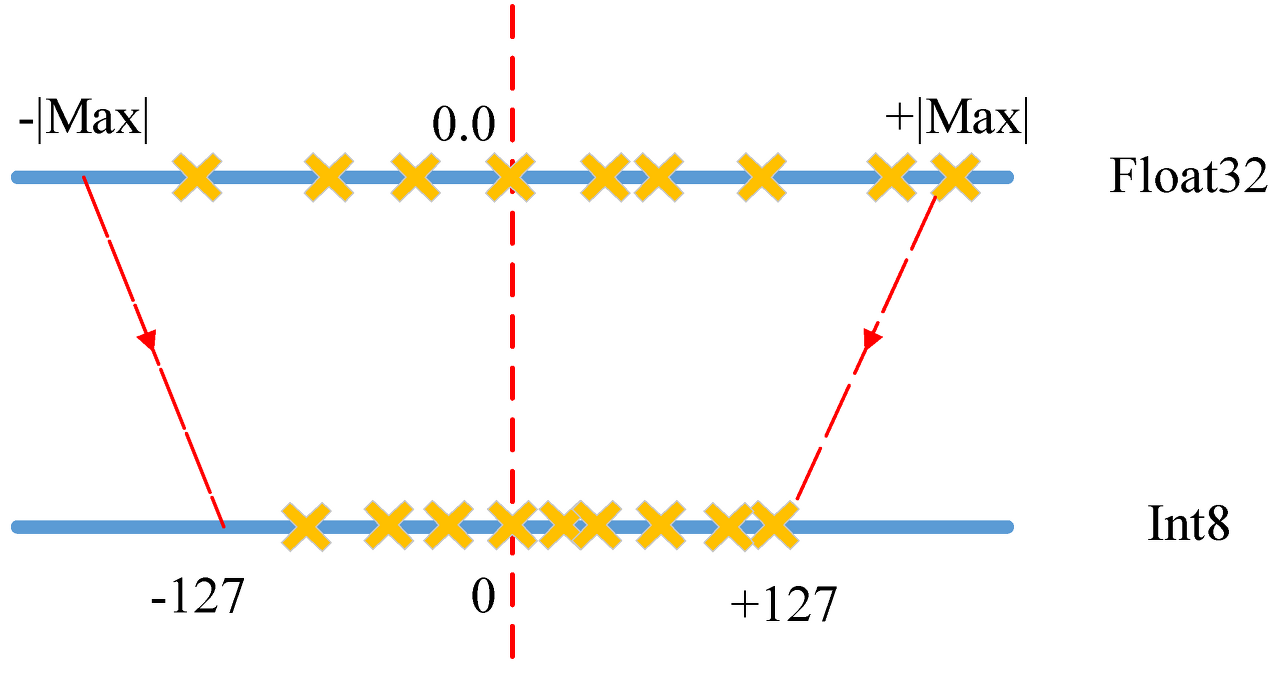
- 각 계층의 소수값(float32) 중 최소/최대 값을 구한다
- 해당 소수값(float32)들을 선형적으로 가장 가까운 정수(int8)에 매핑한다.
( 예를 들어 기존 소수값 범위가 -3.0~6.0이라면 -3.0은 -127로, 6.0은 +127로 매핑 )
- 이 방식을 사용하면 32bit로 표현되는 weight를 적은 bit로 표현할 수 있으므로 메모리 감소 효과를 볼 수 있다.
양자화 종류
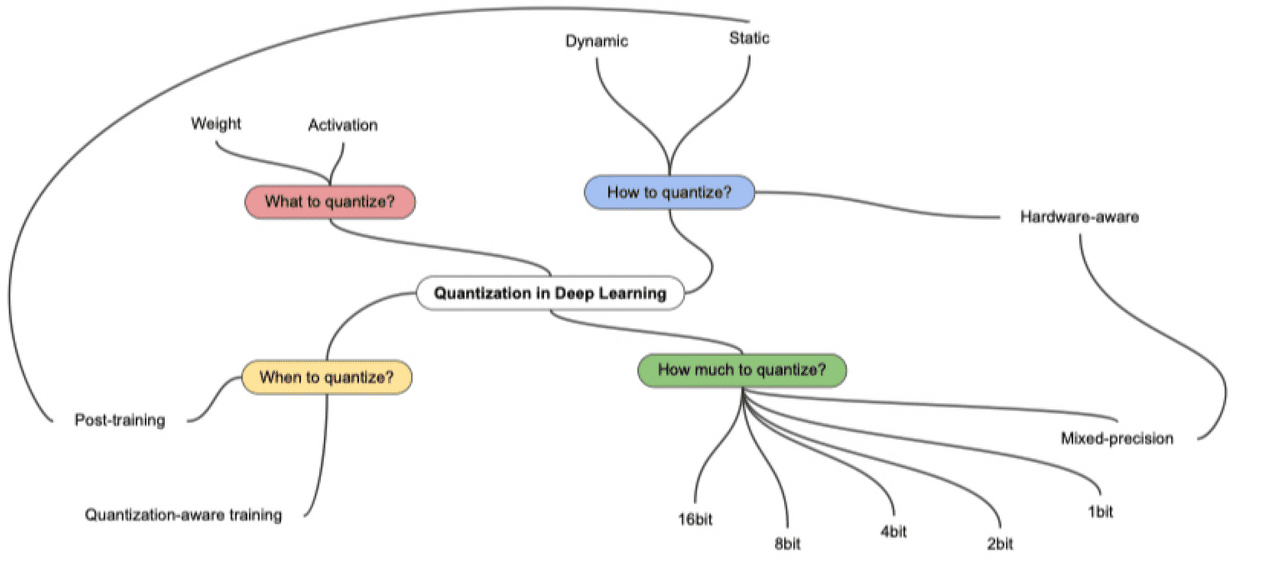
언제 Quantization?
- Quantization Aware Training : FP 모델로 학습하는 과정에서 Quantization하는 것
- Post Training Quantization : FP 모델로 학습한 후에 Quantization 하는 것
어떻게 Quantization?
- Dynamic : FP 모델로 학습한 뒤, weight만 Quantization하고 있다가 inference 시점에 동적으로 activation을 Quantization 하는 것
무엇을 Quantization?
- weight
- activation
얼마나 Quantization?
- 16bit, 8bit, 4bit, 2bit, 1bit, mixed-precision
'인턴 > Quantization' 카테고리의 다른 글
| 22.04.26 Quantization (0) | 2022.04.27 |
|---|---|
| 22.04.12 Deep Learning - BERT 모델 Network Compression(하늘색 글씨 포스팅쓰기) (0) | 2022.04.24 |
| 22.04.11 tensorRT에 쓰이는 개념들 - 빨간글씨 꼭 읽어보기 (1) | 2022.04.12 |