2022. 3. 19. 16:54ㆍ작업/RNN
LSTM( Long Short Term Memory ) - RNN 모델
- Vanilla RNN의 기울기 소실 문제를 해결하고자 등장.
- 장기 의존성과 단기 의존성을 모두 기억할 수 있다는 뜻이다. Long Short
- 새로 계산된 hidden state를 출력값으로도 사용한다.

- Ct = Cell State ( 기울기 소실 장치를 해결하기 위한. 장기적으로 기억할 정보를 저장한다.
예를 들어 앞 단어와 맨 뒤에 오는 단어가 연관이 있다, 그 다음 문장과는 연관이 없다 등등)
- Wf, Wi, Wc,Wo = Gate (3종류의 게이트를 4개의 FC Layer Wf, Wi, Wc, Wo가 구성한다.)
1. 망각게이트 Wf : 기존 cell state에서 어떤 정보를 잊을지 결정
concatenate : 합친다, 시그모이드 함수(0~1사이 활성화?함수)


2. 입력게이트 Wi, Wc : 어떤 것을 cell state에 저장할지 결정
tanh 함수(활성화함수)
C~t : cell state에 저장될 정보 중 일부라서 이렇게 표현.

그래서 Forget Gate의 결과인 ft와 Input Gate의 결과 it, C~t를 이용해 cell state를 갱신한다. 즉 Ct를 결정

여기서 x 곱셈은 벡터들간의 곱셈이라 사칙연산곱셈은 아닌 느낌(Hadamard Product)
같은 성분끼리의 곱?
3. 출력 게이트 Wo : 다음 hidden state와 출력값을 계산한다.(이때 새로 계산된 cell state = Ct를 사용한다)
ht-1과 xt를 concatenate한 다음 네번째 FC인 Wo에 전달하고, 그걸 활성화함수인 sigmoid를 적용해서 ot를 뽑아낸다.
그리고 새로 계산된 Ct에 tanh를 적용해서 그 둘을 product하여 ht = yt를 만든다.
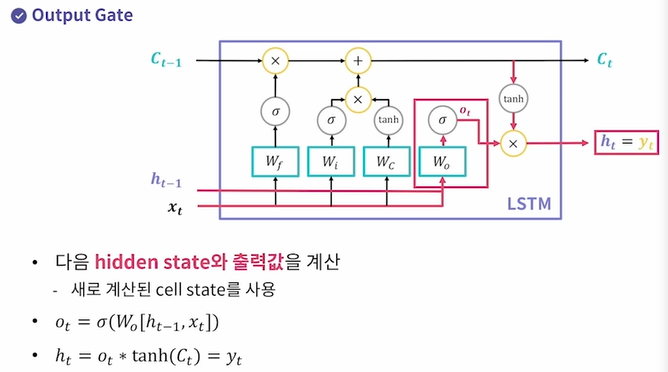
이렇게 Vanilla RNN의 단점을 보완한 구조가 LSTM이므로 Vanill RNN 대신 LSTM으로 바꿔끼기만 하면 단점은 보완하고 원하는 input output은 똑같이 동작한다.
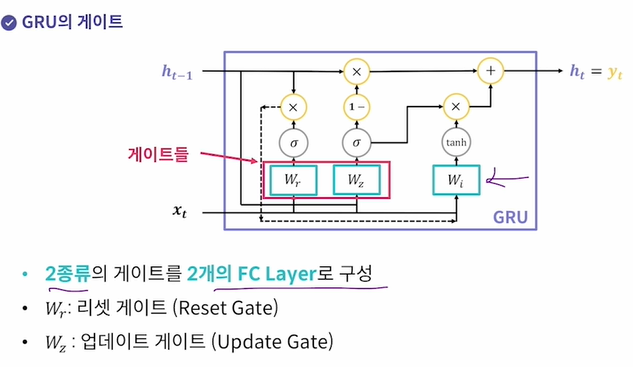
GRU( Gated Recurrent Unit ) - LSTM을 또 개량한 모델
LSTM은 3종류 게이트였는데 그걸 2종류로 줄이고 cell state를 없앴다.
Wr, Wz ( 리셋게이트, 업데이트게이트가 존재)
따라서 LSTM보다 파라미터 수 ↓ 학습속도 ↑ 성능은 비슷
LSTM과 마찬가지로 새로 계산된 hidden state를 출력값에 사용함.
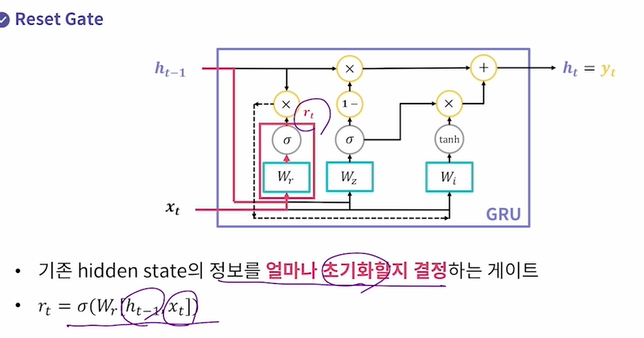
Reset Gate : 기존 hidden state의 정보를 얼마나 초기화할지 결정하는 게이트이다.
이전 hidden state와 xt를 concatenate시키고, 그것을 Reset Gate의 FC layer인 Wr에 통과, sigmoid를 적용시켜서 아웃풋인 rt를 만든다.
Update Gate : 기존 hidden state의 정보를 얼마나 사용할지 결정

이제 이렇게 Reset, Update gate의 결과물로 새로운 hidden state의 후보를 계산한다.

rt x ht-1 이 저 점선을 따라 후보군으로 등록되고 Wi와 tanh를 거쳐 후보인 h~t가 마련된다.
그리고 마지막으로 Update Gate의 결과 zt를 다음과 같은 수식을 가지고 계산해서 최종 ht를 만든다.
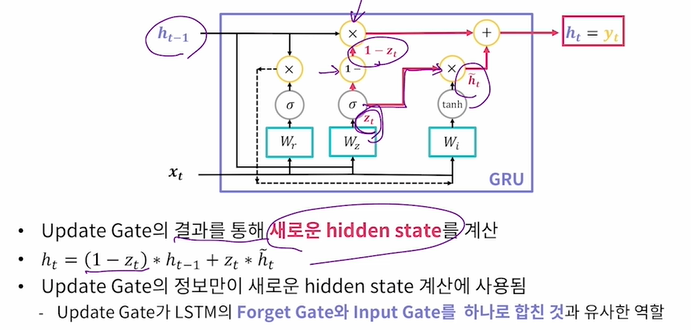
즉, 이전 ht-1과 h~t의 가중치(zt)를 조절해서 무엇을 더 많이 사용할 것인지를 결정한다..!
GRU = LSTM = Vanilla RNN인데 각 단점들을 보완한 구조들이다~!
RNN 모델 활용
자 그럼 지금까지 RNN을 기반으로 한 모델(LSTM, GRU)의 간단한 계산 원리를 알아보았다.
지금부터는 RNN 모델들이 어떤 작업에 활용되는지 알아보자.
RNN/LSTM/GRU 모델은 회귀분석 과 분류작업 에 모두 활용될 수 있다.
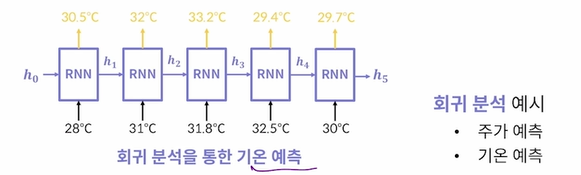
회귀 분석: 각 시점의 출력값이 몇일지 예측(다음 달의 기온) - mse 사용
분류 작업: 각 시점의 데이터가 어느 class일지 예측(love가 명사냐 동사냐 형용사냐 / 슬픈 리뷰, 좋은 리뷰) - cross entropy 사용
최종적으로 회귀분석, 분류를 하기 위해서는 모델을 학습시켜야 하고, 그 학습은 손실함수(loss function) 계산으로 이루어진다.
loss = 모델의 pred - 실제정답
CNN은 pred가 마지막에 하나만 나오지만, RNN은 각 시점별(x1,x2,x3..) 로 pred(y^1, y^2, y^3..)가 따로따로 나오게 된다.
따라서 loss들도 시점마다 나온다. L1, L2, L3..

이때 저 f가 loss function이다. 회귀분석에서는 주로 MSE(Mean Squared Error)를, 분류에서는 cross entropy를 사용한다.
회귀분석 예시 - 시계열 데이터의 다음 시점을 예측?
분류 작업 예시 - CNN처럼 이미지보고 이게 강아지다, 고양이다 하는 게 아니라 시점별로 나오는 단어들, 순서가 있고 서로 연관이 있는 그런 데이터(순차데이터) 들을 가지고 한 시점의 단어의 품사를 예측하거나, 다음에 올 단어를 예측하는 등을 한다.
( It - is, was 등 올만한 단어를 예측하는 것도 분류라고 한다)
( It이 들어오면 대명사, was 는 동사..)

실습1 장기의존성 문제 확인
기존의 Vanilla RNN은 시계열 데이터와 같은 순차 데이터의 경향성을 학습하는데 좋으나, 데이터의 길이(=sequence)가 길면 맨 앞 시점과 뒤에나오는 시점 거리가 멀어지면(문장이 너무 길면) back propagation 되는 기울기 값이 점점 0에 수렴하는 기울기 소실(gradient vanishing)이 생겨서 길이가 긴 시계열 데이터에서 장기 의존성을 판단하기가 어려워진다. (연관이 있는지 없는지..?)
그 문제가 실제로 나타나는지 1980년~1990년 멜버른 지역의 최저기온 데이터셋을 통해 Vanilla RNN의 장기의존성 이슈를 확인하고, 이를 보완한 LSTM과 GRU에서는 성능이 어떻게 나오는지 비교를 한다.

전체 길이가 10 = sequence 길이가 10 = 시점이 10개 = x1,x2,x3,x4...x9,x10 그럭저럭 의존성 잘찾음
전체 길이가 300 = 과연 Vanilla RNN이 맨앞단어와 맨뒤단어 연관을 볼 수 있을까?
window size 가 10 인 경우(장기의존성문제크지X)와 300인 경우(장기의존성O)를 모두 보고, 모델별로 MSE 점수가 어떻게 나오는지 확인하자.
(10일치 데이터 vs 300일치 데이터)




import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import pandas as pd
import numpy as np
#---------------------window size 설정 및 데이터전처리-------------------------------
def load_data(window_size):
raw_data = pd.read_csv("./daily-min-temperatures.csv")
raw_temps = raw_data["Temp"]
mean_temp = raw_temps.mean()
stdv_temp = raw_temps.std(ddof=0)
raw_temps = (raw_temps - mean_temp) / stdv_temp
X, y = [], []
for i in range(len(raw_temps) - window_size):
cur_temps = raw_temps[i:i + window_size]
target = raw_temps[i + window_size]
X.append(list(cur_temps))
y.append(target)
X = np.array(X)
y = np.array(y)
X = X[:, :, np.newaxis]
total_len = len(X)
train_len = int(total_len * 0.8)
X_train, y_train = X[:train_len], y[:train_len]
X_test, y_test = X[train_len:], y[train_len:]
return X_train, X_test, y_train, y_test
#---------------------Vanilla RNN---------------------------------------
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] Simple RNN과 Fully-connected Layer로 구성된 모델을 완성하세요.
model.add(layers.SimpleRNN(128, input_shape=(window_size, 1)))
model.add(layers.Dense(32, activation='relu')) # 표현력 높이기 위해 Dense 하나 더 추가
model.add(layers.Dense(1)) # 값 하나만 뽑으면 되니까 node 갯수 1개
return model
#-------------------LSTM------------------------------------------
def build_lstm_model(window_size):
model = Sequential()
# TODO: [지시사항 2번] LSTM과 Fully-connected Layer로 구성된 모델을 완성하세요.
model.add(layers.LSTM(128, input_shape=(window_size,1))) #hidden state크기128, input_shape
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
return model
#---------------------GRU------------------------------------------
def build_gru_model(window_size):
model = Sequential()
# TODO: [지시사항 3번] GRU와 Fully-connected Layer로 구성된 모델을 완성하세요.
model.add(layers.GRU(128, input_shape=(window_size, 1)))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=10, model_name=None):
# TODO: [지시사항 4번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 5번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=64, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
return test_loss, optimizer, hist
def main(window_size):
tf.random.set_seed(2022)
X_train, X_test, y_train, y_test = load_data(window_size)
rnn_model = build_rnn_model(window_size)
lstm_model = build_lstm_model(window_size)
gru_model = build_gru_model(window_size)
rnn_test_loss, _, _ = run_model(rnn_model, X_train, X_test, y_train, y_test, model_name="RNN")
lstm_test_loss, _, _ = run_model(lstm_model, X_train, X_test, y_train, y_test, model_name="LSTM")
gru_test_loss, _, _ = run_model(gru_model, X_train, X_test, y_train, y_test, model_name="GRU")
return rnn_test_loss, lstm_test_loss, gru_test_loss
if __name__ == "__main__":
# 10일치 데이터를 보고 다음날의 기온을 예측합니다.
rnn_10_test_loss, lstm_10_test_loss, gru_10_test_loss = main(10)
# 300일치 데이터를 보고 다음날의 기온을 예측합니다.
rnn_300_test_loss, lstm_300_test_loss, gru_300_test_loss = main(300)
print("=" * 20, "시계열 길이가 10 인 경우", "=" * 20)
print("[RNN ] 테스트 MSE = {:.5f}".format(rnn_10_test_loss))
print("[LSTM] 테스트 MSE = {:.5f}".format(lstm_10_test_loss))
print("[GRU ] 테스트 MSE = {:.5f}".format(gru_10_test_loss))
print()
print("=" * 20, "시계열 길이가 300 인 경우", "=" * 20)
print("[RNN ] 테스트 MSE = {:.5f}".format(rnn_300_test_loss))
print("[LSTM] 테스트 MSE = {:.5f}".format(lstm_300_test_loss))
print("[GRU ] 테스트 MSE = {:.5f}".format(gru_300_test_loss))
print()
LSTM, GRU는 시계열 길이가 길어도 길이가 적을 때보다 크게 성능하락이 있지 않다.
실습2 LSTM으로 IMDb데이터 학습 (영화 리뷰의 긍정/부정 분류)

num_words = 6000
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
def load_data(num_words, max_len):
# TODO: [지시사항 1번] IMDB 데이터셋을 불러오세요.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
return X_train, X_test, y_train, y_test
def build_lstm_model(num_words, embedding_len):
model = Sequential()
# TODO: [지시사항 2번] LSTM 기반 모델을 구성하세요.
model.add(layers.Embedding(num_words, embedding_len))
model.add(layers.LSTM(16))
model.add(layers.Dense(1,activation='sigmoid'))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=5):
# TODO: [지시사항 3번] 모델 학습을 위한 optimizer, loss 함수, 평가 지표를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# TODO: [지시사항 4번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=128, shuffle=True, verbose=2)
# 모델을 테스트 데이터셋으로 테스트합니다.
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 loss: {:.5f}, 테스트 정확도: {:.3f}%".format(test_loss, test_acc * 100))
return optimizer, hist
def main():
tf.random.set_seed(2022)
num_words = 6000
max_len = 130
embedding_len = 100
X_train, X_test, y_train, y_test = load_data(num_words, max_len)
model = build_lstm_model(num_words, embedding_len)
run_model(model, X_train, X_test, y_train, y_test)
if __name__ == "__main__":
main()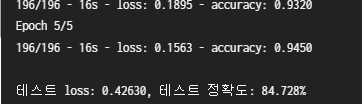
실습3 GRU를 통한 항공 승객 수 분석
항공 승객 수는 자연어데이터가 아닌 시계열데이터니까 임베딩작업까지는 필요 없음.
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def load_data(window_size):
raw_data = pd.read_csv("./airline-passengers.csv")
raw_passengers = raw_data["Passengers"].to_numpy()
# 데이터의 평균과 표준편차 값으로 정규화(표준화) 합니다.
mean_passenger = raw_passengers.mean()
stdv_passenger = raw_passengers.std(ddof=0)
raw_passengers = (raw_passengers - mean_passenger) / stdv_passenger
plot_data = {"month": raw_data["Month"], "mean": mean_passenger, "stdv": stdv_passenger}
# window_size 개의 데이터를 불러와 입력 데이터(X)로 설정하고
# window_size보다 한 시점 뒤의 데이터를 예측할 대상(y)으로 설정하여
# 데이터셋을 구성합니다.
X, y = [], []
for i in range(len(raw_passengers) - window_size):
cur_passenger = raw_passengers[i:i + window_size]
target = raw_passengers[i + window_size]
X.append(list(cur_passenger))
y.append(target)
# X와 y를 numpy array로 변환합니다.
X = np.array(X)
y = np.array(y)
# 각 입력 데이터는 sequence 길이가 window_size이고, featuer 개수는 1개가 되도록
# 마지막에 새로운 차원을 추가합니다.
# 즉, (전체 데이터 개수, window_size) -> (전체 데이터 개수, window_size, 1)이 되도록 변환합니다.
X = X[:, :, np.newaxis]
# 학습 데이터는 전체 데이터의 80%, 테스트 데이터는 20%로 설정합니다.
total_len = len(X)
train_len = int(total_len * 0.8)
X_train, y_train = X[:train_len], y[:train_len]
X_test, y_test = X[train_len:], y[train_len:]
return X_train, X_test, y_train, y_test, plot_data
def build_gru_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] GRU 기반 모델을 구성하세요.
model.add(layers.GRU(4, input_shape=(window_size, 1))) # hidden state 갯수 4, 임베딩안쓰니까 input_shape정해주기.
model.add(layers.Dense(1))
return model
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 2번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(4, input_shape=(window_size,1)))
model.add(layers.Dense(1))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=100, name=None):
# TODO: [지시사항 3번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 4번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, batch_size=8, epochs=epochs, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 MSE: {:.5f}".format(test_loss))
print()
return optimizer, hist
def plot_result(model, X_true, y_true, plot_data, name):
y_pred = model.predict(X_true)
# 표준화된 결과를 다시 원래 값으로 변환합니다.
y_true_orig = (y_true * plot_data["stdv"]) + plot_data["mean"]
y_pred_orig = (y_pred * plot_data["stdv"]) + plot_data["mean"]
# 테스트 데이터에서 사용한 날짜들만 가져옵니다.
test_month = plot_data["month"][-len(y_true):]
# 모델의 예측값을 실제값과 함께 그래프로 그립니다.
fig = plt.figure(figsize=(8, 6))
ax = plt.gca()
ax.plot(y_true_orig, color="b", label="True")
ax.plot(y_pred_orig, color="r", label="Prediction")
ax.set_xticks(list(range(len(test_month))))
ax.set_xticklabels(test_month, rotation=45)
ax.set_title("{} Result".format(name))
ax.legend(loc="upper left")
plt.savefig("airline_{}.png".format(name.lower()))
def main():
tf.random.set_seed(2022)
window_size = 4
X_train, X_test, y_train, y_test, plot_data = load_data(window_size)
gru_model = build_gru_model(window_size)
run_model(gru_model, X_train, X_test, y_train, y_test, name="GRU")
plot_result(gru_model, X_test, y_test, plot_data, name="GRU")
rnn_model = build_rnn_model(window_size)
run_model(rnn_model, X_train, X_test, y_train, y_test, name="RNN")
plot_result(rnn_model, X_test, y_test, plot_data, name="RNN")
elice_utils.send_image("airline_{}.png".format("gru"))
elice_utils.send_image("airline_{}.png".format("rnn"))
if __name__ == "__main__":
main()
기존 RNN과 GRU 의 결과이다. GRU가 오차(MSE도 적을 것) 가 훨씬 적어진 것을 볼 수 있다.(True와 가깝게 더 예측을 잘함)
실습 4 분류 작업 ( amazon의 식품 리뷰 데이터셋 : 별점 1점~5점 5 classes ) 을 Vanilla, LSTM, GRU로 구현해보기 예제
Tokenizer : 단어 string을 숫자로 변환. 임베딩이랑은 다른 개념! indexing 같은 느낌. sky = 56 love = 57
max_features : 전체 데이터셋에 겹치지 않는 단어의 개수
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
import pandas as pd
def load_data(max_len):
data = pd.read_csv("./review_score.csv")
# 리뷰 문장을 입력 데이터로, 해당 리뷰의 평점을 라벨 데이터로 설정합니다.
X = data['Review']
y = data['Score']
y = y - 1 # 값을 1~5에서 0~4로 변경
# 문장 내 각 단어를 숫자로 변환하는 Tokenizer를 적용합니다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(X)
X = tokenizer.texts_to_sequences(X) #각 단어를 숫자로 tokenizer 활용
# 전체 단어 중에서 가장 큰 숫자로 mapping된 단어의 숫자를 가져옵니다.
# 즉, max_features는 전체 데이터셋에 등장하는 겹치지 않는 단어의 개수 + 1과 동일합니다.
max_features = max([max(_in) for _in in X]) + 1
# 불러온 데이터셋을 학습 데이터 80%, 테스트 데이터 20%로 분리합니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 모든 문장들을 가장 긴 문장의 단어 개수가 되게 padding을 추가합니다.
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
return X_train, X_test, y_train, y_test, max_features
def build_rnn_model(max_features, embedding_size):
model = Sequential()
# TODO: [지시사항 1번] Simple RNN 기반의 모델을 완성하세요.
model.add(layers.Embedding(max_features, embedding_size))
model.add(layers.SimpleRNN(20))
model.add(layers.Dense(5, activation='softmax')) # 5개의 클래스 리뷰 5점까지
return model
def build_lstm_model(max_features, embedding_size):
model = Sequential()
# TODO: [지시사항 2번] LSTM 기반의 모델을 완성하세요.
model.add(layers.Embedding(max_features, embedding_size))
model.add(layers.LSTM(20))
model.add(layers.Dense(5, activation='softmax'))
return model
def build_gru_model(max_features, embedding_size):
model = Sequential()
# TODO: [지시사항 3번] GRU 기반의 모델을 완성하세요.
model.add(layers.Embedding(max_features, embedding_size))
model.add(layers.GRU(20))
model.add(layers.Dense(5, activation='softmax'))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=10):
# TODO: [지시사항 4번] 모델 학습을 위한 optimizer, loss 함수, 평가 지표를 설정하세요.
optimizer = Adam(learning_rate= 0.001)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# TODO: [지시사항 5번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=256, shuffle=True, verbose=2)
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
return test_loss, test_acc, optimizer, hist
def main():
tf.random.set_seed(2022)
max_len = 150
embedding_size = 128
X_train, X_test, y_train, y_test, max_features = load_data(max_len)
rnn_model = build_rnn_model(max_features, embedding_size)
lstm_model = build_lstm_model(max_features, embedding_size)
gru_model = build_gru_model(max_features, embedding_size)
rnn_test_loss, rnn_test_acc, _, _ = run_model(rnn_model, X_train, X_test, y_train, y_test)
lstm_test_loss, lstm_test_acc, _, _ = run_model(lstm_model, X_train, X_test, y_train, y_test)
gru_test_loss, gru_test_acc, _, _ = run_model(gru_model, X_train, X_test, y_train, y_test)
print()
print("=" * 20, "모델 별 Test Loss와 정확도", "=" * 20)
print("[RNN ] 테스트 Loss: {:.5f}, 테스트 Accuracy: {:.3f}%".format(rnn_test_loss, rnn_test_acc * 100))
print("[LSTM] 테스트 Loss: {:.5f}, 테스트 Accuracy: {:.3f}%".format(lstm_test_loss, lstm_test_acc * 100))
print("[GRU ] 테스트 Loss: {:.5f}, 테스트 Accuracy: {:.3f}%".format(gru_test_loss, gru_test_acc * 100))
if __name__ == "__main__":
main()
실습 5 회귀 분석 ( 나스닥(NASDAQ) 상장 기업 중 Apple의 주가 1980.12.12~2020.04.01 데이터셋 )
지금까지 진행했던 시계열 데이터셋의 feature는 모두 1개였다.(승객 수 예측)
그러나 이 Apple의 주가 데이터셋은 각 시점에 시작가, 일최고가, 일최저가, 종가의 4개의 feature를 예측해야 하는 임무가 있다!
그리고 모델에 한번에 넣어줄 시점의 갯수 = window size 는 30개로 설정하였다
)왜냐하면 주말에는 주식 시장이 열리지 않으므로 대략 한달 이상의 기간을 보고 입력 데이터 내 마지막 날짜의 다음날의 종가를 예측하도록 모델을 학습시킨다.
- window_size 개의 데이터를 불러와 입력 데이터(X)로 설정하고
- window_size보다 한 시점 뒤의 데이터를 예측할 대상(y)으로 설정하여 데이터셋을 구성한다.
from elice_utils import EliceUtils
elice_utils = EliceUtils()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import StandardScaler
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def load_data(window_size):
raw_data_df = pd.read_csv("./AAPL.csv", index_col="Date")
# 데이터 전체를 표준화합니다.
scaler = StandardScaler()
raw_data = scaler.fit_transform(raw_data_df)
plot_data = {"mean": scaler.mean_[3], "var": scaler.var_[3], "date": raw_data_df.index}
# 입력 데이터(X)는 시작가, 일 최고가, 일 최저가, 종가 데이터를 사용하고
# 라벨 데이터(y)는 4번째 컬럼에 해당하는 종가 데이터만 사용합니다.
raw_X = raw_data[:, :4]
raw_y = raw_data[:, 3]
# window_size 개의 데이터를 불러와 입력 데이터(X)로 설정하고
# window_size보다 한 시점 뒤의 데이터를 예측할 대상(y)으로 설정하여
# 데이터셋을 구성합니다.
X, y = [], []
for i in range(len(raw_X) - window_size):
cur_prices = raw_X[i:i + window_size, :]
target = raw_y[i + window_size]
X.append(list(cur_prices))
y.append(target)
# X와 y를 numpy array로 변환합니다.
X = np.array(X)
y = np.array(y)
# 학습 데이터는 전체 데이터의 80%, 테스트 데이터는 20%로 설정합니다.
total_len = len(X)
train_len = int(total_len * 0.8)
X_train, y_train = X[:train_len], y[:train_len]
X_test, y_test = X[train_len:], y[train_len:]
return X_train, X_test, y_train, y_test, plot_data
def build_rnn_model(window_size, num_features):
model = Sequential()
# TODO: [지시사항 1번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(256, input_shape=(window_size, num_features)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1))
return model
def build_lstm_model(window_size, num_features):
model = Sequential()
# TODO: [지시사항 2번] LSTM 기반 모델을 구성하세요.
model.add(layers.LSTM(256, input_shape=(window_size, num_features)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1))
return model
def build_gru_model(window_size, num_features):
model = Sequential()
# TODO: [지시사항 3번] GRU 기반 모델을 구성하세요.
model.add(layers.GRU(256, input_shape=(window_size, num_features)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=10, name=None):
# TODO: [지시사항 4번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 5번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, batch_size=128, epochs=epochs, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print("[{}] 테스트 loss: {:.5f}".format(name, test_loss))
print()
return optimizer, hist
def plot_result(model, X_true, y_true, plot_data, name):
y_pred = model.predict(X_true)
# 표준화된 결과를 다시 원래 값으로 변환합니다.
y_true_orig = (y_true * np.sqrt(plot_data["var"])) + plot_data["mean"]
y_pred_orig = (y_pred * np.sqrt(plot_data["var"])) + plot_data["mean"]
# 테스트 데이터에서 사용한 날짜들만 가져옵니다.
test_date = plot_data["date"][-len(y_true):]
# 모델의 예측값을 실제값과 함께 그래프로 그립니다.
fig = plt.figure(figsize=(12, 8))
ax = plt.gca()
ax.plot(y_true_orig, color="b", label="True")
ax.plot(y_pred_orig, color="r", label="Prediction")
ax.set_xticks(list(range(len(test_date))))
ax.set_xticklabels(test_date, rotation=45)
ax.xaxis.set_major_locator(ticker.MultipleLocator(100))
ax.yaxis.set_major_locator(ticker.MultipleLocator(100))
ax.set_title("{} Result".format(name))
ax.legend(loc="upper left")
plt.tight_layout()
plt.savefig("apple_stock_{}".format(name.lower()))
elice_utils.send_image("apple_stock_{}.png".format(name.lower()))
def main():
tf.random.set_seed(2022)
window_size = 30
X_train, X_test, y_train, y_test, plot_data = load_data(window_size)
num_features = X_train[0].shape[1]
rnn_model = build_rnn_model(window_size, num_features)
lstm_model = build_lstm_model(window_size, num_features)
gru_model = build_gru_model(window_size, num_features)
run_model(rnn_model, X_train, X_test, y_train, y_test, name="RNN")
run_model(lstm_model, X_train, X_test, y_train, y_test, name="LSTM")
run_model(gru_model, X_train, X_test, y_train, y_test, name="GRU")
plot_result(rnn_model, X_test, y_test, plot_data, name="RNN")
plot_result(lstm_model, X_test, y_test, plot_data, name="LSTM")
plot_result(gru_model, X_test, y_test, plot_data, name="GRU")
if __name__ == "__main__":
main()
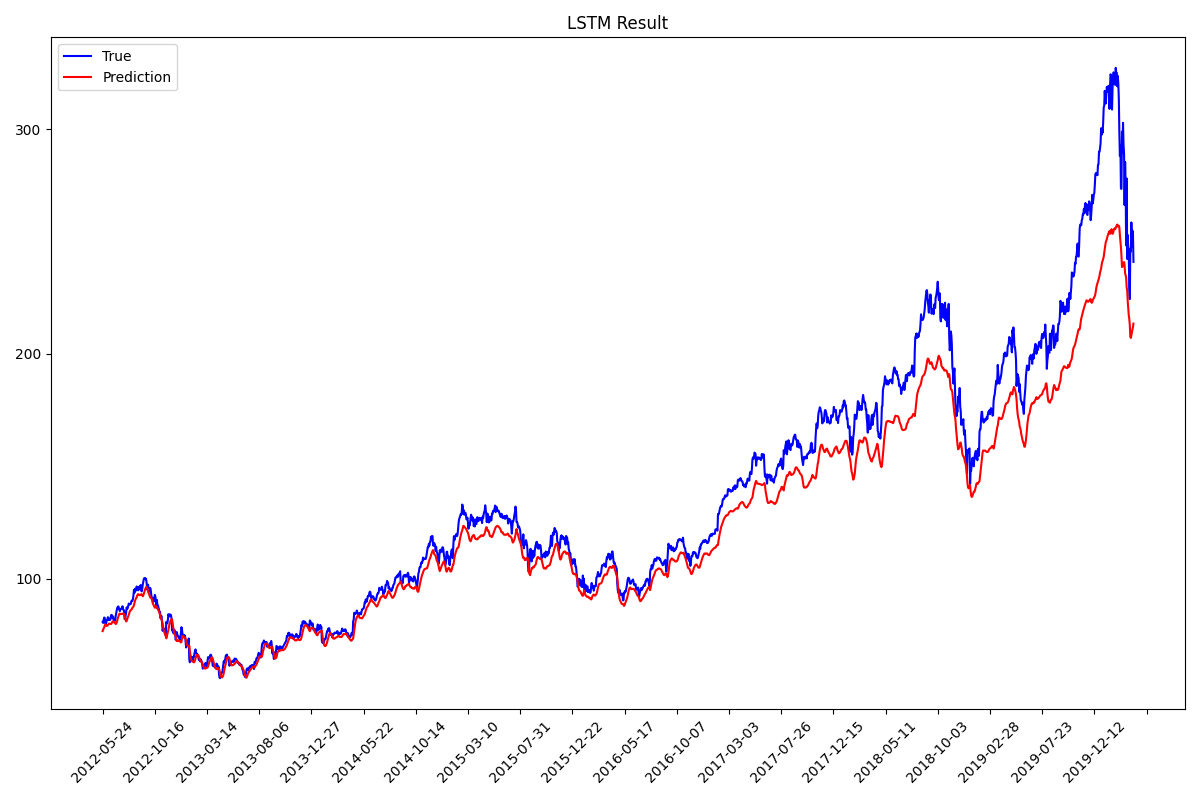

GRU가 가장 예측 정확도가 높다. (실제 파란색 과 pred 빨간색이 가장 흡사함)
'작업 > RNN' 카테고리의 다른 글
| 22.03.15 RNN(Recurrent Neural Network) (0) | 2022.03.19 |
|---|---|
| 22.03.15 CSE 콜로퀴엄 수업 대규모 자연어 처리 모델 분산학습 최적화 최신 동향(서지원 교수님) (0) | 2022.03.16 |