2022. 3. 19. 16:53ㆍ작업/RNN

순차 데이터 :
- 순서가 있는 데이터. 이 단어 다음에 뭐가 올지 예상(ex 날씨 예보, DNA 염기서열, 샘플링된 소리신호)
- 데이터 내 각 개체 간의 순서가 중요하다.
- 딥러닝에서 많이 쓰이는 순차 데이터로는 시계열데이터가 있다.
1. 시계열 데이터(Time Series Data) - 시간순으로 나열된 데이터
- 일정한 시간 간격을 가지고 얻어낸 데이터
- ex 날씨 데이터 주가 데이터 등
2. 자연어 데이터(Natural language)
- 사람들이 쓰는 말, 단어가 등장하는 순서(주어 목적어 동사) 가 중요
딥러닝을 활용해서 이런 순차 데이터들을 어떤 일들이 가능할까?
1. 경향성 파악 - 주로 시계열 데이터에 적용(ex 주가예측, 기온예측)
2. 음악 장르 분석 - 오디오 파일도 시계열 데이터(x축이 time)
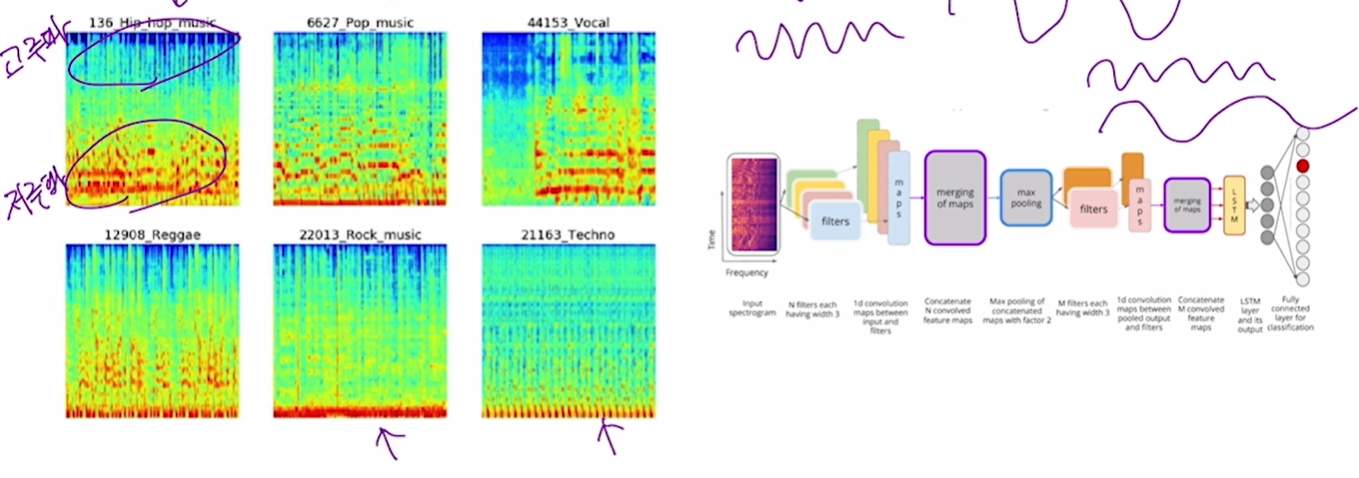
3. 강수량 예측 (시계열 + 기상 사진 이미지 처리기술과 결합 MetNet)
4. 음성 인식(시리, 빅스비)
5. 번역기
- 두 언어 간 문장 번역을 수행 , 딥러닝 발전 이후 번역의 자연스러움이 향상
- 이미지 처리와 결합하면 사진 찍으면 실시간 번역도 가능
6. 챗봇 - 사용자의 질문에 사람처럼 질문을 분석 후 적절한 응답을 생성
Recurrent Neural Network
순차데이터에서는 FC를 사용하는 게 적절하지 않다.
FC는 입력노드 개수와 출력노드 개수를 먼저 정해줘야 한다. 그러나 순차데이터는 하나의 데이터를 이루는 개체 수가 다를 수 있다. 또한 FC layer는 순서를 고려할 수 없다.(나는 배가 고프다, 배가 나는 고프다)

따라서 순차 데이터를 처리하기 위해 RNN이 등장했다. Recurrent = 순환
RNN은 Hidden State(=internal state)를 가지고 있다. 순환하는 internal state가 있다.

RNN이 요구하는 입력 데이터의 구조

xt = 순차 데이터의 한 개체? 한 단위? t가 커질 수록 뒤쪽 순서에 나오는 개체
시계열 데이터의 벡터 변환(x축이 time인 모든 데이터들, 순서가 있다)
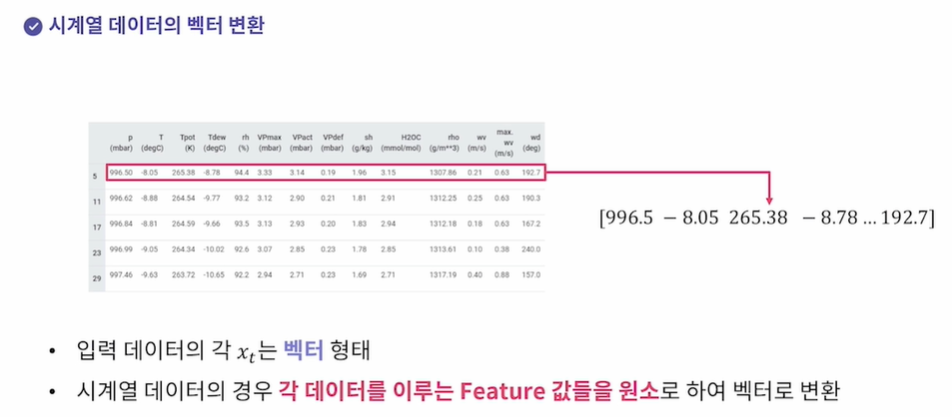
이미지 데이터는 픽셀 값을 행렬로 표현했다면, 시계열 데이터는 xt의 feature들(여기서 column)를 element로 해서 벡터 형태로 표현한다. x1 = [1,3,5,2,1] x2 = [3,2,1,1,1,]
자연어 데이터의 벡터 변환(time으로 꼭 된 건 아니지만, 순서가 있다)
- 임베딩 : 각 단어들을 숫자로 이루어진 벡터로 변환
1. one-hot encoding : 1은 한번만 나오고, 1의 위치에 따라 벡터를 표현.
2. Word2Vec : 단어를 벡터로 바꿔주는 요새 사용하는 기술

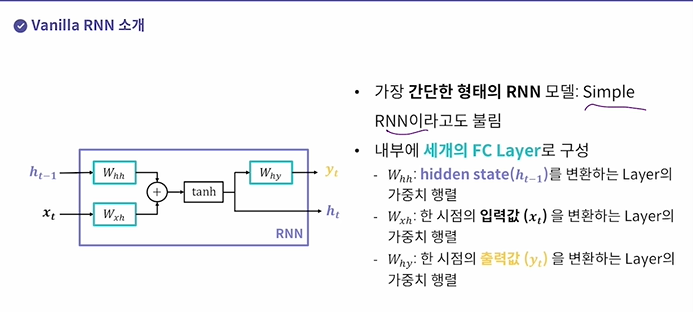
Vanilla RNN
tensorflow에 simple RNN이라는 이름으로 구현되어 있다.
세 개의 FC Layer로 구성
1. hidden state
2. 입력값을 변환하는 layer
3. 출력값을 변환하는 layer

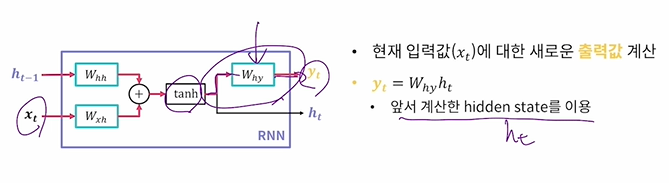
이전에 썼던 hidden state 값을 곱하고 더해서 새로운 hidden state를 만든다.
활성화함수로는 tanh를 사용한다(선형 -> 비선형)
그 다음 y를 구한다.
시간순으로 Vanilla RNN 을 연산한다.

RNN의 Recurrent 인 이유 : 이전 시점에 생성된 hidden state를 다음 시점에도 사용하기 때문이다.
Hidden state의 의미:
- 특정 시점 t까지 들어온 입력값들의 상관관계나 경향성을 저장한다.
- 모델이 내부적으로 계속 가지는 값이므로 일종의 메모리라고 생각할 수 있다.
Parameter Sharing:
- Hidden state와 출력값 계산을 위한 FC Layer를 모든 시점의 입력값이 재사용
- FC Layer 세 개가 모델 파라미터의 전부이다. (x1,x2,x3,x4....가 100개가 되어도 모델 파라미터는 저 세개이다)
Vanilla RNN의 종류
x1,x2,x3.. 에 따라 y1,y2,y3가 나오는데 y가 꼭 하나만 나오는 게 아니라 원하는 만큼 사용 가능
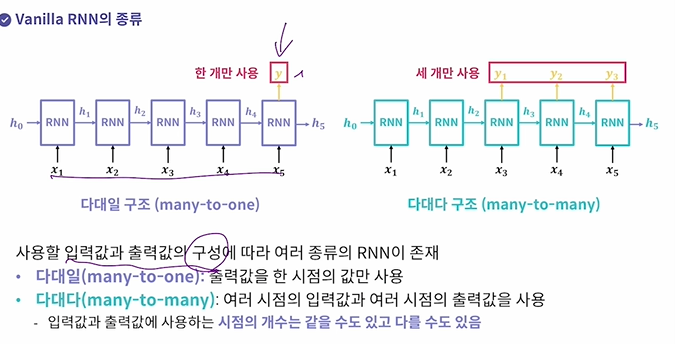
다대일: 출력값을 한 시점 값만
다대다: 여러 시점의 입력 -> 여러 시점의 출력값
인코더 디코더

입력만 받아서 만든 hidden state를 따로 떼와서 걔를 가지고 출력값만 만드는 RNN 모델을 짠다.
Vanilla RNN의 문제점
- RNN은 출력값이 시간 순서에 따라 생성
- 각 시점의 출력-실제를 뺴서 loss(손실)을 구함.
- 그 다음 시간에 따라 back propagation 을 진행

이런 과정으로 학습을 하는데
- 만약 입력값의 길이가 매우 길어지면

기울기 소실 문제가 발생(Vanishing Gradient)
- 엄청 긴 문장(장기 의존성 = Long term Dependency)를 다루기가 어렵다.
(엄청 긴 문장의 맨 처음단어와 맨 마지막단어의 의존)
실습1 Vanilla RNN 모델 만들기 - tensorflow

tensorflow에서 SimpleRNN에서 CNN의 Conv2D처럼 사용한다.
자연어 데이터를 임베딩 하는 상황을 가정하여 모델을 구성해보자.
tensorflow에 있는 함수 중 임베딩을 해주는 layer인 Embedding을 import해서 전체 단어 개수와 각 단어를 몇 개의 원소를 가지는 벡터로 만들지를 설정해줘보기.

import tensorflow as tf
from tensorflow.keras import layers, Sequential
# TODO: [지시사항 1번] 첫번째 모델을 완성하세요.
def build_model1():
model = Sequential()
model.add(layers.Embedding(10, 5)) #input_dim = 전체단어개수, 벡터길이 = output_dim
model.add(layers.SimpleRNN(3)) # hidden state의 벡터 길이 = 3으로 설정 필수 파라미터.
return model
# TODO: [지시사항 2번] 두번째 모델을 완성하세요.
def build_model2():
model = Sequential()
model.add(layers.Embedding(256,100))
model.add(layers.SimpleRNN(20))
model.add(layers.Dense(10, activation='softmax')) # classfier, 10 classes로 분류
return model
def main():
model1 = build_model1()
print("=" * 20, "첫번째 모델", "=" * 20)
model1.summary()
print()
model2 = build_model2()
print("=" * 20, "두번째 모델", "=" * 20)
model2.summary()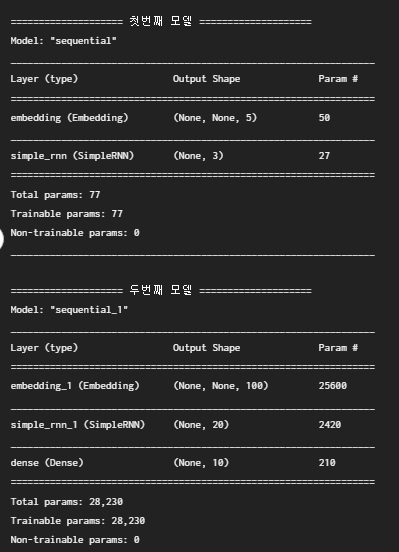
실습2 Vanilla RNN으로 IMDb(영화정보) 데이터 학습
리뷰가 긍정적인지 부정적인지 클래스 2개로 해서 분류하기(감정 분석 Sentimental Analysis)


import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
# pad_sequences : 각 문장에 존재하는 단어 개수를 동일하게 해주기 위해 가장 최대 단어를 가진 단어갯수 maxlen, 다른 단어들도 그만큼 길이가 되도록 padding을 해주는 것이다.
def load_data(num_words, max_len):
# imdb 데이터셋을 불러옵니다. 데이터셋에서 단어는 num_words 개를 가져옵니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
# 단어 개수가 다른 문장들을 Padding을 추가하여
# 단어가 가장 많은 문장의 단어 개수로 통일합니다.
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
return X_train, X_test, y_train, y_test
def build_rnn_model(num_words, embedding_len):
model = Sequential()
# TODO: [지시사항 1번] 지시사항에 따라 모델을 완성하세요.
model.add(layers.Embedding(num_words, embedding_len)) # 전체 단어갯수, 임베딩할 벡터의 길이 [1,2,3,4,5]?
model.add(layers.SimpleRNN(16))
model.add(layers.Dense(1, activation='sigmoid')) # Dense layer 노드갯수 = 1, 긍정 or 부정
return model # Dense layer의 노드 갯수를 1개. class는 두개인데 왜 1개를 하냐? 긍정일 때 하나를 가져온다?
def main(model=None, epochs=5):
# IMDb 데이터셋에서 가져올 단어의 개수
num_words = 6000
# 각 문장이 가질 수 있는 최대 단어 개수
max_len = 130
# 임베딩 된 벡터의 길이
embedding_len = 100
# IMDb 데이터셋을 불러옵니다.
X_train, X_test, y_train, y_test = load_data(num_words, max_len)
if model is None:
model = build_rnn_model(num_words, embedding_len)
# TODO: [지시사항 2번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# TODO: [지시사항 3번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=100, validation_split=0.2, shuffle=True, verbose=2)
# 모델을 테스트 데이터셋으로 테스트합니다.
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 Loss: {:.5f}, 테스트 정확도: {:.3f}%".format(test_loss, test_acc * 100))
return optimizer, hist
if __name__=="__main__":
main()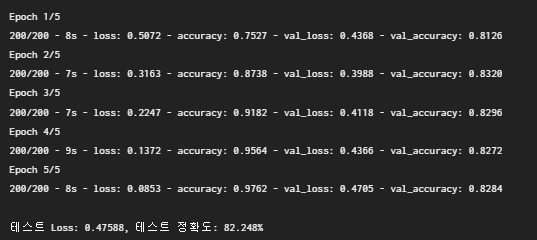
실습 3 Vanilla RNN을 통한 항공 승객 수 분석
항공 승객 수 데이터셋 : 시계열 데이터 사용. 1949년~1960년 데이터 월별로

window size : 순차 데이터를 나눠서 학습?하는 단위? 창문을 통해 window size만큼 보고 다음 것을 예상한다

예를 들어 windowsize= 4면 x1,x2,x3,x4를 한번에
즉 4니까 네 달치 월별 데이터들을 보고 다음 달의 승객수(5월)을 예측하는 것.

from elice_utils import EliceUtils
elice_utils = EliceUtils()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def load_data(window_size):
raw_data = pd.read_csv("./airline-passengers.csv")
raw_passengers = raw_data["Passengers"].to_numpy()
# 데이터의 평균과 표준편차 값으로 정규화(표준화) 합니다.
mean_passenger = raw_passengers.mean()
stdv_passenger = raw_passengers.std(ddof=0)
raw_passengers = (raw_passengers - mean_passenger) / stdv_passenger
data_stat = {"month": raw_data["Month"], "mean": mean_passenger, "stdv": stdv_passenger}
# window_size 개의 데이터를 불러와 입력 데이터(X)로 설정하고
# window_size보다 한 시점 뒤의 데이터를 예측할 대상(y)으로 설정하여
# 데이터셋을 구성합니다.
X, y = [], []
for i in range(len(raw_passengers) - window_size):
cur_passenger = raw_passengers[i:i + window_size] #4월씩 끊어서 다음 월을 예측
target = raw_passengers[i + window_size]
X.append(list(cur_passenger))
y.append(target)
# X와 y를 numpy array로 변환합니다.
X = np.array(X)
y = np.array(y)
# 각 입력 데이터는 sequence 길이가 window_size이고, featuer 개수는 1개가 되도록
# 마지막에 새로운 차원을 추가합니다.
# 즉, (전체 데이터 개수, window_size) -> (전체 데이터 개수, window_size, 1)이 되도록 변환합니다.
X = X[:, :, np.newaxis]
# 학습 데이터는 전체 데이터의 80%, 테스트 데이터는 20%로 설정합니다.
total_len = len(X)
train_len = int(total_len * 0.8)
X_train, y_train = X[:train_len], y[:train_len]
X_test, y_test = X[train_len:], y[train_len:]
return X_train, X_test, y_train, y_test, data_stat
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(4, input_shape=(window_size,1))) # input_shape = (window_size, feauture갯수=승객수만)
# SimpleRNN(hidden state크기, input_shape)
# input_shape을 순차데이터에서는 알려줘야 하고, 자연어는 임베딩을 하면 알아서 input_shape을 찾으므로 알려주지 않아도 됨.
model.add(layers.Dense(1))
return model
def plot_result(X_true, y_true, y_pred, data_stat):
# 표준화된 결과를 다시 원래 값으로 변환합니다.
y_true_orig = (y_true * data_stat["stdv"]) + data_stat["mean"]
y_pred_orig = (y_pred * data_stat["stdv"]) + data_stat["mean"]
# 테스트 데이터에서 사용한 날짜들만 가져옵니다.
test_month = data_stat["month"][-len(y_true):]
# 모델의 예측값을 실제값과 함께 그래프로 그립니다.
fig = plt.figure(figsize=(8, 6))
ax = plt.gca()
ax.plot(y_true_orig, color="b", label="True")
ax.plot(y_pred_orig, color="r", label="Prediction")
ax.set_xticks(list(range(len(test_month))))
ax.set_xticklabels(test_month, rotation=45)
ax.set_title("RNN Result")
ax.legend(loc="upper left")
plt.savefig("airline_rnn.png")
elice_utils.send_image("airline_rnn.png")
def main(model=None, epochs=10):
tf.random.set_seed(2022)
window_size = 4
X_train, X_test, y_train, y_test, data_stat = load_data(window_size)
if model is None:
model = build_rnn_model(window_size)
# TODO: [지시사항 2번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# mse = 회귀분석(값 자체를 예측) , cross_entropy = 분류
# TODO: [지시사항 3번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, batch_size=8, epochs=epochs, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 MSE: {:.5f}".format(test_loss))
print()
# 모델의 예측값과 실제값을 그래프로 그립니다.
y_pred = model.predict(X_test)
plot_result(X_test, y_test, y_pred, data_stat)
return optimizer, hist
if __name__ == "__main__":
main()- 각 입력 데이터는 sequence 길이가 window_size이고, featuer 개수는 1개(승객수만 본다)
- SimpleRNN(hidden state크기, input_shape)
- input_shape을 순차데이터에서는 알려줘야 하고, 자연어는 임베딩을 하면 알아서 input_shape을 찾으므로 알려주지 않아도 됨.
- mse = 회귀분석(값 자체를 예측) , cross_entropy = 분류


실습5 심층 Vanilla RNN 모델
여태까지는 SimpleRNN하나만 사용했는데 Conv2D처럼 여러 개 사용할 수 있다.
이렇게 여러 층으로 이루어진 모델을 심층RNN(Deep RNN)이라고 한다.
여기서 사용할 데이터는 시계열 데이터 중 하나인 sin함수를 조합해 만든 간단한 데이터이다.
window size는 50으로 하였다.

import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import numpy as np
def load_data(num_data, window_size):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, num_data, 1)
time = np.linspace(0, 1, window_size)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10))
series += 0.1 * np.sin((time - offsets2) * (freq2 * 10 + 10))
series += 0.1 * (np.random.rand(num_data, window_size) - 0.5)
num_train = int(num_data * 0.8)
X_train, y_train = series[:num_train, :window_size], series[:num_train, -1]
X_test, y_test = series[num_train:, :window_size], series[num_train:, -1]
X_train = X_train[:, :, np.newaxis]
X_test = X_test[:, :, np.newaxis]
return X_train, X_test, y_train, y_test
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(20, input_shape=(window_size, 1)))
model.add(layers.Dense(1))
return model
def build_deep_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 2번] 여러개의 SimpleRNN을 가지는 모델을 구성하세요.
model.add(layers.SimpleRNN(20, return_sequences=True, input_shape=(window_size,1)))
# return_sequences : 다대다True인지 다대일False인지 즉 output이 여러시점인지 우리는 지금 Deep RNN이므로 output을 내고 또 걔를 넣고 해야되니까 다대다 즉 True
model.add(layers.SimpleRNN(20))
model.add(layers.Dense(1))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=20, name=None):
# TODO: [지시사항 3번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 4번] 모델 학습을 위한 hyperparameter를 설정하세요.
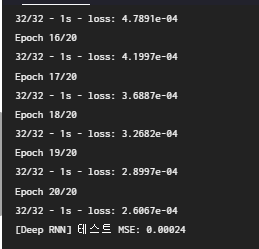
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=256, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print("[{}] 테스트 MSE: {:.5f}".format(name, test_loss))
print()
return optimizer, hist
def main():
tf.random.set_seed(2022)
np.random.seed(2022)
window_size = 50
X_train, X_test, y_train, y_test = load_data(10000, window_size)
rnn_model = build_rnn_model(window_size)
run_model(rnn_model, X_train, X_test, y_train, y_test, name="RNN")
deep_rnn_model = build_deep_rnn_model(window_size)
run_model(deep_rnn_model, X_train, X_test, y_train, y_test, name="Deep RNN")
if __name__ == "__main__":
main()model.add(layers.SimpleRNN(20, return_sequences=True, input_shape=(window_size,1)))
# return_sequences : 다대다True인지 다대일False인지 즉 output이 여러시점인지 우리는 지금 Deep RNN이므로 output을 내고 또 걔를 넣고 해야되니까 다대다 즉 True
실습 6 Encoder Decoder 구조
SimpleRNN을 사용해 Encoder-Decoder 구조를 구현해보자.
Encoder-Decoder 구조의 가장 큰 특징이라면 Encoder에서 나오는 출력값은 사용하지 않고, Encoder의 hidden state만 가져와서 이를 Decoder의 초기 hidden state로 활용한다는 점입니다.

return_sequences = False : 마지막 시점의 출력값만 사용, True : 다섯개가 나오면 다 사용
return_state = False : 출력값이 output만 나온다. True : output, hidden state까지 나오게 한다.
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras import layers, Sequential, Input
class EncoderDecoder(Model):
def __init__(self, hidden_dim, encoder_input_shape, decoder_input_shape, num_classes):
super(EncoderDecoder, self).__init__()
# TODO: [지시사항 1번] SimpleRNN으로 이루어진 Encoder를 정의하세요.
self.encoder = layers.SimpleRNN(hidden_dim, return_state=True, input_shape=encoder_input_shape)
# TODO: [지시사항 2번] SimpleRNN으로 이루어진 Decoder를 정의하세요.
self.decoder = layers.SimpleRNN(hidden_dim, return_sequences=True, input_shape=decoder_input_shape)
self.dense = layers.Dense(num_classes, activation="softmax")
def call(self, encoder_inputs, decoder_inputs):
# TODO: [지시사항 3번] Encoder에 입력값을 넣어 Decoder의 초기 state로 사용할 state를 얻어내세요.
encoder_output, encoder_state = self.encoder(encoder_inputs)
# TODO: [지시사항 4번] Decoder에 입력값을 넣고, 초기 state는 Encoder에서 얻어낸 state로 설정하세요.
# decoder_outputs = self.decoder(decoder_inputs, initial_state=encoder_state)
decoder_outputs = self.decoder(decoder_inputs, initial_state=[encoder_state]) #여러개 쓸거면 리스트로
outputs = self.dense(decoder_outputs)
return outputs
def main():
# hidden state의 크기
hidden_dim = 20
# Encoder에 들어갈 각 데이터의 모양
encoder_input_shape = (10, 1)
# Decoder에 들어갈 각 데이터의 모양
decoder_input_shape = (30, 1)
# 분류한 클래스 개수
num_classes = 5
# Encoder-Decoder 모델을 만듭니다.
model = EncoderDecoder(hidden_dim, encoder_input_shape, decoder_input_shape, num_classes)
# 모델에 넣어줄 가상의 데이터를 생성합니다.
encoder_x, decoder_x = tf.random.uniform(shape=encoder_input_shape), tf.random.uniform(shape=decoder_input_shape)
encoder_x, decoder_x = tf.expand_dims(encoder_x, axis=0), tf.expand_dims(decoder_x, axis=0)
y = model(encoder_x, decoder_x)
# 모델의 정보를 출력합니다.
model.summary()
if __name__ == "__main__":
main()
'작업 > RNN' 카테고리의 다른 글
| 22.03.19 LSTM 과 GRU (0) | 2022.03.19 |
|---|---|
| 22.03.15 CSE 콜로퀴엄 수업 대규모 자연어 처리 모델 분산학습 최적화 최신 동향(서지원 교수님) (0) | 2022.03.16 |