2022. 6. 16. 17:40ㆍ카테고리 없음
저번주 복습
confidence score : threshold보다 낮으면 버리고 높으면 bbox를 가져가는
Autoencoder : 자기 자신을 input과 target으로 삼아서 학습.
또한 upsampling도 배웠다.
- bilinear interpolation : 학습 파라미터 없이 주변값을 참고하여 빈값을 채움.
- transposed convolution : conv filter를 뒤집은 형태의 학습 파라미터를 가짐.
segmentation : 각 픽셀마다 classification을 해서 각 픽셀이 어떤 class인지 판별하여 class의 윤곽선을 얻는 문제.

8주차 목차
- CNN 이외에도 여러 task를 수행하는 인공신경망에 대해 배워볼 것이다.

왜 이미 학습된 pretrained 모델을 잘 활용해야 할까?

Finetuning : pretrained 된 모델 파라미터를 초기값으로 해서 풀고자 하는 문제에 맞게 약간의 추가 학습을 하는 것
- 언제 사용? 현재 풀려는 문제가 기존의 학습된 모델이 다루던 문제와 연관이 있을 때(backbone 모델)
classification , object detection , segmentation .. 은 다 비슷한다.
- 기존 학습된 파라미터를 너무 많이 바꾸면 잘 학습했던 특성들을 잃어버리므로 많이 변하지 않게
기존의 lr의 약 1/10정도로 학습을 시킨다.
- 언제 사용? 예시)같은 classification이지만 output이 달라질 때(class 종류.. 개수 등이 달라짐.. 마지막 부분에서 변화가 필요)
- 예시) 같은 classification이지만 데이터 분포가 기존과 다른 경우(시뮬레이션에서 모은 데이터와 실제 세상에서 모은 데이터 - 자율주행 등)

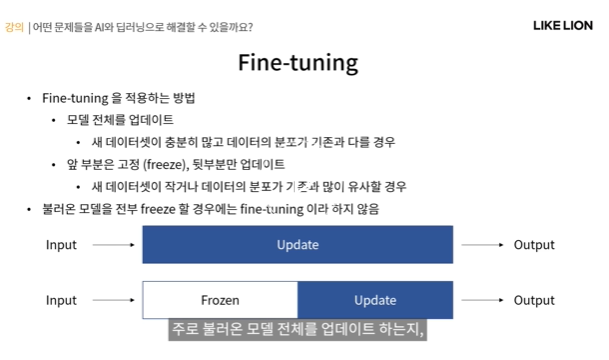
Fine tuning의 종류
- 모델 전체를 업데이트 - 새 데이터셋이 충분히 많고 데이터셋의 분포가 기존의 데이터셋과 다른 경우(low level feature도 tuning이 필요해서)
- 앞 부분은 고정, 뒷 부분만 업데이트(input쪽에 가까운 파라미터는 고정(freeze), 뒷부분만 업데이트) - 새 데이터셋이 적거나 데이터셋 분포가 기존과 비슷한 경우
- 모델을 전부 고정하는 경우: feature extractor라고 함.(fine tuning이라고 안함)
Ensemble Method : 여러개의 간단한 모델들을 결합해서 하나의 강력한 모델을 만드는 것.
- 같은 입력에 대해 같은 문제를 푸는 여러 모델들의 결과를 합해서 최종 예측을 얻어냄.
- finetuning말고도 pretrained 모델을 활용하는 또 다른 방법.

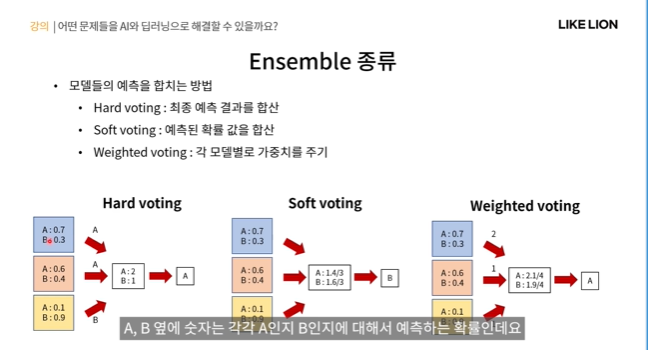
여러 모델의 예측을 합친다고 했는데 합친다는 게 뭐냐?
- hard voting : 모델 각각의 최종 예측 결과를 가지고 투표를 하는 것.
아래 그림에서 파랑,빨강,노랑 모델이 A,B를 구분하는 classifier라고 하자. 그럼 A라고 하는 게 우세하므로 A로 결정
- soft voting : predict값의 평균을 내서 그걸로 최종 결과를 결정 (0.7+0.6+0.1)/3. ..
A는 0.1, B는 0.9 이러면 굉장히 모델이 확신을 가지고 예측을 한 것임. 근데 A 0.4 B 0.6 이러면 둘 예측값의 차이가 크지 않다. 긴가민가하다. hard, soft 중 뭘 쓸 지는 문제에 따라 유연하게 선택할 줄 알아야 한다.
- weighted voting : 각 모델별로 가중치를 줌. 예를 들어 아래 그림에서 파랑모델에 가중치 2를 주면 0.7*2 + 0.6+0.1 / 4(=가중치의 합) 를 하는 거임. 단 가중치역시 하이퍼 파라미터임.
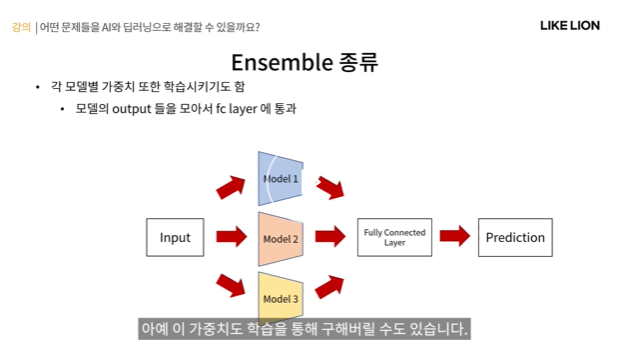
가중치까지 학습을 시킬 수도 있다.
- 각 모델의 output들을 모아서 FC layer에 통과시켜서 최종 예측을 얻겠다는 것. 이렇게 되면 모델의 가중치도 사람이 정해주는 하이퍼파라미터가 아닌 알아서 학습하는 그냥 파라미터로 학습을 함.
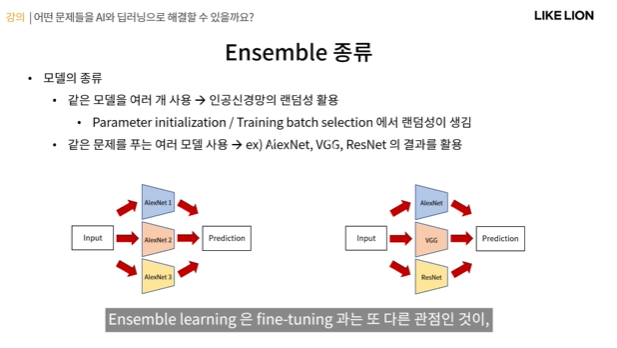
Ensemble을 사용할 때 1. 같은 모델을 여러 개 사용해도 되는데, 같은 모델이라는 건 같은 구조라는 뜻이지 학습된 파라미터까지 동일한 모델을 사용한다는 것은 아니다. -> 이 방법은 인공신경망의 랜덤성을 활용하는 것인데
- 인공 신경망은 같은 구조와 데이터로 학습을 시켜도 매번 약간 다른 값을 가진다.
- 이 랜덤성은 왜 생기냐면 맨 처음에 파라미터를 random하게 initailize하는 게 어떤 값이냐에 따라 달라지고,
- 또 학습 시에 batch sample들이 랜덤한 순서로 들어오기 때문에 업데이트 되는 gradient 값도 그때그때 랜덤하게 달라지게 된다. 그래서 최종 성능은 수치적으로 큰 차이가 나지는 않지만, 거기서 학습된 파라미터의 값들은 매번 조금씩 다르게 된다.
2. 같은 문제를 푸는 모델을 여러 개 사용. AlexNet, VGG, ResNet모두 classfication에 쓰는 모델
ensemble learning과 fine tuning과의 다른 점 : ensemble learning한다고 해서 엄청 성능이 오르진않고 약간 더 나아지는 정도인데 그에 반해 계산량이나 학습해야하는 모델은 많아지니 오히려 비효율적일 수도 있다.그럼에도 그 약간이라도 고르고 싶다.. 할때 쓴다.
딥러닝을 활용한 Supervised learning의 강함
- 인공신경망은 supervised 에서 뛰어난 성능을 보인다. input과 label이 주어졌을 때 충분히 있을 때 supervised에서는 딥러닝이 성능이 매우 좋다.
- 그에 반해 unsupervised의 경우는 supervised에 비해 직관적으로 학습이 불가능하므로 supervised에 비해 성능을 내기 어려움.
- 그런데 supervised learning은 할수만 있다면 괜찮은데 막대한 양의 label이 있는 데이터가 필요함.
- 어떻게 하면 label이 없는 데이터로 supervised 처럼 인공신경망을 잘 학습시킬 순 없을까?
-> self supervised learning

Self supervised learning(자기지도학습)
- label이 없는 데이터에 대해 스스로 supervision을 줘서 supervised learning처럼 학습하는 방법
- self supervised learning의 과정
1. 사용자가 직접 만든 task인 pretext task를 정의
2. label이 없는 데이터를 변형하여 pretext task를 학습할 수 있는 supervision을 생성.
(supervision : input과 label 짝을 만들어준다 <- 데이터를 약간의 processing만으로 변환하여 supervision을 만들 수 있도록 적절한 pretext task를 정의함으로서 해결한다.)
-> pretext task에 대해 supervised learning방식으로 학습.
self supervised의 좋은 예 : autoencoder
- autoencoder는 학습 시 input 이미지만 있으면 됐지 label을 사용하지 않았음. 원본이미지와 짝을 만듦 = supervision 생성
- self supervised의 예시 : Image colorization(원본 이미지를 흑백으로 하고 그걸 input으로 주면 다시 원본으로 복원하는 task), Image inpainting(image를 가려놓고 거길 적절하게 채우는 task)
- 간단한 processing만으로 supervision을 만들 수 있는 pretext processing을 정의!

Autoencoder 말고도 또 다른 self supervised learning
- Exemplar : seed 이미지를 다양한 방법으로 변형(색도 바꾸고 rotate도 하고..) 그 변형된 이미지를 보고 그게 seed 이미지에서 온 게 맞는지 판별해내는 모델
- Relative Patch Location : 저 아래처럼 고양이 얼굴 이미지가 하나 있으면 옆에 귀 사진이 1~8중 어느 위치에 해당할지
이것도 간단한 processing이 가능한 게 이미지를 9개로 잘라서 놔주면 된다.

Self supervised 모델은 어떻게 사용될까?
-> transfer learning으로 활용
self supervised learning을 통해 학습시킨 모델을 pretrained 네트워크로 사용하여 downstream? task 기반으로 활용하는 것.
downstream task : teafure를 활용해 구체적으로 풀고 싶은 어떤 task.
(예를 들어 classification 을 object detection,segmentation 등에 활용)
self supervised learning으로 학습된 모델이 좋은 feature extractor라는 건 어떻게 확인할 수 있을까?
-> self supervised로 사전학습된 모델을 label이 있는 데이터셋으로 supervised 학습을 해서 task에 대해 성능이 잘 나오면 encoder느낌으로 self supervised 모델이 feature를 잘 뽑아내는구나~ 라고 알 수 있음.
- ImageNet같은 대량의 labeled 데이터셋이 없을 때 self-supervised learning으로 학습시키는 것이 의미가 있다.
- 예를 들어 의료영상, CT 영상은 self-supervised learning을 적용해서

GradCam - CNN 모델의 예측을 설명하는 방법.(설명력)
- 인공신경망의 예측을 어떻게 설명할까? 인공신경망은 흔히 블랙박스라고 부름.. 답은 내는데 왜 그런 답을 냈는지를
모를 수 있다.
- 설령 파라미터(가중치,bias) 정도는 안다고 해도 왜 가중치가 0.6이냐? 0.4냐? 왜 그렇게 정해졌는가는 알기가 어려움. 저 filter에 대응되는 feature는 무엇이고 어떤 의미인가? 알기 어려움

그럼 인공신경망의 설명력을 왜 갖춰야 할까?
- 1. 인공신경망이 학습한 feature가 무엇인지 파악하고 싶다 -> 그래야 어떤 feature가 중요한 지 알아내고 모델을 더 발전시킬 수 있다.
- 2. 안전성에서 문제 - 자율주행(모델이 잘못된 결과를 낸다면? 옳은 판단이었는지 분석할 수 없다. 보완이 불가능)
- 3. 인공신경망이 사람을 가르칠 수도 있다? 묘수를 알려줌. 왜 그렇게 판단했는지?! ex 알파고
그래서 인공신경망을 설명하는 것은 좋다.
-> explainable AI (XAI)

GradCAM ( Gradient Weighted Class Activation Mapping)
- gradient를 이용해 인공신경망을 시각적으로 설명하는 기법, 주로 CNN에서 사용
예를 들어 classification을 예로 들자면, 마지막 layer의 class node를 기준으로 해서 시각화하고싶은 feature map상의 어떤 공간적인 위치가 해당 class node에 영향을 많이 줬는지.. 빨간색일 수록 영향을 많이 준 feature
(node에 영향을 많이 준 feature들이 activate 된 위치를 빨갛게 표시 - 그림에서는 고양이를 classifcation하는 노드)

GradCAM의 원리
- A : visualize 할 layer. feature map을 만드는 layer는 CNN안에 여러개가 있으므로
그 중 어떤 layer를 시각화할지
- Ak : 그 layer에서 k번쨰 feature map
- yc : target으로 하는 class node c 를 의미.
- akc : Ak의 각 픽셀의 yc에 대한 gradient 값의 평균 -> class c에 대해 feature map Ak가 얼마나 연관이 있냐 -> 많이 activate 됐을 수록 Grad CAM 값이 커진다.
-> Grad CAM은 layer A의 각 픽셀에서 그 위치의 feature map들의 activation 값들을 Akc로 가중치를 줘서 더한 값.
개와 연관성이 크면 Grad CAM이 크다. ( 개 얼굴 부분 )

Grad CAM 응용
- class에 따라 feature 가 어떻게 activate 되는지
왼쪽 위쪽에 output에 가까운 layer, 오른쪽 아래가 input에 가까운 layer의 GradCAM이다.(low level feature)
- CNN의 예측이 틀린 경우 분석 ( 오른쪽 그림에서 둘다 화산 그림. 근데 prediction을 하나는 sandbar, 하나는 car mirror로 잘못 예측 -> 나름대로 납득이 가는 오답이다 -> 이 예시가 학습이 망해가지고 안 되는 것인지 아니면 데이터가 그럴듯해서 틀린 건지 -> 무조건 틀렸다고 해서 모델을 뒤엎지말고 이런 부분을 고려할 수 있게끔 )

GradCAM의 예시 - 데이터셋의 bias 파악
- nurse와 doctor를 구분하는 모델 . 왜 잘못 파악했는지 보기 위해 GradCAM을 봄. 사람 얼굴이나 헤어스타일로 판단을 했구나~ 알 수 있음. -> 학습의 문제보다는 데이터의 문제라고 할 수 있다. 아 그럼 이제 간호사 남녀성비를 맞춰야겠다.
-> 청진기에 주목을 해서 잘 맞출 수 있게
- weakliy supervised(=이미지,클래스 label만 잇는데 그걸 가지고 detection/ segmentation에 사용하는 것=supervision이 있긴 있는데 약하게 있다) localization / segmentation에 활용
-> GradCAM을 하면 각 class에 영향력을 많이 미치는 부분이 나타난다. 그 부분이 target의 위치라고 판단하는 것이다 -> localization이 가능해지는 것.
-> seed 위치를 파악 -> classification label만 가지고도 object detection이나 segmentation을 할 수도 있다.

GAN : 인공신경망을 활용한 생성모델의 일종, 진짜같은 이미지,영상을 만들어냄
- 딥러닝 모델은 식별모델 / 생성모델이 있음. 식별모델은 decision boundary 가 중요
- GAN은 데이터를 생성하는 생성모델 : 데이터 x의 분포 P(x)또는 P(x,y)를 학습하는 모델
- 분포를 학습하게 되면 그 분포에서 sampling을 통해 새로운 데이터를 생성할 수 있게 된다.

GAN Generative Adversarial Network
- generator 네트워크가 데이터의 분포를 학습해서 랜덤 노이즈 z(랜덤한 시작점)가 주어지면 그것으로부터 데이터를 생성해낸다.

GAN의 네트워크 구조
- 크게 2개의 네트워크로 이뤄져있다. generator와 discriminator
1. generator : 랜덤 노이즈 벡터로부터 데이터를 만들어내는 모델
2. discriminator : 입력 이미지가 실제 이미지인지 생성된 이미지인지 판별.(binary classification)
만약 gen모델이 잘 만들었다면 discriminator는 판별하기가 어려워진다.
-> discriminator를 속일 수 있을 정도로 좋은 generator를 만드는 것이 목표이다. 즉 두 네트워크의 목표가 상반됨 -> Adversarial
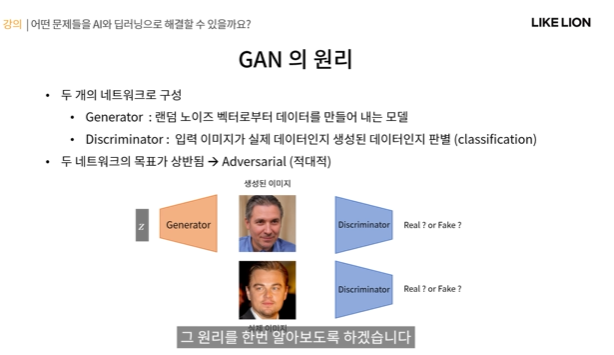
GAN의 원리
generator : 위조지폐범, discriminator : 경찰
- 위조지폐범 : 경찰이 지폐를 구분하는 법을 참고하여 안 걸리게 좀더 정교한 위조지폐를 만들도록 함.
- 경찰 : 더 자세히 검사하게 됨. -> 서로 상반된 목표를 가지고 학습. 즉 좋은 generator를 만들어 내는 것이 목표.

실제로 어떻게 학습 시킬까?
- loss를 통해 gen과 discrim을 동시에 학습하게 된다.
- G(z) : gen이 만들어낸 이미지.
- z : 랜덤 노이즈 벡터
- x: 데이터 분포에서 뽑아낸 진짜 이미지
- D(x) : x는 이미지가 되고, discriminator의 판별. 진짜면 1, 가짜사진이면 0 이 됨
- discriminator를 잘 학습시킨다면 반대로 저 loss값이 커진다. 즉 loss값이 커지게 하는 D를 찾고 싶은 거기에
maxD를 사용함(아래 수식)
- 만약 G가 학습이 잘 되어서 D가 진짜가짜를 잘 구별 못하면 D(G(z))는 1로 나오게 됨. ...G가 학습이 잘 되면 전체 loss값은 작아진다. 그래서 minG를 사용함
- 즉 G와 D가 서로 상반된 loss를 가지고 있음 .. adverserial
- D가 G보다 아무래도 쉽다보니까 학습 업데이트 주기를 D를 더 길게 주는 경우도 있다. G에 비해 금방 되니까.

GAN의 활용
- super-resolution : 고해상도로 복원
- style transfer : 말을 얼룩말로, 여름을 겨울로, 사과를 오렌지로 ..

- 그림으로 사진 만들기
- DeepFake

RNN - 순차데이터 처리
- 순차데이터: 순서가 의미 있는 데이터, 데이터 길이가 일정하지 않음. 시계열데이터, 사람의 말, RUL 등등, 염기서열, 동영상.. 단위로 나눌 수 있음 프레임별, 단어별, 시간별..
- 이런 데이터를 MLP에 넣으려고 하면? sequence 전체를 입력으로 넣으려하면 그 길이가 일정하지 않아 문제
sequence가 길면 앞부분 네트워크가 너무 커진다는 문제

-> 순차데이터에 특화된 모델 RNN이 등장
Recurrent Neural Network
- xt는 전체 sequence x중에서 t번째 단위. ( t번째 단어)
- RNN의 가장 큰 특징 : hidden layer에 자기자신으로 연결되는 recurrent connection이 있다는 것.
- 왼쪽 그림을 펼쳐서 생각한다면 오른쪽 그림같이 되는데 (x1 x2 x3 x4.. xt까지, h1,h2,h3...ht까지)
저 recurrent한 돌아가는 화살표가 오른쪽의 A-A를 연결하는 화살표랑 같게 된다. 그 화살표에서 전달되는 값을 hidden state라고 한다.
- hidden state : 입력으로부터 얻어진 정보를 다음 step에 전달해주는 역할을 한다. x0에서 얻은 정보를 x1에게 전달.
- A : fw라는 함수. A는 입력이 x1이오든 x2가 오든 다 같은 네트워크임.
- xt : t일때 input
- ht-1: t-1에서 온 hidden state
-> 현재 t input과 이전 스텝에서 받은 ht-1을 fw에 넣어서 현재 output = ht를 만든다. (그림에서는 output=hidden state인데 output layer를 또 붙일 수도 있다.)
- hidden state를 이용해 sequential한 정보를 전달하는 것이 RNN 구조의 핵심.

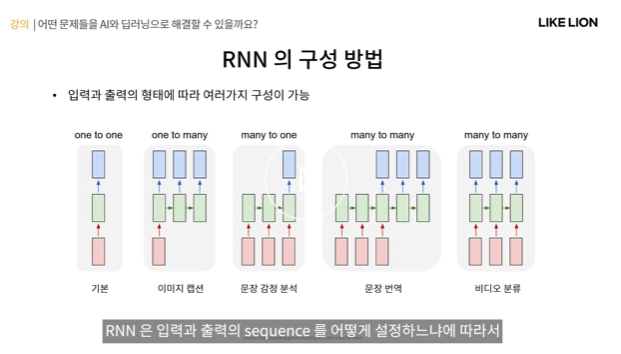
RNN의 구성 방법
- sequence를 어떻게 설정하냐에 따라 다양한 구조가 있음.
- 왼쪽 : len(sequence)=1 인 구조. MLP랑 다를 게 없다.
- 두번째 : 이미지 캡션, 이미지가 주어지고 그 이미지(1개)를 설명하는 문장(sequence)을 output으로 내는 것.
- 세번째: 문장 감정 분석, sequence를 1개로 (문장을 줬을 떄 그 감정이 무엇인가)
- 네번쨰 : input도 sequence, output도 sequence인 경우.
-> 세번쨰 그림 보면 input이 다 제공되고 나서 output을 내기 시작한다(빨간색 세개 끝나야 파란색 한개씩 나옴)
왜냐면 sequence(문장 전체)를 다 보고 output을 내야 하기 때문에.
-> 네번쨰는 그러나 한 sequence가 들어갈 때마다 output이 나오게 된다. 비디오 분류. 프레임마다 어떤 풍경인지 예측한다든지 등등.. 현재 t상태만 가지고 예측을 하기도 하지만 이전 상태 t-1까지 고려한다면 더 나은 모델을 만들 수 있기 때문.
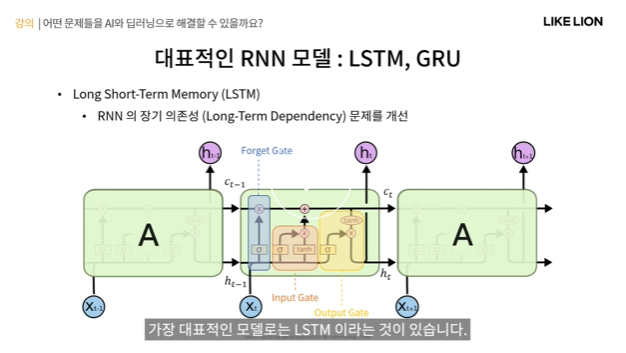
LSTM Long Short Term Memory
- 기본적인 RNN의 장기 의존성 문제 해결: hidden state는 매 step마다 업데이트가 되어야하는데, 만약 sequence가(문장 전체) 너무 길어지게 되면 앞쪽에서 얻은 feature 정보가 뒤쪽까지 전달이 되기 힘듬. 장기 기억이 약해지는 문제.
- c: long term state 장기기억
- h : short term state 단기기억
을 따로 관리해서 장기기억을 더 잘 보존하도록.
- A: fw인데 크게 세 부분이 있음.
1. forget gate : 장기기억 c에서 c의 내용을 지울지 말지를 결정
2. input gate : 현재 입력에 대한 걸 장기기억에 추가할지 말지를 결정
3. output gate : 네트워크 출력과 단기 기억을 담당.
GRU : Gated Recurrent Unit
- LSTM의 내부 구조를 간소화한 버전.
- c와 h가 hidden state하나로 합쳐짐, forget gate와 input gate를 합침.

RNN의 활용
- 자연어 번역(띄어쓰기 기준) 주가예측, 로봇 컨트롤 등등...
Attention Model
- 최근에 각광받는 모델.. 처음에는 sequetial에만 쓰였는데 이미지에도 쓰임
- 처음 등장 : RNN 기반의 순차데이터(sequence-sequence - 자연어 번역처럼 input,output이 모두 sequence) 처리에 한계가 있기 때문에.
- sequence-sequence 모델은 encoder-decoder 구조로 되어 있는데,
encoder : RNN을 통해 feature를 뽑아냄. 그 feature를 context vector라고 한다.
decoder : context vector를 받아서 RNN으로 output sequence를 하나씩 하나씩 생성해내는 구조.
-> 문제점 : input sequence(하늘색부분)이 너무 길어진다면 모든 input에 대한 것을 RNN을 통해 인코딩해서 단 하나의 context vetor로 인코딩하고 그 하나를 바탕으로 decoder에서 output을 만드니까 정보 손실도 많고 성능도 떨어질 수 있다.

-> Attention이 등장
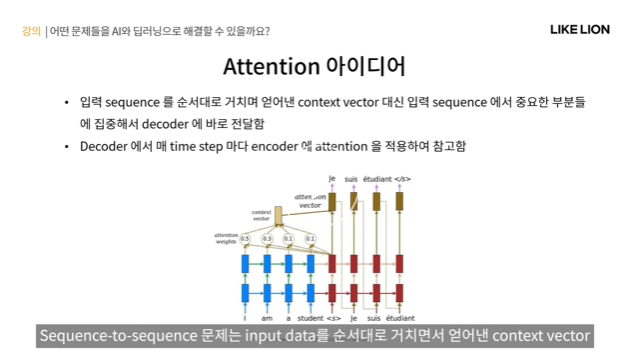
기존 RNN의 한계 : context vector하나에 의존한다.
-> 입력 sequence에서 중요한 부분에만 집중해서 decoder에 바로 전달해줄 수 있게끔 하는 것 : Attention
- decoder에서는 매 time step마다 encdoer에 attention을 적용해서 output을 만들게 됨.
어디를 attention할 것이냐는 보통 decoder feature과 encoder feature들이 얼마나 유사한가에 따라 결정되게 됨.
feature의 유사성이 클 수록 연관성이 있는 정보라고 생각하여 더 많이 attention을 하게 되는 식.
- input에서 encoder가 뽑은 feature들이 context vector가 아니라 그 뽑아진 feature 형태로 (저 황토색 노드들같이 생긴)
남아있음. 거기에 attention을 적용해서 decoder에 넣어줘서 decdoer가 output을 만들게 한다.
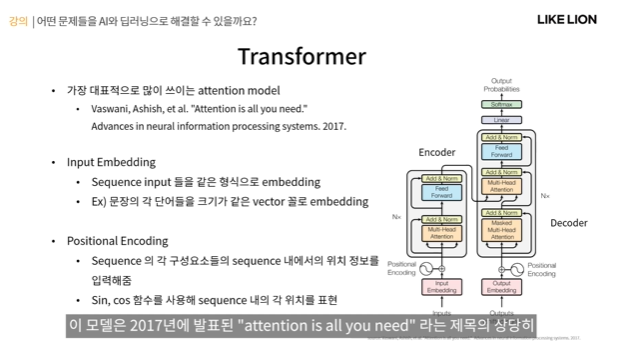
Transformer
- attention 모델 중 가장 많이 쓰이는 모델.
- transformer의 구조.
1. 먼저 input이 분홍색부분이 임베딩되어 주어진다.
2. positional encoding을 통해 위치 정보를 얻게 된다.
그 다음 저 박스친 부분이 인코더인데, 이렇게 preprocess된 input이 encoder에 들어가서 self attention을 해서 feature를 얻게 되고 그게 다시 decoder에 들어가서 decoder는 encoder feature에 attention을 해서 최종적으로 output을 얻는다.
- input embedding : sequence input들을 같은 형식으로 임베딩하는 단계(예를 들어 문장 .. 단어 길이도 다르고 다 다를텐데 각각 크기가 같은 vector꼴로 임베딩을 시켜서 적절한 형태로 바꿔준다.) - 보통 미리 정해진 방법을 사용한다.
- positional encoding : sequence의 각 구성요소들이 sequence내에서 어떤 위치에 있는지 그 위치정보를 입력해주는 단계. RNN은 hidden state를 통해 순서에 대한 정보를 알 수 있는데, transformer는 sequence가 순서대로 되어있지 않아서 각 input들의 절대적인 위치를 이런식으로 표시를 해줘야 함. - 보통 싸인,코싸인 함수로 만들게 됨.
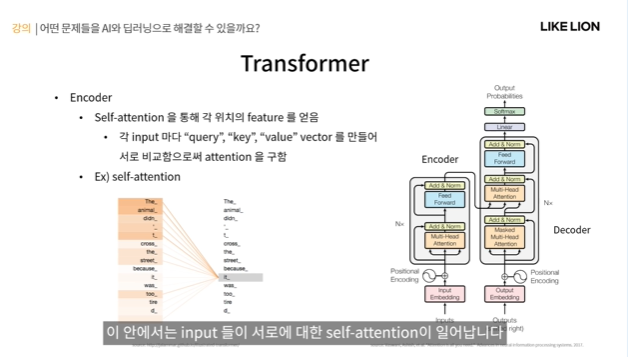
- encoder : 본격적인 인공신경망 부분
이 안에서는 input들이 서로에 대한 self attention이 일어난다.
self attention : 같은 시퀀스 안에서 서로 연관된 부분을 찾아낸다. (The animal = it .. it 입장에서 봤을 때 sequence에서 The animal에 attention score 점수를 높게 준다는 것.)
- attention 값은 그럼 어떻게 구하느냐? query와 key의 값을 비교하여 구하게 됨.
- query : 질문을 던짐, key : 그에 맞는 key
-> 각각의 input마다(The,animal,are,so..) query, key, value 이 세가지 값들을 vector를 만들어서 각자 가지고 있는데
예를 들어 The의 attention을 구하려고 하면 A의 query feature와 나머지들의 key를 비교하게 된다.
그럼 내가 던진 query랑 key가 비슷한 애들을 찾을 수 있는데, 비슷하면 비슷할수록 attention score를 높게 준다.
- 비슷한 feature일수록 연관성이 크다고 생각.
- attention : 가중치랑 비슷한데, 가중치에다가 최종적으로 각 input들의 value를 곱한 것이 input The의 최종적인 feature가 되는 것이다.
-> 정리하자면 구하고싶은 아이의 query와 나머지들의 key를 비교해서 attention을 구한다~
- decoder : encoder에서 얻은 input의 feature들을 이용해 output을 얻는 단계.
decoder의 query와 encoder에서 구한 key value를 이용해 encoder-decoder간의 attention을 구함.
저 중간부분 그림에 주황색 파랑색 저게 K,V가 key,value인데 self attention을 통해 최종적으로 구해낸 key와 value를 가지고 decoder에서 나온 query와 비교를 해서 feature들을 구하고 최종적으로 output까지 구해내는 것.

Tnrasformer의 활용
- sequence-sequence task는 대부분 transformer를 활용할 수 있게 된다. (자연어번역, 문장생성)
- attention : 중요한 곳에 집중한다.. 는 꼭 순차데이터에서만 쓰이진 않음.
그래서 컴퓨터비전에도 활용 - 예를 들어 이미지를 패치로 나눠서 순서대로 나열하면 마치 sequence처럼 됨.
각 패치들이 서로 어디를 주목하는지를 알 수 있을 것.
- 최근에 핫한 분야

Summary
