2022. 6. 12. 20:08ㆍ카테고리 없음
6주차 복습
- Cin Cout channel 의 input,output 수 / Hc Wc filter의 가로세로
- CNN으로 classification : Conv로 feature 를 뽑은 다음 그것을 vectorize해서 FC를 통과시킴

7주차에서 배울 것

대표적인 CNN 모델들
- ImageNet 챌린지에서 좋은 성능을 냈던 모델들
- ImageNet이 워낙 큰 데이터셋이다보니 ImageNet에서 학습된 네트워크들을 classification 말고도 다른 task에도 적용하기도 한다. 즉 backbone 네트워크 역할을 한다.

AlexNet
- CNN시대를 연 장본인, ImageNet에서 우승
- Top5 error : 모델이 뱉은 가장 자신있는 5개의 답 중 정답이 있으면 정답이라고 치는 성능 측정법
- 특징으로는 GPU 활용, Acitivation으로 ReLU, Data Augmentation , Dropout 적용
- 그림에서 보면 GPU를 두 개 활용했다. AlexNet은 CNN의 기본적인 구조를 가지고 있음.

Data Augmentation
- 데이터의 label을 유지한채로 transform시켜서 데이터셋 크기를 늘리는 방법
- overfitting 방지와 일반화 성능 향상.
- 원본 데이터에서 label이 바뀌면 안된다.
- 그리고 데이터 증강 시 주의해야한다. 예를들어 MNIST에서 6을 회전시키면 9가 되기때문에 오히려 학습에 더 헷갈릴 수 있음.

VGG Net
- Visual Oxpord 대학? 어쩌구에서 만든거라 이름이 VGG임.
- very deep 이다. conv layer, fc layer를 총 19개까지 사용(1억 4천4백만개 파라미터 수) / alexnet은 9개
- CNN을 많이 쌓으니까 성능이 좋아지더라.
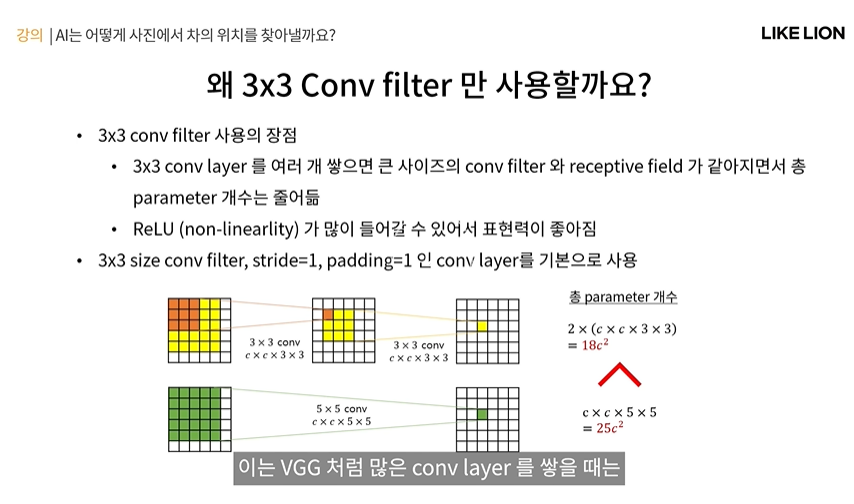
- 모든 conv filter 크기가 3x3으로 고정이다.

VGG는 왜 3x3 filter만 사용할까?
- conv layer가 많을 때는 3x3이 이득이 있기 떄문.
- parameter 수 이점: 3x3이 5x5,7x7처럼 큰 filter 쓸 때보다 receptive field 가 같아지면서 오히려 parameter 수가 적어진다.
- 아래 그림을 보면 저 오른쪽 노란색 한칸의 receptive field는 5x5가 되고, 초록색 한칸도 receptive filed 가 5x5가 됨.(노란색 filter 3x3, 초록색 filter 5x5 )
- 근데 총 파라미터 개수를 세보면 3x3이 파라미터수가 더 적음. 5x5는 layer 수는 적은데 파라미터 수는 많아서 모델 용량 학습 시간 등 불리하고 overfitting의 위험이 있다.
-> 즉 큰 conv filter 크기를 쓸 바에야 3x3짜리 layer를 여러개 쌓겠다.
+ layer가 많아지면 중간에 activation function이 많이 들어가게 되는데 더 많은 activation을 시키면 더 nonlinearity가 생기니까 더 표현력이 좋다고 한다.
- 이 외에 CNN들이 3x3을 많이 사용한다. 3x3에 stride = 1, padding =1 인 conv layer를 쓰면 input output feature map의 크기가 같아짐. 이 형태를 기본으로 많이 쓰고 거기에 input output channel 수만 정해주는 식으로 CNN을 설계함.
ResNet
- 요즘도 많이 쓰이는 CNN, 사람들이 VGG에서 감명받아서 막 layer를 많이 쌓아보았는데 많이 쌓는다고 무조건 성능이 좋은 건 아니었다.
- ResNet논문에 보면 아래 그림처럼 20layer가 56layer보다 오히려 성능이 더 좋았음..??!
-> gradient vanishng 또는 exploding 이라는 현상 때문.
- gradient vanishing : 모든 레이어가 순차적으로 연결되어 있으니 맨 뒤에서 계산되는 loss에 대한 gradient가 backpropagation 되면서 파라미터를 업데이트 해야되는데 layer가 너무 많다보니 그 gradient가 점차 사라짐. 그래서 맨 앞쪽에 있는 layer에서는 그 loss에 대한 gradient 영향을 거의 못 주게 됨.
- gradient exploding : gradient가 비정상적으로 커져서 발산해버림. 그럼 그 앞쪽은 다 업데이트가 제대로 되지 못함.
- gradient는 보통 바로 이전 layer로부터 기울기를 받게 됨. 근데 layer가 너무 많으면 기울기가 잘 전달되지 않는다?
그래서 ResNet은 layer들 간에 skip connection이라는 것을 만들었음. 이 skip connection이 있는 residual block을 제안해서 conv layer를 많이 쌓아서 만든 모델에서도 학습이 잘 되도록 한다.
- 무려 152 layer, 1101 layer 까지도 쌓아도 Top 5 error 를 3.57%로 사람보다 더 좋은 성능을 낸다.

Residual Block
- NN에서 학습이 잘 안되는 이유는 바로 직전의 layer에서만 입력을 받기 떄문임.
- 따라서 Residual Block에서는 skip connection이라는 것을 사용함.
- Residual Block 의 output H(x) = F(x) + x
- Residual : 통계학에서 출력값과 입력값의 차
- identity function : y=x 함수.
- ResNet은 바로 이전 layer의 영향없이 더 이전의 레이어 값을 직접 가져올 수 있다. (forward) 또한 back propatagion을 할 때도 skip connection을 통해 건너뛰어 gradient를 전해줄 수 있다.
- 맨 오른쪽 그림을 보면 단순히 두 단계 전 레이어끼리 연결해주는 게 아니라 더 여러 전 layer에도 skip connection을 해줄 수 있다.

Bottle Neck Block - ResNet에서 또 제안한 한 가지
- 1x1 conv를 활용해 파라미터 수와 연산량을 줄임. 주로 ResNet 50 이상의 큰 모델에서 활용.
- 1x1은 spatial 한 feature를 뽑을 순 없다. 대신 spatial 한 정보는 그대로 유지하면서 그 픽셀에 대한 channel수를 늘리거나 줄임.
(데이터 차원 압축)같은 느낌으로 사용 가능.
- 오른쪽 그림을 보면 1x1 conv를 활용한 Bottleneck Block은 맨 처음 들어가는 input의 channel size인 256이 그 다음 64로 줄어든 것을 볼 수 있음.
- 그 축소된 feature map에 3x3 conv 를 진행해 spatial 한 feature를 얻은 다음에 다시 1x1로 channel수를 256으로 늘려서 복구를 한 것임.
- 그러니까 3x3 conv 는 1x1에 비해 계산량이 많으니까 spatial 한 정보는 차원을 축소해서 얻고 평소에는 더 큰 channel수를 가져서 표현력을 늘리고자 한다.
- 맨 밑에 일반적인 경우 파라미터 수 : 18c**2이지만 BottleNeck : 17c**2 이므로 실제 파라미터수도 더 적어짐.

그 외 다른 CNN
- 이제 ImageNet 챌린지에 대해서는 관심이 식었다 충분히 좋은 성능을 냄. (ResNet)
- 이젠 모델 경량화에 (모바일, 등등) 어떻게 하면 파라미터를 더 줄이고 연산을 적게 하면서 성능을 높일 수 있을까
(MobileNet, SqueezeNet, ShuffleNet)

컴퓨터 비전에서 다루는 문제들
- classification , object detection , semantic segmentation(= lixelwise classifation , 이미지의 모든 픽셀이 각각 어떤 class에 해당하는 지 알아내는 문제 - 해당 위치가 어떤 class인지는 알아내지만 물체끼리 구분하지는 않는다, 큐브1큐브2큐브3이 아닌 다 같은 큐브로 - ex 차도와 인도 구분, 자동차 흠집이 난 곳이 어디인지, ) , instance segmentation ( object detection+ segmentation - object detection처럼 물체의 위치를 찾고 탐지를 하나 그것을 bbox가 아니라 pixel 단위의 윤곽선 mask로 예측을 함 - obejct detction과 비슷하지만 더 detail한 윤곽 예측)

Object Detection
- 물체의 bbox를 찾고 물체의 class를 알아내는 문제
- bounding box : x,y(=박스의 중심점의 좌표),w,h(bbox의 가로세로 크기) 4개의 변수로 표현. - 4dim regression = bbox regression
- classification은 class index로 표현.

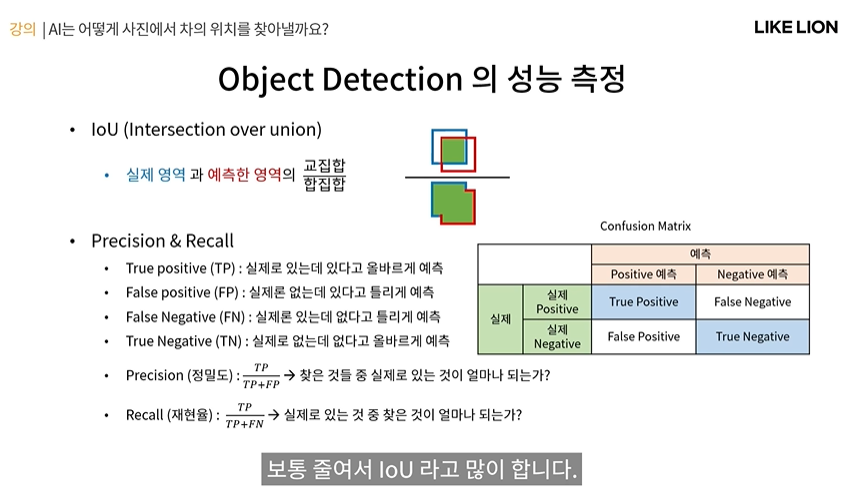
Object Detection의 성능 측정
- IoU( Intersetction over Union) - 실제 영역과 예측한 영역의 교집합/합집합
- Confusion Matrix : 오른쪽 그림 표 True False : 모델이 정답을 맞췄냐/틀렸냐(자전거라고 했는데 사람이었다. 자전거라 했는데 없었다) / Positive Negative : 모델이 예측할 때 타겟이 있다고 했는지 없다고 했는지(자전거가 있다 P, 없다 N)
- TP FP FN TN 아래 그림에서 설명 보기
- Precision (정밀도) : 찾은 것 중 실제로 맞은 게 얼마나 되는가? (찾은 bbox 중에서 얼마나 정확히 찾느냐?)
- Recall (재현율=검출율) : 실제로 있는 것 중 찾은 건? (bbox를 많이 찾느냐?)
PR , AP, mAP
- confidence score : 모델이 예측에 확신을 가지는 정도(내가 80% 확신하는데 이건 사람이다)
- confidence score는 미리 특정한 threshold값을 정해놓고 만약 bbox의 confidence 수치가 그 threshold보다 낮으면 그 bbox는 버린다. -> confidence threshold가 낮을 수록 살아남는 box의 수가 많아진다.
- 만약 극단적으로 threshold가 너무 낮아서 이미지 내의 모든 box들을 다 살아남게 한다고 쳐보자 -> model의 positive 예측이 엄청 증가함 -> 이 상황에서 recall은 높아진다. 근데 precision은 낮아진다
- 만약 threshold가 너무 높아서 box를 많이 버려서 진짜 확신있는 box만 남는다. precision은 높아질 수 있다. 하지만 false negative는 많아지므로 recall은 낮아진다.
- PR은 서로 반비례? 느낌이고 threshold를 바꿔가면서 PR(Precision-Recall) 곡선이 아래 오른쪽 그림이다.
- Average Precision (AP) : PR 곡선 아래 영역의 넓이. 성능 지표 ( precision과 recall 을 동시에 고려한, 절대적인 성능을 나타냄. P와 R이 둘다 높은 게 좋음.. 즉 저 곡선이 저 직사각형에 가까울수록? 좋음. 넓이가 넓어질수록)
- 그러나 PR곡선은 target class 하나에 대해서만 정해지기 떄문에 object class마다 서로 다른 PR 곡선들이 있기에
-> Mean Average Precision(mAP) : 클래스들의 총 평균 AP 를 구함.

ImageNet Pretrained Model
- ImageNet Pretrained Model은 general한 image feature extractor로 사용된다.
- 미리 학습된 파라미터를 고정시켜서 feature extractor로 사용하는 경우도 있지만 새로운 문제에 대해 추가적으로 학습하여 파라미터를 업데이트 해서 사용하기도 한다. 기존 학습할 떄보다 lr을 줄여서 파라미터를 많이 바꾸지는 않고 task에 맞게 finetuning을 한다고 한다. = transfer learning( 원래 classification task에 쓰이던 모델을 다른 task에 쓰는 것이므로)
- 왜 pretrained를 하냐? ImageNet 데이터셋이 워낙 크고 좋아서 이걸로 학습한 모델을 가져다 쓴다. 저걸 개인이 학습하기엔 시간과 비용이 든다.
- 또 ImageNet처럼 유명하고 큰 데이터셋이 MS COCO 데이터셋이 있다.

이제 CNN을 활용한 Object Detection 모델들을 보자
R-CNN ( Region CNN)
- 최초로 CNN을 object detection에 성공적으로 활용.
- 총 3단계가 있음.
1단계 : region proposal을 찾음( region proposal : object가 있을 것 같은 box의 후보를 지칭. - selective search라는 알고리즘을 활용해 이미지로부터 직접 2000개의 박스(저 아래 그림의 노란색 박스들)를 뽑는다. ) selective search : 이미지에서 경계선이나 색깔 등 feature를 이용해 물체가 있을 것 같은 곳에 bbox를 만들어주는 알고리즘.. 그러나 요새는 안 씀.
2단계 : 각 2000개 박스에 대해 CNN을 돌려서 feature를 뽑아냄. 이 논문에서는 CNN으로 AlexNet을 사용. 근데 저 2000개 박스들이 그림처럼 크기가 다 다르니까 warpping을 해서 이미지를 적절한 규격으로 만들었다고 함.
3단계 : region proposal에서 뽑아낸 CNN feature들을 가지고 최종적으로 SVM을 통해 classification을 수행하고 linear regression을 통해 bbox regression을 진행.
- 이러한 방법으로 PASCAL이라는 벤치마크 데이터셋에서 mAP를 53.3%를 달성함.
- 그러나 한계점 : 1. 2000개 모두에게 CNN을 적용해야 하기 때문에 frame당 13초나 걸림(너무느림)
2. SVM CNN selective search 등 너무 많은 모델들이 섞여있는 구성

Fast RCNN
- 개선된 RCNN, region proposal 마다 CNN을 돌리는 비효율적인 작업을 안 한다.
1단계 selective search를 통해 region proposal을 뽑는 것까지는 똑같다. 근데 그 다음에
2단계 region proposal 안에 이미지를 CNN을 돌리는 게 아니라 이미지 전체를 넣어서 spatial feature map을 얻는다.
3단계 전체 이미지 위에 만들어진 각 region proposal box에 대응되는 그 같은 영역을 이 feature map 상에서 찾아준다. -> RoI ( Region of Interest)
- 여러가지 크기의 박스들이 여러 가지 크기의 RoI로 만들어졌다. -> RoI pooling layer를 통해 같은 크기의 feature를 만들어준다. -> 그다음 그 feature를 가지고 task(classification이나 bbox regression)을 진행함.
- 핵심 아이디어: region proposal 끼리도 feature를 share하는 것.
- CNN 덕분에 feature map의 spatial한 위치가 실제 원본 이미지에서의 spatial 한 위치와 대응이 될 수 있다!
-> CNN을 한 번만 수행해도 되도록 알고리즘을 수정 -> frame을 2.3초로 줄이고 PASCAL 데이터셋 mAP도 66%가 나왔다.
그리고 SVM도 안하고 바로 classification을 했다. classification과 bbox regression을 동시에 학습함으로서 모델을 간소화하는데 성공.
-> 그러나 여전히 frame이 realtime으로는 어렵다.

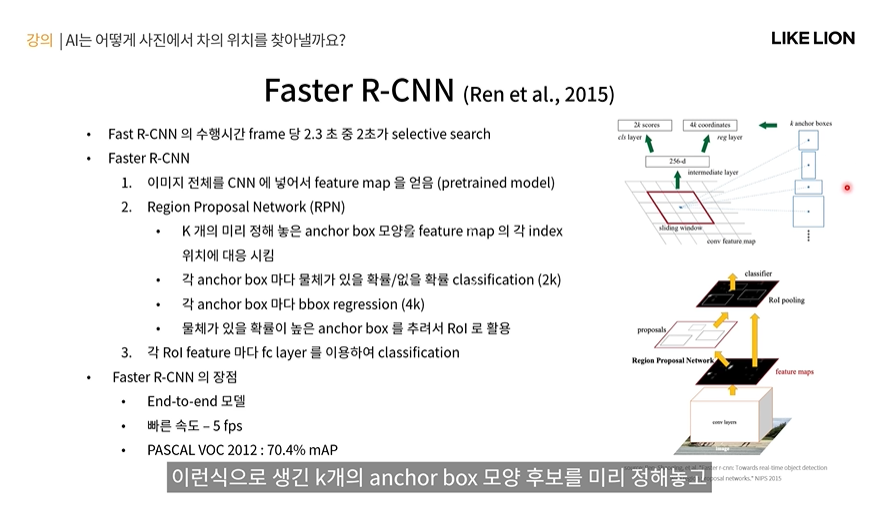
Faster RCNN 더 빨라진 ㅋㅋ RCNN
- frame 당 2.33초가 걸린댔는데.. 그 중 무려 2초가 selective search 때문이었다.
-> region proposal 할 떄 selective search를 버리고 NN으로 뽑아내자. -> region proposal 을 뽑아내는 네트워크 : RPN
RPN은 어디에 있냐, 처음에 이미지 전체를 넣어서 만든 CNN feature를 input으로 들어가는 RPN을 끼워넣게 된다.
RPN : CNN feature map을 input으로 받아서 region proposal 을 뱉는 네트워크
- RPN의 작동 방식 : 맨 오른쪽 파란색 박스들처럼 여러 모양으로 생긴 k개의 anchor box 모양 후보를 미리 정해놓고 feature map pixel마다 거길 중심으로 하는 k개의 box를 대조해서 박스마다 output을 뽑아내는데
1 일단 그 박스에 물체가 있을지 없을지 classification 결과를 뽑아냄. 2 feature를 봤을 때 anchor box를 어떻게 옮기면 좋을지 bbox regression도 수행하게 됨.
-> 그렇게 해서 anchor box들이 나오게 되면 그 중에서 물체가 있을 확률이 높은 anchor box들을 추려서 그것을 RoI로 활용
그 뒤로 그 RoI를 가지고 FC에 넣어서 classification을 하든 뭘 하든 함.
- 장점 : end to end 모델 (인공신경망만을 사용) / 빠른 fps = 5 fps(1초당 5 frame?) / 성능도 PASCAL에서 mAP 70.4%
그 외 CNN 기반 Object Detection 모델들
- SPPNet (Spatial Pyramid Pooling) 이라는 기법을 제안. feature map을 서로 다른 크기의 여러 종류의 grid로 자름.
-> 여러 scale 에 대한 feature를 얻을 수 있다. (여러 개의 pooling layer를 사용한 것이 피라미드 같아서)
- YOLO(You Only Look Once)
Faster RCNN은 RPN에 가서 region proposal의 RoI 영역에서 feature 로 classficaition 해서 2단계를 거쳐 output이 나오는데
YOLO는 한 단계에서 다 끝낸다. 그래서 속도가 매우 빠르다. 45 fps
- 하지만 bbox의 방향성이 떨어져서 Faster RCNN보다는 정확도가 떨어질 수 있으나 v2,v3,v4,v5 등 여러 버전을 업그레이드 중임.
- SSD(Single Shot multibox Detector)
- 앞쪽의 low level feature 도 detection에 적용을 한다. 그래서 높은 성능 PASCAL 에서 80% mAP를 달성.

AutoEncoder , Upsampling - Output을 이미지 형태로 만드는 방법
Semantic Sementaion
- Object Detection 결과 : bbox와 해당 영역의 classification
- Semantic Segmentation 결과 : 모든 픽셀에 대한 classification의 결과
하지만 모든 픽셀에 대해 일일히 CNN으로 classification을 하는 것은 너무나 비효율적.
-> output 이미지 꼴로 한 번에 여러 pixel에 대한 결과를 얻을 수 있는 형태가 좋을 것. -> encoder, decoder

Encoder, Decoder
- Encoder : input으로부터 feature를 추출하는 네트워크. feature의 크기를 줄이는 역할
- Latent Feature : Encoder를 통해 얻어진 feature
- Decoder : feature로부터 원하는 결과값을 생성하는 네트워크, feature의 크기를 키우는 역할.
-> encoder, decoder를 사용하면 한 번에 여러 픽셀에 대한 segmenation의 결과를 낼 수 있다.

Autoencoder
- Autoencoder : encoder-decoder 구조를 가지면서 입력과 출력이 같은 인공신경망
- Autoencoder 학습 : encoder에서 이미지의 적절한 feature를 뽑고 그 feautre에서 다시 원본 이미지를 복원해내는 deocder 네트워크를 학습시키는 것이다.
- 이를 학습시키기 위한 label은 따로 주어지는 게 아니라 입력 이미지 그 자체를 타겟으로 사용하게 됨. (즉 라벨은 output이미지와 원래 target 사이의 loss에 l2 norm 등을 적용하여 그 loss를 줄이는 방향으로 학습을 하게 된다.)

Autoencoder의 쓰임새
- Autoencoder의 장점: 따로 label이 없는 데이터에 대해서도 입력 feature의 정보를 담는 적절한 feature를 얻어낼 수 있다.(latent feature)
- 또한 그렇게 얻은 feature는 차원이 축소되어 중요한 정보만 살리는 효과가 있다.(PCA처럼 데이터 차원 축소)
- ex 아래 그림과 같이 디노이즈 (노이즈 제거)에도 활용 (입력으로 노이즈가 낀 이미지를 넣고 label로는 원본 이미지를넣어서 학습) - 원본 이미지 복원이 좋음.

Decoder를 실제로 구현을 하려면?
- 그냥 MLP라면 decoder 쪽에 feature size를 키워주는 식으로 설계하면 된다.
- 근데 CNN이라면??
- CNN의 encoder decoder가 있다면 latent feature map의 spatial size는 줄어들 것이다.
그 latent feature를 decoder에 통과시켜서 입력 이미지와 크기가 일치하는 output을 만드려고 하면 channel 뿐 아니라 feature map의 spatial size(가로 세로)도 키워야 한다. (upsampling)
- feature map의 upsampling 방법으로는 학습 파라미터를 사용하지 않는 경우 / 사용하는 경우가 있음
- 사용하지 않는 경우 : bilinear interpolation , nerest neighbor
- 사용하는 경우 : transposed convolution(deconvolution)
- 이 둘다 spatial 한 특징을 유지한다. (일반 MLP 처럼 vector면 spatial 한 특징을 잃어버림)

Bilinear Interpolation ( 학습 X upsampling)
- linear interpolation : 1차원 내적, 저 검은점 두개가 있고 그 직선 사이에 흰 점이 있을때 그 흰점 x를 어떻게 구할 수 있을까 -> 그 x를 구하는 식은 내분하는 식으로 성분을 계산하면 됨.
- bilinear interpolation : 위 내용을 2차원으로 옮긴 것. 아래 그림처럼 검은 점들이 주어졌을 때 흰점 x를 구하는 것. 각 축에 대해 linear interpolation을 각각 수행한 것과 같다.
-> upsampling에 적용 : 아래 오른쪽 그림처럼 원래 1,2,3,4만 있던 feature map을 더 큰 사이즈의 픽셀들로 만들어서 가장 가장자리들에 feature들을 놓고, 나머지 빈칸들에는 원래 있던 feature map의 값을 bilinear interpolation을 한다. ( 흰점들을 구한다) -> dense한 upsampling 결과가 나옴.

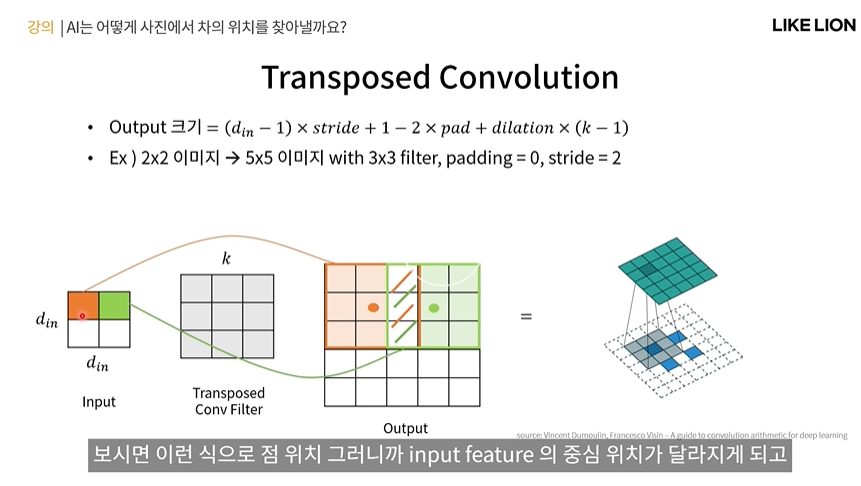
Transposed Convolution=Deconvolution (학습 O upsampling) stride=1일 때 그림
- convolution의 반대느낌. 원래 convolution은 conv filter를 input data와 convolution을 해서 feature map 하나를 output으로 내보낸다.
-> transposed convolution은 반대로 진행한다. input data의 한 feature 값이 output feature에서 필터 크기만큼 영역에 해당하게 된다.
즉 저 왼쪽의 주황색,연두색 그림을 다시 원래 픽셀값처럼 만들고, 혹시 겹치는 저 부분이 생기면 거기는 더해줘서 output을 낸다..?!
- output의 크기는 아래 식처럼 나오는데 dilation은 일단은 생각하지 말자(나중에 다룸)

Transposed Convolution (stride =2 일때 예시)
- 아까 위에서는 stride가 1이라 input이 output의 중심에 모여있었는데, stride를 2로 하면 input이 output의 가장자리에 배치됨.
Semantic Segmentation의 성능측정
- semantic segmentation은 pixelwise classification이기 때문에 classification 정확도와 그 위치의 정확도 모두 중요.
semantic segmentation은 항상 이미지의 모든 픽셀에 대한 결과를 내보내고 물체별로 구분하지는 않기에 object detection에서 썼던 mAP를 사용하기는 애매하다.
- mean IoU(=Intersection of Union) : semantic segmentation에서 많이 쓰이는 성능지표. 픽셀 단위로 IoU를 계산한다(IoU). class 별 IoU를 구한 것의 평균 mean IoU가 된다.
- segmentation에 많이 쓰이는 데이터셋 : PASCAL VOC(비교적쉬움) , MS COCO(어려움), Cityscapes(왼쪽 아래 그림)

그럼 지금부터는 semantic segmentation 모델들에 대해 알아보자.
FCN(Fully Connected Network)
- 대표적인 CNN을 활용한 semnatic segementaion 모델
- FC가 없이 conv layer로만 구성되어 있다! -> 입력이미지 크기에 제약을 안 받음.
- VGG16 을 backbone으로 사용. 원래 VGG에서는 FC layer에서 feature map을 vectorize해서 512x7x7 해서 (7x7 feature map을 input으로) 4096 vector를 사용했는데 FCN에서는 좀 다르게 쌓는다.
-> FC layer대신 512x4096x7x7 의 conv layer로 대신 사용. 여기서 filter 도 7x7을 사용하고 conv를 padding 없이 진행하면 input과 filter의 크기가 같아 output은 4096 channel의 1x1 feature map으로 나온다. 이 단의 최종 출력이 4096x1x1이 되서 FC 썼을 때랑 똑같이 결과가 나옴. -> 512x4096x7x7 이 매우 큰 숫자인데 conv filter를 재활용 할 수 있게 된다.
- 기존 VGG는 규격이 224x224였고 마지막 conv를 거치면 7x7 feature map이 나오는데 만약 224x224보다 더 큰 이미지가 들어온다면 마지막 conv 의 feature map도 7x7보다 더 커질 수 있다. 그 떄 아까 쓴 filter 512x4096x7x7 filter를 쓴닫ㄱ도 하더라도 output이 1x1이 아니라 spatial한 정보를 유지한 feature map이 될 수 있는거다.
- 즉 FCN은 FC layer까지는 backbone 네트워크와 동일하게 해서 feature를 구하고 마지막만 1x1 conv를 거쳐서 output class 개수 만큼으로 channel=21로 줄였다.
- 그럼 저 그림에서 빨간색 네모 부분은 각 픽셀이 21 channel을 가진 어떤 feature map이 되는데 저 feature map에 bilinear interpolation을 활용해서 입력 이미지와 같은 크기까지 키워준다.
-> 입력이미지와 동일한 output 이미지의 크기가 되고 채널은 21 channel이 되는 우리가 원하는 꼴의 semantic segmentation output이 된다.
- 그럼 그 21개의 channel 중 가장 값이 높은 것이 해당 픽셀의 class가 되어 보라색,갈색,초록색 처럼 나뉘게 되는 것이다.
- output이 일반 classification처럼 한 값이 나오는 게 아니라 입력 이미지 크기에 따라 feature크기도 다르고 output크기도 그에 맞게 달라짐. 입력 이미지 크기에 제한을 받지 않음.

그런데 1/32로 줄인 feature를 다시 32배로 bilinear upsampling을 한다면 디테일한 정보는 하나도 없는 coarse한 정보만 담게 된다. (아래 그림에서 FCN 32 라고 적힌 그림처럼)
-> 그래서 FCN에서는 마지막 conv feature와 함께 pooling을 덜 한 CNN 중간 feature들을 가져와서 거기로부터 정보를 얻어서 좀더 디테일한 정보를 살리는 방식 사용.
- 1/32을 바로 32배하는 게 아니라 이전 pooling을 덜한 feature를 가져와서 그걸 16배 해서 키우고(FCN 16)
- 또 1/8을 8배 해서 키우기도 하고 FCN 8 ( 1/8크기의 feature map을 사용했다는 것인데 pooling 을 덜 한 layer의 feature를 사용할수록 디테일이 살아난다.

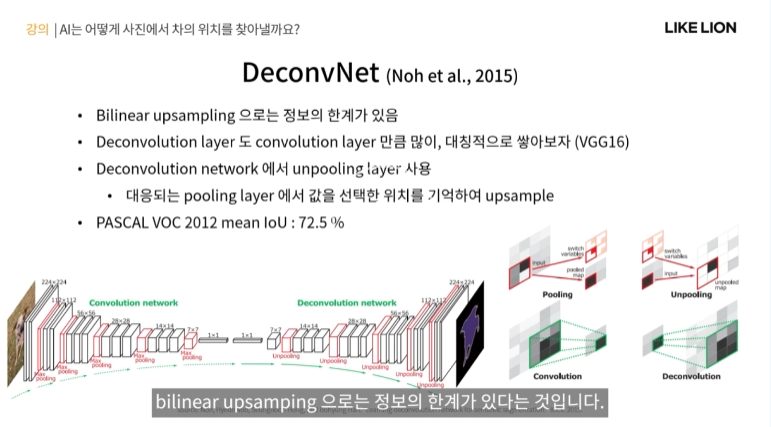
DeconvNet
- 한국인이 쓰신 논문. 요지는 bilinear upsampling으로는 한계가 있다!
-> convolution했던 layer만큼 deconvolution도 대칭적으로 많이 쌓아보자
- 인코딩단: VGG 16 / 디코딩단: VGG 16? 인코딩단: maxpooling -> 디코딩단: unpooling
- unpooling : maxpooling이라면 저 4칸 중에서 가장 높은 칸을 가져왔을 텐데 4칸 중 어디서 가져왔느냐를 기억해놨다가 unpooling할 때 upsample할 떄 빈칸이 생기면 그 값을 어디에 넣어줄지 대응되는 maxpooling을 통해 알게 되는 방식.
- PASCAL에서 mean IoU 72.5% 성능
UNet
- 구조가 U자처럼 생겨서
- 핵심 아이디어 : skip connection 저 그림에서 한번에 가는 화살표
U자만 따라가면 encoder, decoder 형태인데 encoding할 때 얻은 여러 크기의 feature map을 가지고 있다가 decoder에서 upsampling하면서 그 feature map이 다시 같은 크기가 되었을 때 skip connection으로 직접 feature map을 바로 연결해주는 구조.
-> 이렇게 하면 decoder에서 high level feature와 더불어서 encoder에서 얻은 low level feature들도 segmentation map을 만들 때 활용할 수 있게 되어 더 디테일한 결과를 생성할 수 있다.
- 의학 저널에서 저술되었지만 뛰어난 모델이라고 한다.

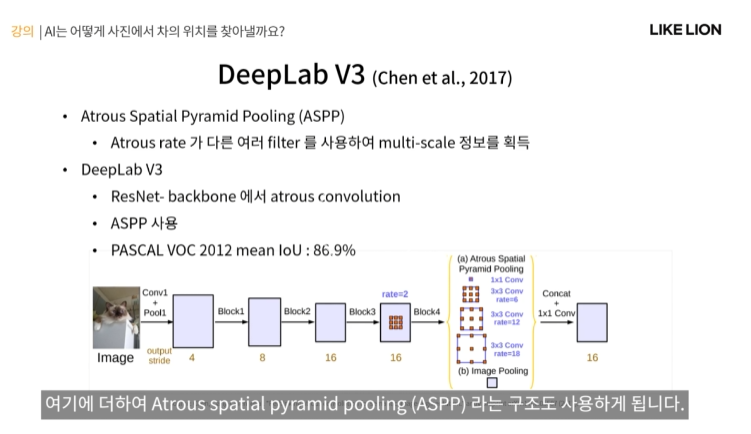
DeepLab V3
- DeepLab은 v1~v3+까지 있는데 v3에서 핵심 아이디어가 정립이 많이 되었다.
- 핵심 아이디어: atrous convolution : dilated convolution (feature output size계산 공식에 나온 그 dilation)
- Atrous convolution : convolution filter가 꼭 맨 주황색처럼 꼭 붙어있을 필요가 없이 중간에 빈칸을 두어 오른쪾 가운데처럼 확장시켜 사용할 수 있다는 것이다.
-> 이런 filter를 사용한다면 똑같은 3x3 filter를 사용해도 receptive field가 넓어진다.
- 왜 atrous convolution을 사용할까? 이걸 pooling 대신 사용할 경우 spatial 정보 손실을 줄일 수 있다
- pooling을 많이 할 수록 spatial 정보의 손실이 일어난다. classification같은 경우는 괜찮을 수 있는데 semanctic segmentation은 이미지의 detail한 부분들이 필요하다. 여기서 pooling의 문제를 느낀 것.
- pooling은 데이터 요약 뿐 아니라 receptive field를 늘리는 역할도 한다. (같은 3x3 이미지더라도 pooling을 하고 conv를 하면 더 멀리있는 feature 들과의 연관성도 학습할 수 있다)
왼쪽의 1 dilated(=atrous rate) 가 일반적인 conv, 2dilated,3dilated는 띄워져있는 atrous conv이다.
오른쪽 그림은 donwsampling, conv, upsampling했을 떄의 결과와 atrous convolution했을 떄의 결과를 비교한 것인데
결과가 잘 나왔다.

- DeepLab V3는 Atrous Spatial Pyramid Pooling이라는 ASPP 구조도 사용한다.
- Spatial Pyramid Pooling : 여러 가지 다양한 크기의 pooling을 통해 다양한 크기의 feature를 얻는 방법.
- ASPP : atrous rate가 서로 다른 여러 가지 filter들을 사용해서 입력 feature map에 대한 multi scale 정보를 얻게 된다.
1 dilated의 작은 filter를사용하면 가까운 feature 정보를 잘 얻을 수 있고, 3dilated의 큰 filer를 사용하면 더 멀리 있는 feature의 연관성을 얻을 수 있다.
- 여기서도 pooling 대신 atrous convolution으로 pooling을 대체한 것을 알 수 있다.
- 그래서 정리하자면 ! 최종 DeepLab V3의 구조는 아래와 같다. pooling을 아예 안 쓰는 건 아니고 앞쪽에 아직 feature map의 크기가 클 떄는 문제가 안되기에 pooling을 쓴다.
- 그리고 뒤쪽 layer들 가면 pooling대신 atrous conv를 쓰는 것이다.
- PASCAL mean IoU 86.9% 달성.
DeepLab V3의 결과들
- 왼쪽 PASCAL 오른쪽 Cityscapes
- ResNet처럼 현재 성능이 최고인 건 아닌데

Summary
