2022. 6. 12. 11:41ㆍ카테고리 없음
지난 주 복습
- norm regularization : 모델 parameter의 norm값을 넣어 모델의 복잡도를 낮춤?
- early stopping : 성능이 더 나아지지 않으면 학습 멈춤
- dropout : parameter의 일부분을 랜덤하게 0으로 대체함
- batch normalization : activation의 분포를 원하는 형태로 만들어 학습과정을 안정화.

6주차 목차
- padding, stride : feature map의 크기를 결정함
- feature map: CNN에서 hidden layer를 표현하는 방법.

컴퓨터 비전

컴퓨터비전 예시
왼쪽 : segmentation
오른쪽위 : object detection
오른쪽아래 : GAN

컴퓨터가 어떻게 이미지를 인식할까?
- 이미지를 구성하는 픽셀들의 값을 숫자 데이터로 처리함.
- 아래 숫자 손글씨 데이터의 경우 28x28개의 픽셀이 있고, 흑백이미지의 경우 픽셀 하나당 0~255 중 하나의 값을 가지고 있다.(0 흰색 ~ 255 검은색)

이미지 화질은 얼마나 많은 픽셀이 있냐에 따라 결정됨. 따라서 화질이 좋을 수록 데이터의 크기가 엄청나게 많아진다(28x28이 아니라 1024x1024 등등)
칼라 이미지의 경우 각 픽셀당 빨강,초록,파랑이 조합되어 최종 색이 표현됨.
따라서 컬러 이미지는 각 픽셀당 3개의 채널이 필요하다.
- 흑백 이미지 HxW 인 반면 칼라 이미지는 HxWx3 개의 픽셀이 있음.

이미지 특징을 어떻게 찾을까
- feature (=keypoint) : 주위 배경과 구분되면서 찾기 쉬운 특징
- 예를 들어 얼굴인식 같은 경우, 규칙성을 찾아서 찾을 수 있었음
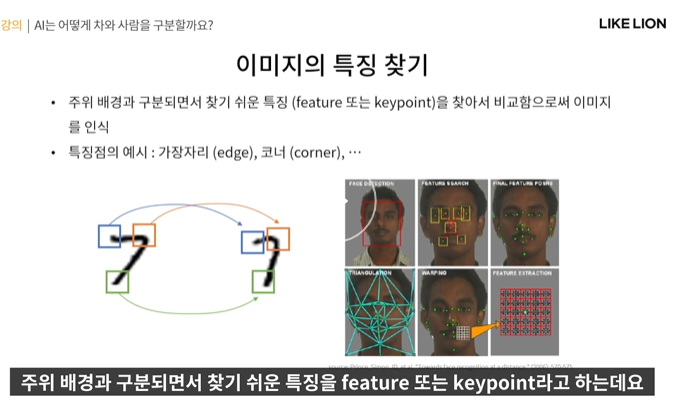
그런데 만약 개와 고양이를 구분해라..처럼 복잡한 이미지의 경우는?
- 규칙성 찾는 거로는 어렵다.

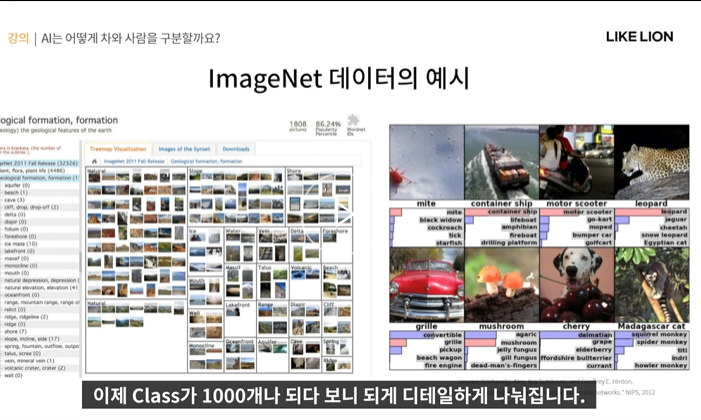
그러다가 Image Net Challenge라는 게 등장한다.
- 1000만장의 라벨링된 데이터를 가지고 classification, detection 등 성능을 겨루는 대회

ImageNet은 class가 1000개나 된다.
평가 기준 중에는 정확히 맞추는 Top1 정확도 지표도 있는데 Top5 지표라는 것도 있다.(5개 중에 정답이 있으면 맞춘 것으로 인정)
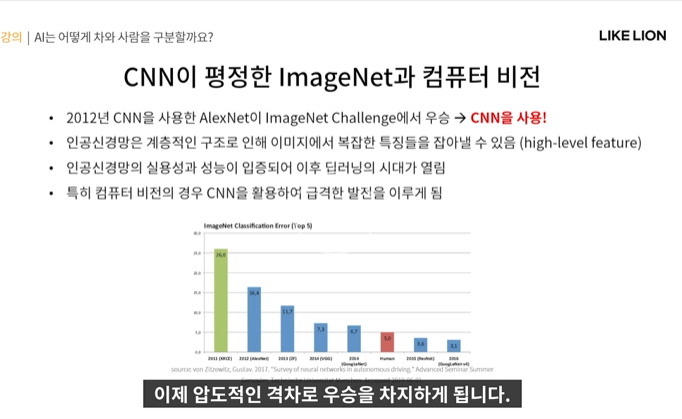
이 때 등장한 것이 CNN
2012년 CNN을 활용한 AlexNet이 ImageNet 대회에서 우승
- 손으로 규칙성을 찾는 게 아닌 인공신경망(CNN)으로 이미지의 복잡한 feature를 잘 추출한 결과라고 볼 수 있음.
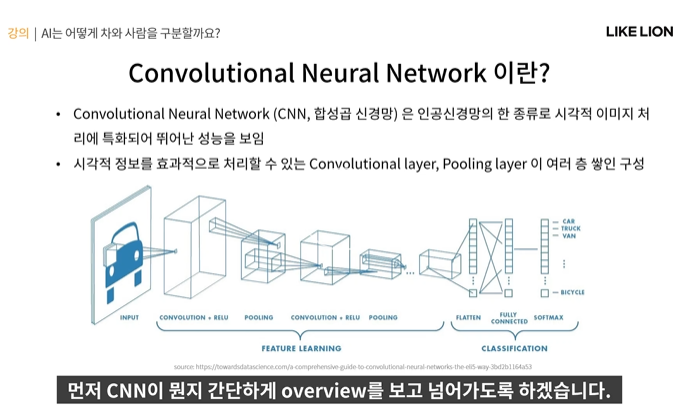
그럼 이제부터 Convolution Filter (CNN의 기본 Operator)가 무엇인지에 대해 배워보자
CNN이란?
- Convoluational Neural Network
- 기존 MLP(multi layer perceptron)와 다르게 Convolutional layer, Pooling layer가 존재.
Convolution이란?
- convolution은 함수 f를 가만히 두고 함수 g를 t축으로 뒤집은 채 평행하게 움직일 때 각 위치에서 두 함수가 얼마나 비슷한지를 나타내는 것.
- 두 함수가 비슷하게 생겼을 수록 저 f*g가 커지고 전체 적분값, t에서의 convolution 값은 커지게 된다.

두 함수가 가장 잘 겹쳐지는 순간에 노란색 넓이가 제일 크고, convolution 값도 제일 크다.

위는 1차원이고, 그럼 이미지와 같은 2차원에서는 convolution이 어떻게 작용할까?
- 일단 변수가 t대신 i,j이다.
- 그리고 저 초록색 필터(convolution filter = kernel)가 움직이면서 이미지를 훑으면서 feature를 뽑아낸다.(sliding window)

그럼 convolution이 이미지 인식에 어떻게 쓰일까?
- 저 f에 해당하는 게 가만히 있는 이미지인거고, g가 움직이는 filter = kernel임.
- 즉 g와 f가 유사한지를 나타내주는 게 conv인데, convolution filter가 어떤 특정한 feature를 나타내는 값을 가지고 있으면
이미지 위에서 sliding window를 해나가면서 그 위치에서 그 filter와 대응하는 원본 이미지의 feature와 비슷한게 얼마나 많은지를 볼 수 있다.
- 예를 들어 얼굴인식, filter가 얼굴처럼 생겼다 그럼 원본 이미지 위에서 filter가 이동하면서 어디에 이 얼굴처럼 생긴 비슷한 구조가 있나 찾아나가며 얼굴을 찾을 수 있다는 것이다.
- filter map : 원본 이미지와 filter의 convolution을 통해 얻어낸 결과값

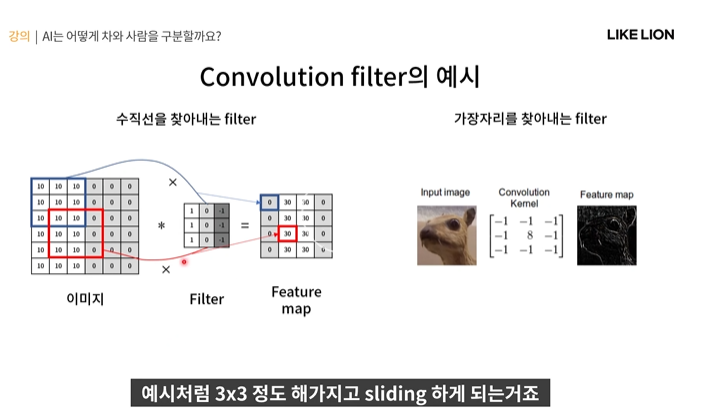
간단한 예시
- 보통 filter는 원본이미지보다 작다. 3x3을 많이 씀..?
- 아래 예시에서는 filter가 수직선 모양이다. 111 000 -1-1-1 그렇게 되면 저 원본 이미지에서 가운데부분 101010100000
된 부분이 filter가 가장 비슷하게 생겻을 것이다(빨간 네모부분). 따라서 feature map도 해당 부분에서의 conv 값이 30으로 높게 나옴(빨간 네모 부분)
- 그럼 결론으로 나온 feature map을 보면 0000 30303030인 구조가 나오는데, 30이 값이 크다는 것은 filter와 비슷하다는 뜻이니까 즉 가운데에 수직선이 많이 있다. 많이 activate 되었다. 라는 걸 알 수 있다.
오른쪽 예시는 edge를 찾아내는 filter임 -1-1-1-1이고 가운데만 8임.
- 수직선처럼 서로 확연히 다른 두 부분의 경계를 나타낼 수 있음. 단 수직선과는 다르게 방향이 정해져 있는 것이 아니기 때문에 대칭적으로 filter가 디자인되었다.
- 아무튼 edge filter를 사용한 결과 feature map 결과처럼 원본이미지의 edge를 잘 따낸 모습을 볼 수 있다.
- filter 하나 당 feature map이 하나씩 대응된다. (수직선필터 - 수직선피쳐맵, 엣지필터 - 엣지피쳐맵..)
그럼 저 feature들이 특정 feature와 매치된다고 하는데 그럼 이걸 활용하려면 내가 필요한 feature가 어떤 건지 다 알아야되고 또 그에 대응되는 filter 모양도 다 직접 설계해야되는 거 같은데 그걸 어떻게 하지?
-> 인공신경망. 파라미터들을 직접 설계하는 게 아니라 학습시키는 것이었다.
-> convolution filter도 우리가 미리 설계하는 게 아니라 학습을 통해 구하도록 하는 것이 CNN의 원리이다.
-> 신경망을 잘 학습시킨다면, 그 이미지를 이해하는 데 필요한 feature가 무엇인지 filter는 어떻게 생겼는지까지 자동으로 학습.
- convolutional layer : convolution filter를 통해 feature map을 얻는 layer
저 아래 그림처럼 색깔, 선 등의 feature를 지 스스로 잘 학습한 것을 알 수 있음.
그런데.. 사실 엄밀히 말해서는 convolution이 아닌 cross-correlation이라는 걸로 계산하는 경우가 많다.
cross correlation은 conv랑 거의 비슷한데 g함수를 반전시키지 않고 그대로 sliding해서 f랑 겹치는 부분을 구하는 연산임.
그래서 cross correlation이나 conv나 관습적으로 conv라고 그냥 부름.

입력 데이터에 여러 채널이 있을 때 convolution(컬러 이미지)
- RGB는 사실 2차원이 아닌 3차원이다.
- 따라서 filter도 3x3이 아니라 3x3x3(RGB) 로 진행을 한다.
- 만약 3차원이 아니라 더 channel이 많아진다고 해도 filter의 channel에 맞춰서 convolution을 하면 됨.
- CNN에서는 conv layer가 하나가 아니라 여러 layer를 쌓는다. -> 뒤쪽 conv layer에서는 input이 앞쪽 conv layer에서 나온 feature map이 된다. 그리고 feature map은 filter 하나 당 하나 대응이기에 여러 filter를 쓰면 featuremap도 여러개가 된다. 따라서 원래 WxHx3 RGB 이미지가 아니라 channel 수가 3개 이상 더 많아지게 될 수도 있다.

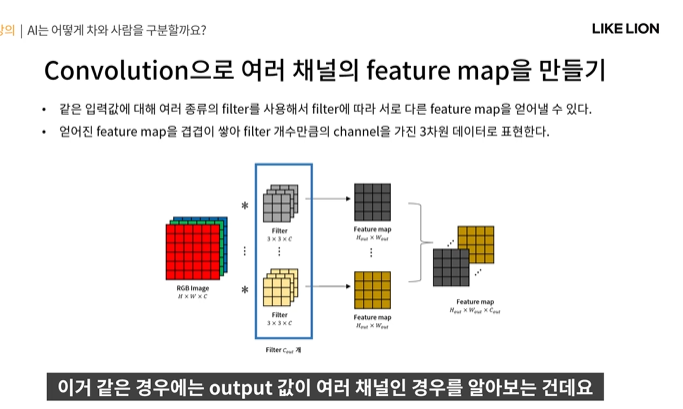
Output을 여러개 만들기(여러 채널의 feature map 만들기)
- 같은 input에 대해 여러 종류의 filter를 사용해 여러 종류의 feature map을 얻어내게 되는데
- 입력값이 여러개여도 filter가 그 channel 갯수만큼 dimension을 가지게 되면 feature map은 2차원인 WxH만 나오게 되는데 그게 C_out개 있으면 WxHxC_out으로 3차원이 되는 것..!?
- 그리고 뒤에도 계속 convolutional layer들이 쌓이면 그 feature map들이 또 input으로 들어감.
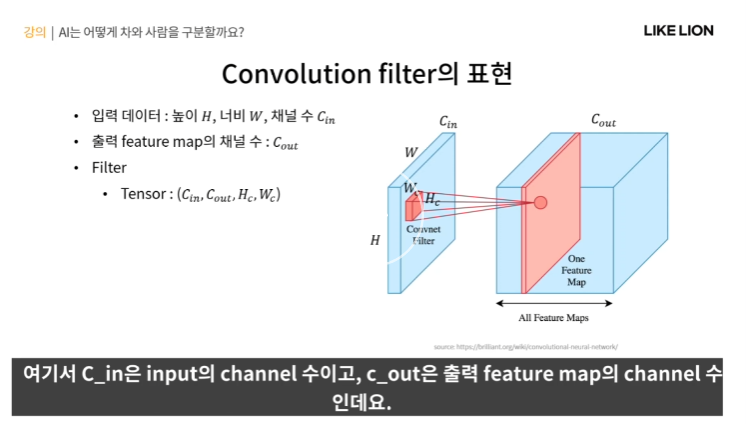
Convolutional Filter
- Cin 은 input의 channel 수 , Cout은 출력 feature map의 channel 수
- 총 4차원 텐서로 convolution filter를 표현함. (저 그림 안에 있는 인자들로) - 4차원 행렬같은 개념
- 저 조그만 빨간색이 filter인데 저걸 가로세로로 sliding 하면서 feature map을 만드는 것.
CNN의 구성
- Convolutional layer
- Activation layer : sigmoid, ReLU
- Pooling layer : feature map의 크기를 줄여 계산량을 줄이고 overfittin을 억제
- FC : MLP에 기본적으로 쓰이는 layer, vector 형태의 input을 받아서 vector 형태의 output을 내보내는 layer. 그 네트워크 상의 뉴런들이 모두 연결되어 있어 FC라고 부름.

Convolutional Layer
- Cin, Cout, H, W를 파라미터로 가지는 layer로서 FC와 비교하면 FC는 vector로 이뤄져있는데 Conv layer에서 학습할 파라미터는 Cin x Cout x H x W 개가 된다.
- input을 가지고 Cout x H x W의 output을 출력하는 layer
- high level feature : 복잡한 고차원 feature 색이나 edge .. 이런 건 단순한 feature. low level feature.
그런데 high level feature는 좀 더 복잡한 feature. 예를 들어 고양이만이 가진 특성, 개가 가진 특성 등..
low high 둘다 중요함.

Pooling layer
- feature map의 spatial size를 줄이는 layer
- spatial size ? 공간적인 사이즈. channel size : feature map의 개수
- pooling feature가 있어서 대표값을 output으로 보낸다.
- pooling layer는 채널별로 독립적으로 작동함 -> pooling filter는 3차원이 아닌 2차원
- feature map을 공간적으로 요약하는 역할..? 불필요한 파라미터나 연산량을 줄여서 overfitting을 억제하기 위해
- 이미지 데이터는 크기가 큰 편.

Max Pooling
- pooling layer의 filter 영역 내에서 가장 큰 값을 대표값으로 뽑음.
- feature map에서 값이 큰 픽셀 - 해당 영역에서 많이 activate 됐다. (filter 랑 많이 비슷하다)
그래서 저 일정 영역 (빨,초,노,파) 내에서 가장 활성화가 많이 된 feature값을 뽑아서 불필요한 feature를 줄인다.
- stride : 얼마나 간격을 띄워서 sliding을 할 것이냐 ( 그림에서는 stride가 2이다)
- pooling할 때는 stride를 2 등으로 줘서 겹치지 않게끔 이동을 시킨다.

CNN layer의 비교
- parameter : 학습을 통해 얻어지는 변수값
- hyperparameter : 사람이 학습 전에 미리 지정해줘야 하는 값.
- convolutional filter : filter를 학습하니 parameter는 당연히 있는거고, hyperparameter는 convolution filter의 가로 세로 사이즈, convolution filter의 output channel 개수(Cout), stride 등등이 있다.
- activation은 feature 값을 sigmoid, ReLU에 넣어서 비선형성을 줌. 학습이나 하이퍼파라미터가 필요 없다.
- pooling은 학습하는 값은 없지만 filter 크기, stride는 사람이 정해줘야함.
- FC 학습을 하고, 하이퍼파라미터로는 output channel의 크기가 있음.

여러 layer를 거친 뒤쪽의 feature map은 어떤 정보를 담고 있을까?
- output feature map에서의 한 픽셀은 input feature의 3x3 pixel의 정보를 담는다.
- 비슷한 형식으로 3번째 layer의 feature map은 첫번째 feature map의 5x5 pixel의 정보를 담음.
- receptive field : 한 feature 값을 얻는데 사용된 입력 데이터의 범위의 크기.

receptive field는 layer를 거칠 수록 커진다. 계층적으로 쌓인 feature는 복잡한 의미를 담기 시작한다.
- high level로 갈수록 더 많은 layer를 거친 feature
- channel 수가 보통 128,265,512 채널 이렇게 가기 때문에 여러 조합 feature를 얻을 수 있다.

CNN을 이용한 classification
- 2차원 이미지가 conv layer와 pooling layer를 지나면 WxHxC의 3차원 feature map이 된다. 그 3차원 feature를 vectorize해서 그 뒤에 FC를 거치고 마지막 FC에서 클래스 개수만큼 output vector를 만들면 CNN 기반 classification 네트워크가 되는 것이다.
- FC부터는 MLP 랑 비슷. ( feature를 vectorize한 이후부터는 MLP와 동일)
- subsampling = pooling
- vectorize는 저 오른쪽 그림의 맨 위에 긴 행렬처럼 2차원 이미지를 벡터처럼 길게 만든 것.
- 또는 3차원 feature를 vectorize하지 않고 그 자체로 MLP와는 다른 방법으로 output을 내기도 한다.

왜 이미지 인식에서 CNN이 더 유리한지
-1.학습할 파라미터 수.. 이미지는 엄청나게 큰 데이터라 FC로 해결하려고 하면 파라미터 수가 너무 많다.
-> overfitting이 생기거나 파라미터가 모두 중요한 파라미터만 있는 것도 아니어서.. 문제
- 근데 CNN은 convolution filter 크기만큼의 파라미터만 필요하다. CNN 파라미터 개수 : WxHxinput channle 개수 x output channel 개수가 총 파라미터 수.
- 2. local connectivity : 기존의 MLP는 spatial 한 정보를 고려하지 않고 그냥 모든 픽셀을 하나하나 본다(이미지면 가로,세로의 특징이 중요한데 .. 즉 주변의 픽셀값이 중요하고 저 멀리 떨어진 픽셀은 필요없다)
-> 근데 CNN은 주변 정보로부터 filter를 활용해 feature를 차근차근 모아가며 쌓는다.
- 3. 이미지 크기에 구애받지 않음. MLP는 데이터를 벡터로 만들어서 사용하기에 처음에 정의하는 WxHx3 크기만큼의 벡터가 input 크기가 정해져있다.
-> 근데 CNN은 sliding 을 통해 이미지 크기가 달라져도 feature를 뽑을 수 있따.

Feature map의 크기를 정하는 요소 1. padding, 2. stride
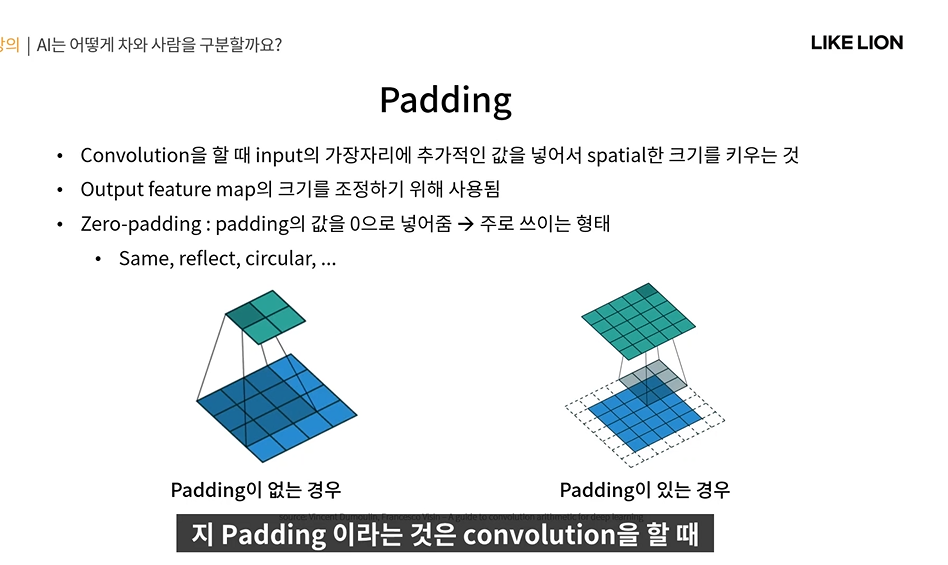
Padding
- convolution 할 때 input의 가장자리에 가짜 값을 넣어서 spatial 한 크기를 키우는 것. input을 확장
- 만약 왼쪽 그림처럼 padding이 없는 경우로 한다면 가장자리를 중심으로 하는 feature들은 버려지게 된다.
그런데 오른쪽처럼 padding을 넣어주면 모든 부분이 중심이 되는 경험을 할 수 있음. filter의 중심이 픽셀을 한번씩 다 지나가야 output feature map의 크기가 유지되기 때문.
- zero padding : 0값으로 채움. 보통 / same padding : 최외곽 값으로 채워줌.
Stride
- convolution 에서 sliding window를 얼마 간격으로 할 지.
- stride = 2 , 두 픽셀 당 한번 건너서 결국 output feature map의 크기는 input*1/stride

Feature Map 크기 계산 공식 ( 저 절댓값아래 조금 삐저나온 기호는 내림 기호)
- stride : 몇 픽셀씩 건너뛸 것인지 결정
- 이 부분은 엄청 핵심은 아니지만 CNN을 돌릴 때는 파악하고 있어야 하는 부분이다.

Summary
