2022. 6. 4. 19:10ㆍ카테고리 없음
4주차 복습
- 그냥 linear만 쌓으면 결국은 a*b*x = cx로 표현, 결국 선형이 되므로 비선형인 activation function을 포함하는 MLP를 사용한다.
- loss function : classification은 cross entropy, regression은 미분이 가능하고 표현이 간단한 MSE를 사용.

5주차 목차
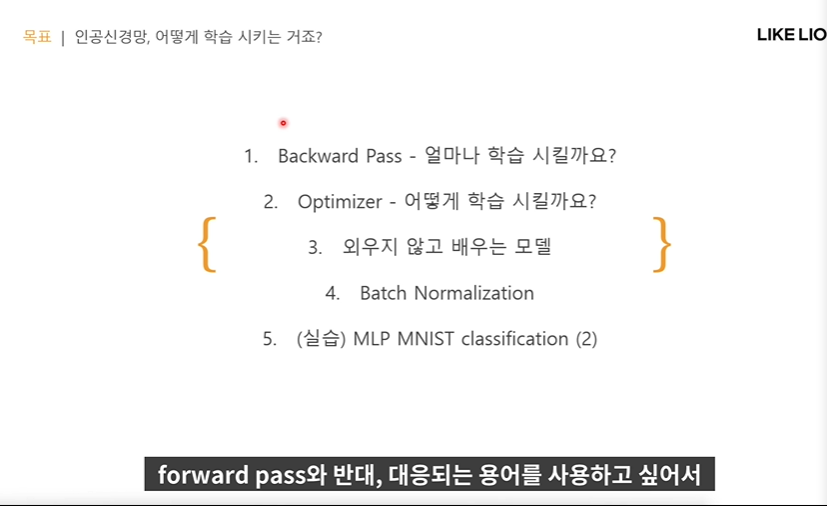
- 외우기 않고 배우는 모델 - training 데이터를 외우기만 하는 모델이 만들어질 수 있다.(overfitting) -> regularization 등을 사용한다.
- batch normalization : forward 계산을 진행하면서 각 레이어별로 activation value가 있는데 그 value들의 분포를 조정해주는 기법이다. 학습의 안정도와 속도를 키워주는 기법.
loss function의 gradient를 이용해 parameter(weight, bias) 값을 업데이트 하는 것. w=w-lr * L을 w로 미분한값

편미분 w1,w2,w3,w4...
다변수 함수의 경우에는 각각의 성분이 편도함수가 됨.. x1,x2,x3에 따라 변화량이 각각 다르기 때문에

Chain Rule
- forward 과정은 각각의 layer를 블록으로 봤을 때 합성함수가 된다.
- u가 또 g의 함수이다.. 그럼 일단 u에 대한 변화를 보고, 그 u가 x에 대해 어떻게 변화하는지 본다.

Chain Rule for MLP
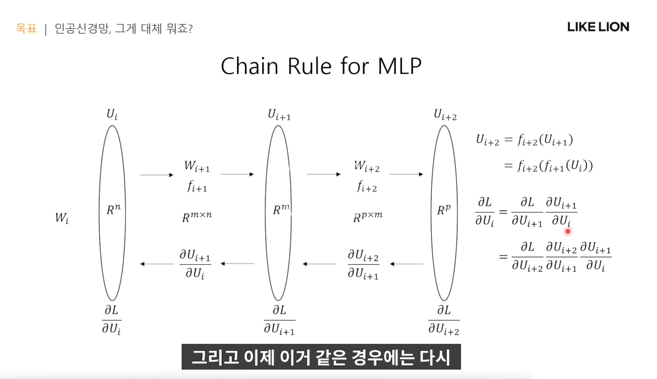
Basic Operation - MLP에서의 연산은 행렬곱과 activation function으로 구성되어있어서
아래 연산들을 수행함.

1. 더하기 - backward pass는 미분했을 때 저 아래 식처럼 chain rule을 써도 간단하게 표현됨. 그래서 두 갈래로 뻗어나간다~

2. 곱하기
- back ward 방향에서 우리가 알고있는 것은 L/z이고 (델타생략) 궁금한 것은 L/u와 L/v값이다.
따라서 chain rule로 계산해보면 아래처럼 나온다.

3. common variable
- x라는 값 하나가 여러 갈래로 퍼져나갈때 ,

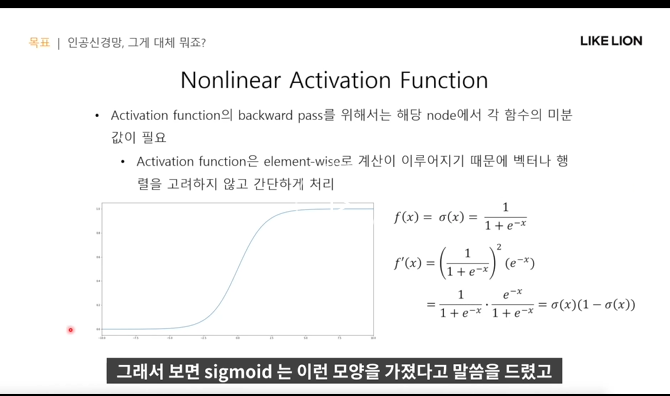
4. non linear activation function
- pytorch에서 tensor는 단순히 numpy array처럼 값만 가진 게 아니고 backward pass에 필요한 것들을 저장해놓는다.
- f(u)가 activation function이라고 한다면 모델 학습을 위한 파라미터를 알려면 f'(u)가 필요하다

Activation Function-sigmoid 미분
- sigmioid는 미분계산이 쉬우나 기울기소실문제가 있다(기울기가 0애 가깝게 너무 작아서.. gradient가 전달이 안 된다. 깊은 모델을 학습시키기 힘들다.)
Activation Function - ReLU 미분

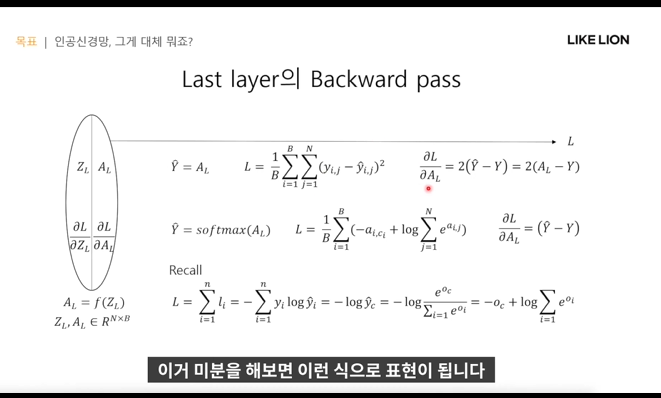
last layer에서 backward pass
- 확률 분포를 output으로 내는 게 좋기 때문에 마지막에 softmax를 사용함
- n개의 feature에 대해 loss를 구해야 함. (3번째 줄 Recall 식)
- yi는 true label에만 1이다(one hot encoding되어있어서) 그래서 -logyc만 남고, yc는 activation function에 넣으니 우변처럼 처리가 됨.
Layer 사이의 Backward pass

Optimizer - Gradient Descent
- closed form sol이 아닌 loss 를 통한 테스크 해결

2차 미분?
- gradient는 1차 미분이라 일단 감소하는 방향으로 가보겠다 이건데
얘는 파라미터 공간에서 2차 함수로 minimum을 찾게 됨?
- 훨씬 빠르고, 확신을 가지고 파라미터를 업데이트 할 수 있다.
- Heisian : 파라미터 x 파라미터의 dimension을 가지는 행렬

Parameter Space
- 실제 딥러닝 모델의 파라미터는 매우 많다.. 진짜 global optimal을 찾기는 불가능(진짜 최소라고 확신도 못함)
적당히 local minimum을 찾으면 걔는 꽤 괜찮은 솔루션일거다.
- 그래도 계속 minimum을 계속 찾아야 하는 이유는 saddle point 때문이다.
- saddle point : 한쪽차원으로는 감소하고 한쪽 차원으로는 증가할 수 있는 점
- local minimum일때 접선의 기울기값=0

Gradient Based Method

SGD Stochastic Gradient Descent
- 단점: local minimum과 saddel point에 빠지기 쉽고, lr에 따라 진동하기가 쉽다.

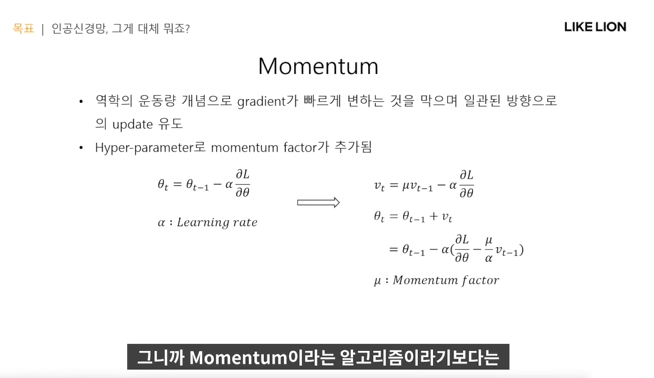
Momentum : SGD 문제점 개선을 위한
- vt 도입. 이전 방향과 지금 새로 가려는 방향을 가중치를 줘서 도입?
- theta를 가지고 velocity를 구하고 그걸로 파라미터 업데이트
Nesterov Momentum
- velocity 방향으로 파라미터를 한번 업데이트 하고 거기서 gradient를 구하는 것.


AdaGrad
- 위까지는 모든 파라미터에 동일한 lr 적용했으나, AdaGrad는 각각 파라미터별로 한 파라미터가 너무 많이 업데이트되면 다른 파라미터들을 더 업데이트해주는 것.
- 땡2 표현은 element wise하게 제곱. St 는 accumulation이다.
- 단점 : S가 단조증가한다, 즉 효과를 보는 파라미터 업데이트의 lr이 계속 감소하기만 한다.

RMSProp
- 왼쪽 식에서 오른쪽 식으로 AdaGrad를 조금 개선.
- 현업에서 많이 사용됨.

Adam
- 제일 많이 사용됨.
- RMSProp + momentum. 보통 B(베타)가 크다. 이전 가던 방향으로 주로 간다.. 그런데 그렇게 되면 너무 느리게 바뀌어서
mt, St라는 것도 사용한다.

Learning Rate Scheduling
- 보통 처음에는 보폭을 크게, 나중에는 조금씩 하는 게 좋음(lr 설정)
- 그래서 lr을 스케줄링하는데, linear decay는 ReLU함수를 뒤집은것처럼 처음엔 좀 크게하다가 나중에 작게하는것,
step decay는 계단형식으로 몇 epoch갈때마다 계단처럼 줄이는 것 등등이 있다.
- 초기 lr값, lr 스케줄링 방법 등 다 하이퍼파라미터이다.

파라미터 초기화

Regularization - 모델이 더 일반화가 잘 되게, overfitting 방지
- 중요하지 않은 걸 학습하는 것을 막는다. training데이터에 대한 단순암기를 막는..
- Norm regularization, early stop, 앙상블, dropout, label smoothing, 데이터증강 등등

Norm Regularization
- L1 norm : 모든 파라미터의 절대값의 합을 계산해서 그것까지 loss에 추가

Early Stopping
- overfitting 되기 전에 학습을 멈춘다.

Ensemble
- 딥러닝 모델은 하이퍼파라미터도 달라지고 각자 randomness가 포함되기때문에 모두 다른 모델이 됨. 따라서 같은 데이터로 학습을 진행해도 모두 다른 모델이 학습되어 averaging 이 일반화에 도움을 준다.

Dropout
- 모든 파라미터(전체 노드)를 다 사용하는 게 아니라 일부를 마스킹해서 사용하지 않는다.
- 요즘은 batch normalization이 dropout의 효과를 다루고 있기에 잘 안쓰기도 한다.(training할 때 / test할 때는 모든 노드를 사용?한다)
- 즉 특정 feature를 학습하지 않는다.
- 앙상블 효과를 내기도 한다.

Batch Normalization
- 각각의 feature별로 값들을 normalization해줘서 원하는 분포로 만들어 주는 것이다.
- 먼저 activation value들의 분포에 대해 일반적으로 가정을 많이 한다. (모델에 있는 사실상 모든 값은 가우시안 분포를 따름 - 대부분 평균 0 근처에)
- 데이터들도 가우시안 분포를 많이 따른다
- 하지만 실제로는 각 feature별로 지들각자의 분포를 가지기 때문에 각 파라미터들이 전혀 다른 분포의 activation에 대응을 해야 해서 학습속도가 느리고 학습 방향이 일정하지 않음
-> 그래서 batch normalization 사용.

Batch Normalization 방법
- 그냥 막연히 각 activation이 가우시안 분포를 따르기를 기대하는 게 아니고 아예 batch 단위로 normalization을 해서 가우시안 분포로 만들어주는 것이다.
- 일반적으로 normalization -> scaling -> activation 을 하는데 activation 전에 하는게 좋은지 후에 하는게 좋은지는 task에 따라 달라진다.
- N : feature dimension / B : batch size
- 각각의 데이터가 column 벡터 형태를 가지게 된다.
- batch normalization : 각각의 feature에 대해 normalization을 구함. 각 feature에 대해 압축을 해서 평균과 분산을 구한다.
-> 저 노란줄 하나가 unit 가우시안 분포를 이루게 된다. 그런데 저기서 끝나는 게 아니라 그 값을 다시 scailing 하고 shifting을 해준다. (scaling : 늘이거나 줄임, shifting : 좌우로 옮김 - 감마,베타 가 그 하이퍼파라미터 = batch statics )
- batch normalization 작업은 노드가 하나 더 추가된다고 생각해도 된다. 그래서 batch normliazation layer라고 부르기도 함.
- RNN이나 LSTM같은 시계열 데이터의 경우에는 batch normalization을 적용할 수는 없다. 그러나 이미지는 대부분 batch normalization을 사용함.

B
- inference을 할 떄는 배치 단위로 추론할 수도 있지만 데이터 샘플 하나 가지고도 추론결과를 낼 수도 있어야 한다.
그래서 test를 할 때는 test batch 에 statics를 적용하는 게 아니라 train 과정에서 batch statics를 누적해두고 test할 떄 그걸 잠깐 가져와서 사용. -> 왜냐, transductive : test할 때 유의점. batch statics를 사용하면 옆에 있는 테스트 데이터들의 분포를 알고 inference를 한다.(컨닝처럼) 이걸 막기 위해

Summary
