2022. 6. 2. 10:54ㆍ카테고리 없음
3주차 복습

목차

Multi Layer Perceptron = MLP
Activation Function = 선형 성질을 가진 모델에 비선형적인 성질을 부여함으로서 표현력이 부족한 선형적 모델로 회귀하지 않게 하는 장치?
Loss Function = 뭘 기준으로 모델을 학습시킬 것인가.
1. Multi Layer Perceptron MLP
Perceptron = 여러 층으로 되어 있음. 학습 알고리즘 중 하나. 선형적인 성질을 가진 학습 알고리즘(w1x1 + w2x2 ..)
input 입력 벡터를 받아서 각각의 dimension에서 가중치를 곱해줘서 더하고, 그 결과물을 가지고 OX 문제를 푸는 알고리즘. 그림에서는 4차원 입력벡터 w1x1 + w2x2 + w3x3+ w4x4 이 결과를 activation function에 넣어서 어느 정도 값이 되면 활성화한다. w1,w2,w3,w4(모델의 파라미터)를 업데이트하게 된다.
그러나 한계가 있음 - 선형적 모델. 입력벡터 내부에 있는 각 요소별 곱이나 복잡한 관계를 표현하기 위해서는 더 심화된 구조가 필요함.
-> 여러 층을 쌓다보면 각 요소간의 관계도 더 잘 나타낼 것이다.

-> Multi Layer Perceptron MLP
퍼셉트론을 여러 개 쌓아서 더 복잡한 관계를 해결. input vector는 위와 같이 4차원으로 놓고, weighted sum을 하는 게 node의 역할이다. 저 보라색 하나가 위에서 본 single layer perceptron 하나이다. 즉 아래 구조에서 hidden layer속에 있는 perceptron은 5개? 다른 linear 모델이 풀 수 없는 문제를 풀 수 있따. (ex XOR Gate)
-> 그러나 parameter 수가 너무 많아진다. 딥러닝이 각광받으면서 얘도 뜨고 있다.

Logic Gate
AND는 single layer perceptron으로 풀 수 있다(점을 나누는 선= 구분자를 구함) , input의 차원은 2
그러나 XOR는 구분자를 얻기가 어려워서 y=w1x1 + w2x2 + b로는 힘듬.


MLP의 여러가지 이름 MLP = Multi Layer Perceptron = 인공신경망 = Fully Connected Neural Network = Affine Network = Feed Forward Neural Network FFNN
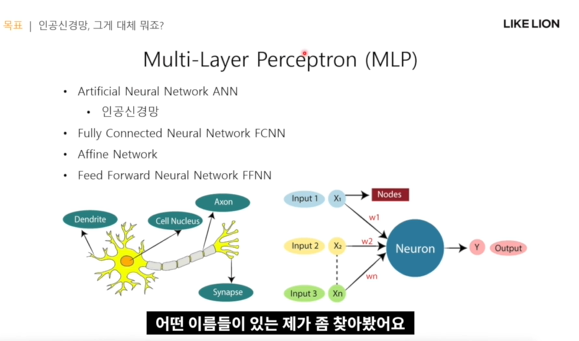
MLP의 구조
input layer, hidden layer, output layer 가 있음. hidden layer는 그림에서 1개이고, output layer의 output도 그림에선 퍼셉트론 구조를 따와서 1개인데, 벡터형태(여러개)일 수도 있다. 저 화살표?연결선이 weight임. 이 그림에서는 4x5=20 개의 weight가 있다.
- 파라미터(가중치, 바이어스)
- activation function = 비선형성을주며 좀더 풍부한 표현을 가능하게
- loss function = 현재 파라미터가 얼마나 좋은지 평가, 업데이트

MLP의 작동 원리
어떤 input을 받았을 때 파라미터를 가지고 출력을 함수의 형태로 내는 것을 의미한다. 그래서 실제 true label을 추론함
그렇게 해주는 특이한 함수를 구현한다.
forward 로 얻은 출력값과, 정답-출력값으로 loss function을 얻고 그것과 back propagation을 통해 각각의 모든 파라미터를 업데이트해가며 모델을 더 잘 맞히도록 학습시켜간다.

딥러닝
MLP 자체는 일찍 등장했었는데 계산 자원이 부족해서 주목받지 못함.

그러다가 하드웨어가 발전하면서 점점 부상을 하기 시작함.(GPU, TPU 클라우드 컴퓨팅)
- initialization : 모델 파라미터의 초기값
- regularization : 실제 테스트 데이터에 대한 성능을 높이는 것
-> 파라미터수가 많은, 표현력이 높은 모델을 개발할 수 있게 됨.

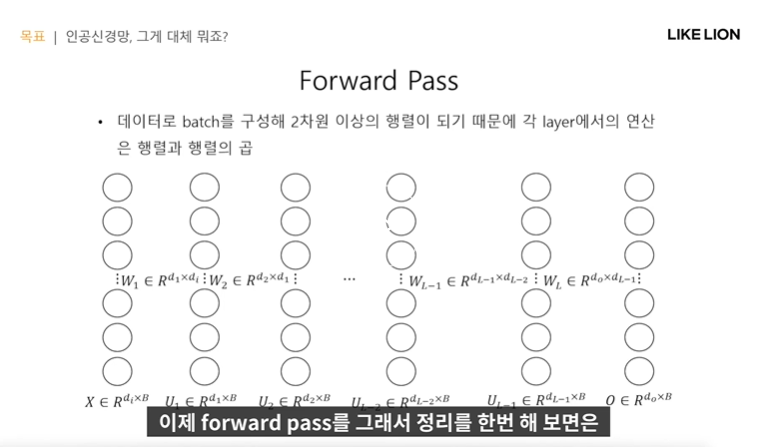
Forward Pass

- single layer perceptron 이 multi layer perceptron(MLP)가 되기 위해 어떤 과정이 필요했냐면
원래는 노드 하나를 향해 전부 다 화살표를 쏘았는데 이젠 층이 많기때문에 단순 하나의 노드에 쏘는 게 아니라 모든 노드에 다 쏜다.
-> weight이 w31, w32 등등 이렇게 인덱싱을 한다.
- 입력벡터 x는 5차원(x1,x2,x3,x4,x5)로 가정, 총 wT는 4X5가 될듯

Batch Training
- batch : 데이터셋을 학습할 때 하나의 벡터만 사용하는 게 아닌, 여러 개를 묶어서 하는 것.
왜냐면, 행렬곱을 많이 사용하는데 선형변환, 선형연산이기때문에 이렇게 해도 상관없다.
또한 GPU로 행렬연산이 빨라서
- 또한, 속도가 그렇게 차이가 나는 게 아니라면 여러 개의 데이터로 얻은 signal을 가지고 학습을 진행하면 훨씬 보편적으로 update를 할 수 있을 것이다. 그렇게 되면 학습데이터가 아닌 다른 데이터에 대해서도 더 나은 성능을 얻을 수 있을 것.
그래서 데이터를 묶어서 학습한다.
이 때 묶은 데이터 묶음 -> batch
- parameter, weight는 행렬 / 데이터는 벡터(한개씩 학습) -> 행렬(batch 단위로 학습)로 확장
-> 모델의 학습은 행렬과 행렬의 곱이 된다. 실제 backpropagation에서도 행렬 행렬곱 형태로 진행됨.

Matrix Multiplication
- 2차원 행렬의 곱. GPU 가속화가 편리함.
예시 A nxm X B mxp하면 C nxp 가 됨.

Batch Training
- 왼쪽 식 : 데이터가 (x)가 벡터일 때(batch로 묶지 않았을 때) -> 오른쪽식 : 데이터가 행렬일 때
- bias 는? 빼도 되는건가? 뺴도 되는 근거가 있다. x가 의미있는 dimension만 가지고 있었는데 하나의 dimension을 더 추가해서 거기에 값을 1을 넣고, 노드에 연결되어 있는 parameter에 bias로 넣어준다.
-> 즉 x의 dimension을 하나 증가시키고 그 요소들에 1을 넣어서 bias를 없애도 행렬로 깔끔하게 개선되게끔 표현.
즉 bias를 더한 형태가 아닌 곱한 형태로 표현을 함.

Mini Batch Training
데이터가 많아서 batch training을 하는 건 좋다. 근데 실제로 데이터 수가 굉장히 많아지면 그걸 전부 메모리에 올려 연산을 하는 건 힘들다. 즉, 1개씩 학습하는 건 너무 비효율적이고, 그렇다고 전부 묶어서 연산을 할 순 없다.
데이터셋을 전부 다 넣으면 생기는 문제 - Overfitting (학습데이터에만 너무 fitting됨) / 메모리 부족 문제.
Mini batch training
- batch 전체 데이터를 또 나눈다. 그 묶음을 mini batch라고 한다. 근데 묶을 때 랜덤하게 샘플링하여 묶는다.(그래야 Overfitting을 해결.. 모델한테 혼동을 준다 -> 학습데이터에 대해 암기만 한 모델보다 더 어려운 문제를 잘 찍게 됨.)
- Mini batch training의 진행방식
전체 데이터셋을 한번 학습하는 것 : 1 epoch. 총 학습과정은 여러 epoch을 진행하게 됨.
1 epoch 안에서 여러 mini batch를 도는 것. 1 epoch안에 몇 번의 batch를 샘플링하느냐?
- 실제 업데이트 횟수: 전체 dataset size / batch size(=mini batch size) = 1 epoch당 업데이트를 하는 횟수.

Forward Pass
- WX 즉 행렬과 행렬의 곱으로 표현됨.
- 노드보다는 그 사이 공간이 parameter를 의미한다.
- 보통 모델의 layer가 몇 층이냐 할 때는 input , output layer를 빼고 hidden layer 개수로만 표현.
Activtaion Function이 왜 필요한가
- MLP에서 각 layer의 연산은 행렬 곱으로 표현이 되는데, 각각 연산이 선형 연산이다.
행렬의 곱 결과도 행렬이기 때문에 여러 layer를 겹치는 게 의미가 없어진다.
- 예를 들어 weight개수가 L개인(L 층인) 모델에서 W가 weight, U가 직전 레이어에서 온 input임.
UL-1 = WL-1 UL-2 로 recursive하게 표현됨. activation function을 넣지 않으면 이걸 계속해서 표현하게 됨.
근데 O = WX로 표현하는 건 single layer perceptron 가지고도 표현할 수 있다. 그러면 왜 굳이 여러개 layer를 겹쳐서 MLP로 표현할 이유가 없음.
-> 중간에 비선형 함수를 넣어줘서 전체 모델이 가지는 선형성을 없애주고, 선형모델보다 더 표현력이 늘어나게 된다.
-> f(WX) 로 비선형함수인 activation function f 안에 weight과 데이터를 곱한 행렬을 넣어준다. ( 그림에서는 a(WU))

어떤 Activation Function이 좋은가
- 활성화함수는 비선형성질을 갖고 있으면 어떤 함수라도 사용 가능함.
그러나 딥러닝 모델의 학습에 유용한 특징이 있음.
- 활성화함수는 MLP의 forward pass 연산을 할 때 많이 사용됨. back propagation을 할 때도 activation function이 있기 때문에 미분계수에 대한 처리를 해줘야함. 또한 데이터분포에 잘 맞는 activation function을 사용해야함.
데이터 분포에 잘 맞는다는 것은 데이터 X와 W를 곱하고 활성화함수를 적용했을 때 non linearity를 가지고 있어야 한다.
- 가장 범용적으로 쓰이는 4개 activation function의 예시를 들어놨다. 이 중에서 ReLU가 제일 핫함.

Sigmoid 함수
- 0~1사이 값
- 장점 : 1/1+e^-x 의 미분계수가 매우 쉽게 얻어지고, 그 미분계수 자체가 다시 원함수가 됨.
- back propagation : 미분계수를 구해서 전달을 해주는 것임.
딥러닝 모델은 층이 여러개 있으므로 각각의 도함수를 곱하는 형태가 된다.
- 단점 : input의 절대값이 조금만 커도 금방 상수함수처럼 saturate, 즉 접선의기울기가 0이 됨.
0이 되는 게 하나라도 곱해지면 error signal이 잘 전달되지 않음. -> vanishing gradient 문제 발생
- 요즘에는 거의 사용하지 않음.

tanh
- -1~1까지의 값을 가짐. sigmoid를 좌우로 2배 줄이고 위아래로 2배 늘린 형태랑 비슷함.
그러나 얘도 역시 nonlinearity한 부분이 적음. .. sigmoid의 단점을 그대로 가지고 있음. gradient vanishing 문제

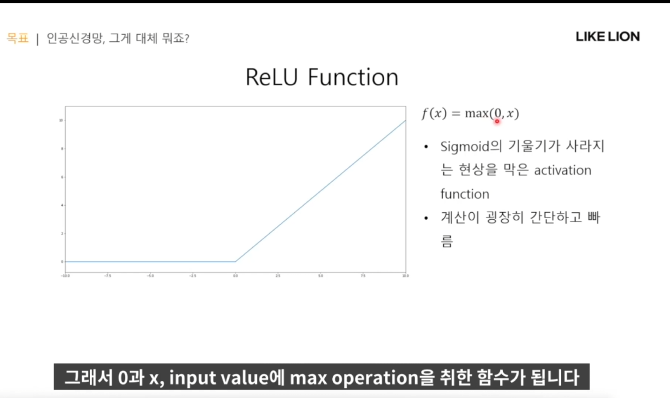
ReLU
- x가 양수면 x그대로 나오고, x가 음수면 0이 나옴.
- 장점 : x가 0만 넘으면 gradient가 1로, back propagation이 잘 전달되고, 계산속도가 빠르다.
- 그러나, 음수인 x를 다 0 으로 지워버린 건 아예 데이터 절반을 날리는 것이니 아까움.
Leaky ReLU
- ReLU보다는 덜 쓴다. 왜냐면 알파 값도 사람이 설정해줘야하는 하이퍼파라미터가 또 늘어서 힘들다.

Softmax Function
- 모델의 output을 확률 분포의 형태로 만들어줌. 모든 값들을 다 더했을 때 1이 나오도록(확률값 합은 1)
- classify 문제에서는 거의 국룰로 softmax를 사용한다. 이 클래스에 속할 확률이 ~~이다.

Loss Function
- 모델 output (predict)가 실제 정답(true label)에 대해 얼마나 틀렸는지를 나타내는 척도로 이용.
- 강화학습은 loss가 아니라 reward 로 한다. 일반적인 supervised learning에서는 loss를 낮추는 방향으로 학습을 진행함.
- regression에서는 주로 MSE를, classification에서는 cross entropy를 사용한다.
- loss를 미분해서 gradient descent 방법으로 loss가 제일 낮은 w를 찾아간다.

MSE Loss
- predict값과 true label 사이의 L2 norm을 계산하여 loss로 사용.
- 2차함수의 형태이기 때문에 loss가 큰 데이터들의 loss를 줄여서 loss가 작은 데이터와 비슷한 loss를 가지게 될 때까지 학습을 한다?

Cross Entropy Loss
모델의 output을 class label 에 대한 확률분포로 가정한다. 각 label에 해당될 확률을 받아서 loss를 측정
osftmax를 거치면 output이 확률 형태로 나오고 그걸 cross entropy에 바로 넣을 수 있다.
엔트로피 : 확률 x 로그 확률의 곱
크로스 엔트로피 : true 정답 x 모델이 맞춘 로그 확률

Summary
