2022. 5. 23. 16:17ㆍ카테고리 없음
0. Abstract
비지도 및 지도(반지도) 학습의 조합은 레이블이 지정된 훈련 데이터의 양이 감소하더라도 높은 RUL 예측 정확도를 제공할 가능성이 있습니다. 이 논문은 반 지도 설정을 사용하는 RUL 예측에서 지도되지 않은 사전 훈련의 효과를 조사합니다. 추가적으로, 훈련 절차에서 다양한 양의 하이퍼 매개변수를 조정하기 위해 GA(Genetic Algorithm) 접근 방식이 적용됩니다.
CNN(Convolutional Neural Network ) 및 LSTM(Long-Short Term Memory)와 같은 DL 기술 은 터보팬 엔진 성능 저하 에 대한 RUL 예측에서 빠른 발전과 기존 예후 알고리즘을 능가하는 성능을 보였습니다
그러나 CNN과 LSTM은 모두 순전히 지도 학습에 의존합니다. 즉, 훈련 절차에서 레이블이 지정된 큰 훈련 데이터 세트가 필요합니다. 따라서 RUL 예측 정확도는 구성된 run-to-failure 훈련 데이터 레이블의 품질에 크게 의존합니다.
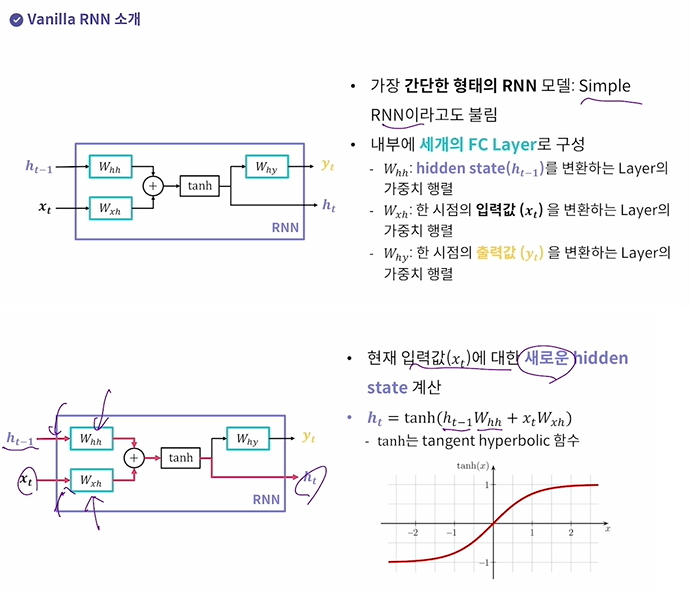
RNN : CNN이 이미지 데이터 처리할 때 좋듯, 순차(시계열) 데이터 처리할 때 쓰는 딥러닝 모델
RNN의 Recurrent 인 이유 : 이전 시점에 생성된 hidden state를 다음 시점에도 사용하기 때문이다.
Hidden state의 의미:
- 특정 시점 t까지 들어온 입력값들의 상관관계나 경향성을 저장한다.
- 모델이 내부적으로 계속 가지는 값이므로 일종의 메모리라고 생각할 수 있다.
RUL 예측 시 RNN이 좋은 이유(Recurrent Neural Networks for Remaining Useful Life Estimation 논문)
RNN은 시스템이 언제 고장나기 시작하는지 감지할 수 있고 과거 상태 정보의 피드백을 제공함으로써 고장에 대한 일관된 응답을 학습할 수 있다.
비선형 시간 영역 동적 시스템 모델링을 처리하는 더 나은 접근법은 순환 신경망을 사용하는 것이다. RNN 네트워크는 내부 메모리와 피드백을 활용하고 복잡한 비선형 동적 매핑을 학습할 수 있다. 반복 신경망은 이전 입력과 숨겨진 상태의 임의의 수를 설명할 수 있으며 강력한 숨겨진 상태를 학습할 수 있다.
하지만 RNN의 문제점
- RNN은 출력값이 시간 순서에 따라 생성
- 각 시점의 출력-실제를 뺴서 loss(손실)을 구함.
- 그 다음 시간에 따라 back propagation 을 진행

이런 과정으로 학습을 하는데
- 만약 입력값의 길이가 매우 길어지면

기울기 소실 문제가 발생(Vanishing Gradient)
- 엄청 긴 문장(장기 의존성 = Long term Dependency)를 다루기가 어렵다.
(엄청 긴 문장의 맨 처음단어와 맨 마지막단어의 의존)
LSTM : (Semi-supervised 논문)순차 데이터를 처리하는 잘 정립된 DL 기술입니다. 원래 LSTM 전통적인 RNN( Recurrent Neural Networks) 에서 사라지고 폭발하는 기울기 문제를 발견한 1990년대 초 이후에 개발되었습니다. 기존 RNN이 장기 종속성을 학습하는 데 어려움이 있음을 확인했습니다. 이러한 문제를 해결하기 위해 LSTM은 셀 안팎의 정보 흐름을 조절하는 메모리 셀을 도입했습니다. 결과적으로 메모리 셀은 장기간에 걸쳐 상태를 유지할 수 있습니다.
LSTM( Long Short Term Memory ) - RNN 모델
- Vanilla RNN의 기울기 소실 문제를 해결하고자 등장.
- 장기 의존성과 단기 의존성을 모두 기억할 수 있다는 뜻이다. Long Short
- 새로 계산된 hidden state를 출력값으로도 사용한다.
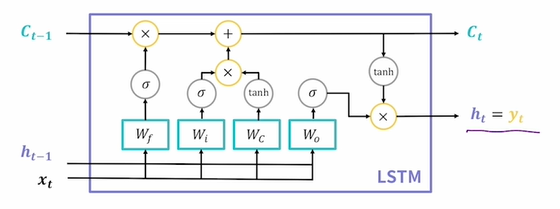
Ct = Cell State ( 기울기 소실 장치를 해결하기 위한. 장기적으로 기억할 정보를 저장한다.
예를 들어 앞 단어와 맨 뒤에 오는 단어가 연관이 있다, 그 다음 문장과는 연관이 없다 등등)
- Wf, Wi, Wc,Wo = Gate (3종류의 게이트를 4개의 FC Layer Wf, Wi, Wc, Wo가 구성한다.)

semi supervised에서 제안된 deep architecture는 그림2와 같다. 첫 번째 계층(L1)에서 RBM은 레이블이 지정되지 않은 원시 입력 데이터에서 추상적인 기능을 자동으로 학습하기 위해 감독되지 않은 사전 훈련 단계로 활용됩니다. 이러한 기능에는 중요한 성능 저하 정보가 포함될 수 있으므로 전체 아키텍처의 감독된 미세 조정이 수행되기 전에 좋은 로컬 최소값에 가까운 영역에서 가중치를 초기화합니다. 두 번째 및 세 번째 레이어(L2 및 L3) 모두에서 LSTM 레이어는 숨겨진 정보를 드러내고 여러 작동 및 오류 조건이 있는 순차적 데이터의 장기 종속성을 학습하는 데 사용됩니다 [6] . 다음으로 FNN레이어는 추출된 모든 특징을 매핑하기 위해 네 번째 레이어(L4)에서 사용됩니다. 마지막 계층(L5)에서 시간 분포 완전 연결 출력 계층은 오류 계산을 처리하고 RUL 예측을 수행하기 위해 연결됩니다.
GA(Genetic Algorithm) 접근방식 : 하이퍼 파라미터를 조정하기 위해
첫째, GA 접근 방식은 주어진 검색 공간 내에서 제안된 준지도 심층 아키텍처에 대한 임의의 하이퍼 매개변수를 선택합니다. 이러한 임의의 하이퍼 매개변수 집합 중 하나를 개인이라고 하고 개인 집합을 모집단이라고 합니다. 다음으로, 모집단의 각 개인의 정확도는 개인의 하이퍼 매개변수를 사용하여 네트워크를 훈련하여 평가됩니다. 그런 다음 훈련의 최상의 결과가 유지되어 차세대 하이퍼 매개 변수의 부모로 사용됩니다.

CNN : (stacked DCNN)
CNN이 좋은 이유는 특징 추출에 좋다. [14,15,16]
RNN이 좋은 이유는 데이터의 시간적 특성을 모델링하기에 양방향에서 쉽게 찾을 수 있다.[17,18,19]
그래서 이 둘을 함께 사용하기도 한다. [20,21,22]
FNN : (semi supervised) Feed-forward Neural Network(그냥 기본적은 NN인듯?)
AR : https://zephyrus1111.tistory.com/102
AR(AutoRegression)(자기 회귀) 모델은 이전 관측 값이 이후 관측 값에 영향을 준다는 아이디어에 대한 모형으로 자기 회귀 모델이라고도 합니다. AR에 대한 수식은 다음과 같습니다.

①은 시계열 데이터에서 현재 시점을 의미하며, ②는 과거가 현재에 미치는 영향을 나타내는 모수(Φ)에 시계열 데이터의 과거 시점을 곱한 것입니다. 마지막으로 ③은 시계열 분석에서 오차 항을 의미하며 백색 잡음이라고도 합니다. 따라서 수식은 p 시점을 기준으로 그 이전의 데이터에 의해 현재 시점의 데이터가 영향을 받는 모형이라고 할 수 있습니다.