2022. 5. 7. 11:48ㆍ카테고리 없음
piece-wise functionhttps://www.sciencedirect.com/science/article/pii/S0951832022000321
Variational encoding approach for interpretable assessment of remaining useful life estimation
A new method for evaluating aircraft engine monitoring data is proposed. Commonly, prognostics and health management systems use knowledge of the degr…
www.sciencedirect.com
Variational encoding approach for interpretable assessment of remaining useful life estimation
(잔여 수명 추정의 해석 가능한 평가를 위한 변형 인코딩 접근 방식)
논문
https://www.sciencedirect.com/science/article/pii/S0951832022000321#b18
Variational encoding approach for interpretable assessment of remaining useful life estimation
A new method for evaluating aircraft engine monitoring data is proposed. Commonly, prognostics and health management systems use knowledge of the degr…
www.sciencedirect.com
하이라이트
- A novel encoder model based on variational inference is proposed for RUL estimation.
RUL 추정을 위해 변이 추론을 기반으로 하는 새로운 인코더 모델이 제안됩니다.
- An explainable diagnosis is achieved based on the learned latent features.
학습된 잠재 기능을 기반으로 설명 가능한 진단이 달성됩니다.
- Regularization of training results in a continuous trajectory of engine degradation in the latent space.
훈련의 정규화는 잠재 공간에서 엔진 성능 저하의 지속적인 궤적을 초래합니다.
- Our method outperforms state-of-the-art approaches on the C-MAPSS dataset.
우리의 방법은 C-MAPSS 데이터 세트에 대한 최첨단 접근 방식을 능가합니다.
- The method is also evaluated on a real-world problem with actual engines.
이 방법은 실제 엔진의 실제 문제에 대해서도 평가됩니다.
잠깐, 잠재공간(latent space)와 차원 축소 가 무엇이냐?
https://dev-hani.tistory.com/entry/Latent-space-%EA%B0%84%EB%8B%A8-%EC%A0%95%EB%A6%AC
Latent space 간단 정리
Feature가 필요한 이유? 머신 러닝은 input data를 output data로 대응시키는 블랙박스 형태입니다. 이 블랙박스는 input data의 함수이며 선형 또는 비선형의 형태를 가질 수 있습니다. 우리는 train data
dev-hani.tistory.com
우리가 훈련에 필요한 충분한 고차원의 입력 값을 가지고 있다고 가정해 봅시다. 모든 개수의 fearture가 필요하지 않을 수도 있고, 가지고 있는 feature들 중 몇몇 개는 다른 특징들의 조합으로 표현 가능하므로 불필요 할 수도 있습니다. 따라서 관찰 대상들을 잘 설명할 수 있는 잠재 공간(latent space)은 실제 관찰 공간(observation space)보다 작을 수 있습니다. 이렇게 관찰 공간 위의 샘플 기반으로 잠재 공간을 파악하는 것을 차원 축소(dimensionality reduction technique)라고 합니다.
차원 축소는 데이터의 압축, 잡음 제거 효과가 있지만,
가장 중요한 의의는 관측 데이터를 잘 설명할 수 있는 잠재 공간(latent space)를 찾는 것입니다.
실제 Turbofan 엔진에 대한 정보
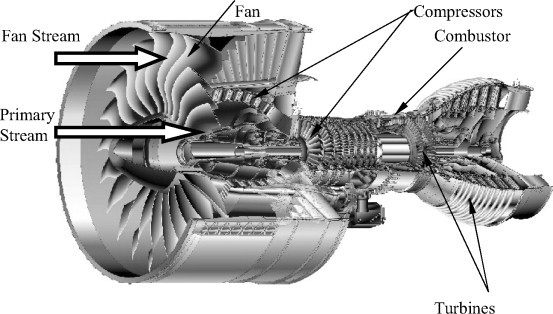
https://www.sciencedirect.com/topics/engineering/turbofan-engines
Turbofan Engines - an overview | ScienceDirect Topics
The compressor fan of a modern turbofan engine provides a good example of the application of the interaction tone and broadband noise mechanisms in a multiblade row propulsor application. Since the late 1990s NASA has invested in multiple physical scale mo
www.sciencedirect.com
Abstract
대부분은 모델 학습 및/또는 데이터의 특성을 이해하기 위한 설명 구성 요소가 부족합니다. 이 격차를 극복하기 위해 우리는 변형 인코딩을 기반으로 하는 새로운 접근 방식을 제안합니다. 모델은 반복적(recurrent) 으로 구성됩니다.
The model consists of a recurrent encoder and regression model: the encoder learns to compress the input data to a latent space that serves as a basis to build a self-explanatory map that can visually evaluate the rate of deterioration of aircraft engines.
인코더 및 회귀 모델: 인코더는 항공기 엔진의 열화 속도를 시각적으로 평가할 수 있는 자체 설명 맵(self-explanatory map)을 구축하기 위한 기초 역할을 하는 잠재 공간(latent space)으로 입력 데이터를 압축하는 방법을 학습합니다. 이러한 잠재 공간을 얻는 것은 변이 추론(variational inference)에 의해 안내되는 새로운 cost function와 prediction error에 페널티를 주는 용어에 의해 정규화됩니다. 결과적으로 해석 가능한 평가가 달성될 뿐만 아니라 NASA의 인기 있는 시뮬레이션 데이터 세트 C-MAPSS에 대한 대부분의 최첨단 접근 방식을 능가하는 놀라운 예후 정확도를 얻을 수 있습니다. 또한 실제 Turbofan 엔진 의 데이터를 사용하여 실제 시나리오에서 방법을 적용하는 방법을 보여줍니다.
특히 머신러닝 모델의 사용은 사전 예후 경험이 거의 없는 고도로 비선형, 복잡하고 다차원적인 시스템을 모델링할 수 있다는 점에서 큰 영향을 미쳤습니다. RUL 추정에 초점을 맞추면 초기 작업은 [6] 에서와 같이 MLP(다층 퍼셉트론 ) 의 적용을 지향했으며 , 여기서 저자는 모델 기반 접근 방식보다 더 높은 예측 결과를 보고했습니다. [7] , [8] 에서는 PCA 및 은닉 Markov 모델을 사용하여 진단과 예후 모두에 접근했습니다. 수년에 걸쳐 다른 기술도 탐구되었습니다. 일부 연구원은 EHM(Engine Health Monitoring)에 대한 더 많은 정보를 캡처하기 위해 퍼지 로직을 통합했습니다. [9] , [10], 다른 사람들은 지원 벡터 [11] 또는 그라디언트 부스팅 트리 [12] 를 적용 했습니다. 그럼에도 불구하고, 그들 모두가 RUL 추정을 위한 관련 작업으로 간주되었음에도 불구하고 의심할 여지 없이 딥 러닝 모델의 사용으로 더 큰 영향이 발생했습니다 [13] . 이는 머신 health 상태 모니터링에서 얻은 raw 데이터가 높은 차원(high dimensionality)을 공유한다는 사실 때문입니다. 이러한 모델은 특히 Computer Vision 및 Natural Language 에서 상당한 영향을 미치고 매우 잘 수행되는 것으로 알려진 다른 문제와 유사합니다. 처리 (NLP).
-> 정리하자면 RUL 예측은 모델 기반 예측(복잡한 비선형 함수를 먼저 잡고 가는 것. Markov 모델 등등)보다 데이터 기반 예측(머신러닝)이 더 좋다. 왜냐하면 기계의 센서 데이터는 차원이 높기 때문이다.
RUL 예측은 CNN(Convolutional NN)이나 RNN(Recurrent NN)를 사용하는 게 좋다.
CNN이 좋은 이유는 특징 추출에 좋다. [14,15,16]
RNN이 좋은 이유는 데이터의 시간적 특성을 모델링하기에 양방향에서 쉽게 찾을 수 있다.[17,18,19]
그래서 이 둘을 함께 사용하기도 한다. [20,21,22]
또한 데이터 라벨링에 의존하지 않기 위해 semi-supervised 방법이 개발되기도 한다. [23]
또한 데이터마이닝적으로 해결하기도 한다. [24]


그러나 위같은 다양한 딥러닝 모델을 사용한 RUL 연구들은 블랙박스로 처리된다. 즉, 설명력이 부족하여 인간이 봤을 때 의사결정을 하기 쉽지 않은 것이다. ( 위에 언급한 모델들은 대체 왜 이 기계가 고장나는 것이냐? 에 대한 설명이 부족함. 그냥 기계 혼자 예측) , explainality가 부족함.
-> 따라서 의사결정에 대한 인간의 해석 가능성과 데이터의 특성에 대한 통찰력을 제공하는 도구를 제공할 수 있어야 한다.
이 목표를 달성하기 위해 비지도 학습 기술을 이에 접근할 수 있는 가능한 방법으로 생각할 수 있습니다. 특히 데이터의 특성에 대한 통찰력을 드러낼 때 autoencoder 와 같은 Representation Learning 접근 방식 이 유용합니다.
Autoencoder
Autoencoder는 입력 데이터의 압축된 표현 = 잠재 공간을 학습하면서 입력 데이터를 재구성하도록 설계된 모델입니다.
The most common case that in which the probability distribution of non-anomalous data is learned in order to detect, through reconstruction errors, patterns that do not correspond to that distribution
그들의 응용은 비정상 데이터의 확률 분포가 재구성 오류를 통해 해당 분포와 일치하지 않는 패턴을 탐지하기 위해 학습되는 가장 일반적인 경우인 이상 진단에 매우 광범위합니다.
그러나 주요 한계는 PCA [31] , [32] 와 같은 다른 차원 축소 방법과 달리 , 입력 패턴 사이의 상대 거리가 인코더의 투영에서 반드시 보존되는 것은 아니므로 이 클러스터 분석이 항상 가능한 것은 아닙니다. 이 문제는 VAE(Variational Autoencoder)로 해결되었습니다. VAE에서 변형 추론은 Kullback-Leibler 항을 통해 오류 함수에 추가됩니다. 이는 유사한 패턴을 가진 데이터도 잠재 공간 근처에서 인코딩됨을 보장합니다. -> 이상 진단에 많이 쓰이는 기법
그러나 RUL을 결정하는 문제와 비슷하기도 하지만 차이점이 있다.
in anomaly diagnosis, the aim is to look for individuals in unlikely areas of the latent space. In RUL prediction, on the contrary, the objective for a complete and interpretable diagnosis should be to project the evolution of the system in the latent space over time in order to know how fast it is moving towards anomalous zones.
이상 진단에서 목표는 잠재 공간의 가능성이 없는 영역에서 개인을 찾는 것입니다. 반대로 RUL 예측에서 완전하고 해석 가능한 진단의 목적은 시스템이 변칙 영역을 향해 얼마나 빨리 이동하는지 알기 위해 시간 경과에 따른 잠재 공간에서 시스템의 진화를 예측하는 것이어야 합니다.

Fig. 1. In a vanilla VAE, training is regularized to prioritize generative purposes. This results in a dispersed latent projection of the system trajectory as in the figure on the left, in which there is no clear evolution between the state of the equipment at the beginning (white dot) and at the end of evaluation (red dot). On the contrary, a projection like the one in the figure on the right is what we are aiming for.
평가 시작(흰색 점)과 평가 종료(빨간색 점)의 장비 상태 사이에 명확한 진화가 없습니다. 반대로 오른쪽 그림과 같은 투영이 우리가 목표로 하는 것입니다.
여기서 RUL 예측에서 VAE라는 기법도 등장하였는데
1. 시스템 수명의 수치적 추정을 진행할 수 없다는 점
2. 궤적 예측의 시간 변화가 올바르게 분리된다는 보장이 없어 그렇게 좋은 방법은 아니라고 한다.(그림1참조)
이 두 번째 단점과 관련하여 실제 사례에서 RUL 추정은 online 과정이라는 것을 유의해야 한다. 각 기계의 RUL은 새 데이터가 수신될 때 지속적으로 업데이트된다.
잠재 공간(latent space)에서 각 시스템의 연속적인 투영은 시간이 지남에 따라 연속적인 궤적(continuous trajectory)을 형성해야 하며, 이는 미래로 추정할 수 있다. -> 이상 감지로는 식별할 수 없는 시간 경과에 따른 지속적인 성능 저하(마모, 효율성 손실) 등을 진단할 수 있다.
-> VAE 대신 우리 논문에서는 순환 변이 인코더를 기반으로 하는 새로운 신경 아키텍처와 training을 정규화하는 새로운 방법을 결합하여 위에서 언급한 두 가지 문제를 해결.
이를 위해 우리는 잠재 공간에서 엔진의 연속적인 상태의 투영(projection)이 연속 궤적을 구성하는 것을 선호하는 두 번째 항과 Kullback-Leibler 항의 연관과 관련된 새로운 비용 함수를 제안합니다. 이 두 번째 항은 나중에 설명하겠지만 시간이 지남에 따라 연속적인 RUL 예측 오류에 페널티를 부여하며, 엔진의 수명을 예측하는 새 네트워크의 능력과 잠재 공간의 품질 모두에 긍정적인 영향을 미칩니다.
따라서, 우리는 시각적, 따라서 설명 가능하고 해석 가능한 진단을 제공하기 위해 적절한 속성을 가진 잠재 공간의 구성으로 인해 Representation Learning 속성을 포기하지 않고 새로운 순환 네트워크 아키텍처(recurrent network)의 사용을 최대한 활용합니다. 이 방법은 먼저 NASA의 인기 있는 C-MAPSS 데이터 세트로 검증된 후 실제 환경에서 테스트되었습니다.
2. 문제 설정
2.1 . RUL 추정
RUL은 잔여 사용 수명(Remaining Useful Life)의 약자이며 예후, 특히 항공기 모니터링에서 널리 사용되는 메트릭입니다 [39] . 일반적 으로 터빈 압력이나 압축기 온도 와 같은 센서 는 엔진에 대한 비행 정보를 수집하는 데 사용됩니다.
여러 엔진에 대한 이 정보가 있으면 새로운 보이지 않는 항공기가 고장나기 전에 잘 작동하는 남은 시간 주기의 수(즉, RUL)를 추정하기 위해 모델을 훈련하기 위한 데이터 세트가 형성될 수 있습니다.
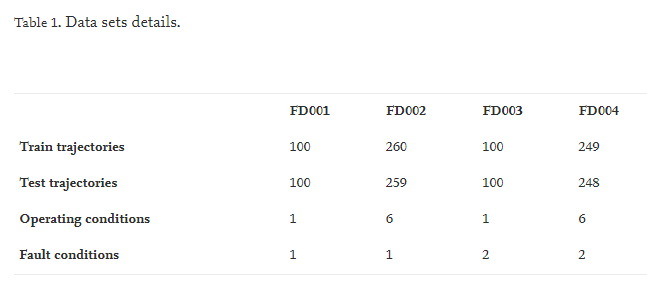
데이터 세트에는 모델 기반 시뮬레이션 프로그램인 C-MAPSS(Commercial Modular Aero-Propulsion System Simulation)에서 생성한 Turbofan 엔진 의 시뮬레이션 데이터가 포함되어 있습니다. 21개의 센서에서 얻은 다변량 시간 데이터로 구성되며 4개의 하위 데이터 세트로 더 나뉩니다. 표 1 에서 볼 수 있듯이, 각 하위 데이터 세트에는 훈련 세트와 테스트 세트가 제공되며 약간의 차이가 있습니다.
The training set comprises run-to-failure data. That is, although each engine unit starts with different degradation states that are unknown, these are considered healthy and as time progresses, the engine units degrade to failure, therefore the last data sample corresponds to the time cycle in which the engine unit is declared unhealthy (RUL = 0).
훈련 세트는 run-to-failure 데이터로 구성됩니다. 즉, 각 엔진 장치는 알 수 없는 서로 다른 성능 저하 상태로 시작하지만 이들은 healthy으로 간주되며 시간이 지남에 따라 엔진 장치는 고장으로 저하되므로 마지막 데이터 샘플은 엔진 장치가 unhealthy(RUL=0)으로 선언된 시간 주기에 해당합니다.
반대로 테스트 세트의 센서 기록은 시스템 오류가 발생하기 전 어느 시점에서 종료되고 이러한 엔진에 대한 실제 RUL 값이 제공됩니다. 이 문제의 목적은 테스트 세트에서 각 엔진의 RUL을 추정하는 것입니다. 특정 하위 데이터 세트에 대한 교육은 작동 및 실패 조건이 다르기 때문에 다른 하위 데이터 세트에 적용되지 않을 수 있다는 점에 유의해야 합니다. 훈련과 테스트 세트 간의 이러한 차이를 피하기 위해 적응 방법을 채택하여 오프라인 훈련 을 피하는 [41] 과 같은 유망한 접근 방식이 있습니다 . 그러나 이것은 이 작업의 범위를 벗어납니다. 4개의 다른 하위 데이터 세트가 있기 때문에 각 훈련 세트에 대해 모델을 훈련하고 정확히 동일한 조건을 가진 테스트 세트에 대해 평가합니다.
2.2 RUL target function
예후 문제에서 시스템은 항상 악화되는 경향이 있으므로 저하 동작을 가정하는 것이 일반적입니다.
3. 모델 구성
1 인코더 네트워크, 2 회귀 모델 및 3 잠재 공간의 세 가지 구성 요소로 구성됩니다. 인코더는 데이터가 속한 확률 분포를 초기화하는 매개변수에 의해 설명되도록 데이터를 잠재 공간으로 압축하는 방법을 학습합니다. 위에서 언급한 매개변수를 학습하기 위해 하나의 확률 분포가 다른 확률 분포에서 얼마나 많이 발산하는지 측정하는 Kullback-Leibler divergence를 통해 손실 함수에 Variational Inference가 추가됩니다. 회귀 모델의 잘못된 추정에 penalty을 주기 위해 두 번째 항도 추가됩니다. 결국 이 모든 것은 유사한 데이터가 다른 작업을 효율적으로 수행할 수 있는 가까운 영역에 있는 잠재 공간을 학습할 수 있도록 합니다.

그림 3 . 제안된 접근 방식을 위한 워크플로: 항공기 데이터가 인코더에 입력되고 인코더는 궤적의 진화를 반영하는 그래픽 맵을 구축하기 위해 열화 패턴을 기반으로 잠재 표현을 학습합니다. Regressor는 이러한 잠재 공간을 얻는 데 직접적인 영향을 미치며 각 엔진의 RUL을 수치적으로 보고할 수 있습니다.
1 결과 인코더는 속성에 따라 데이터를 3 잠재 공간으로 압축하는 feature extractor 역할을 하며, 이는 엔진의 다양한 저하 단계입니다. 잠재 공간은 특히 2차원에서 항공기의 압축된 표현을 포함합니다. 이 표현은 훈련이 완료된 후 엔진의 성능 저하 패턴을 시각적으로 평가하는 데 사용됩니다.
2 마지막으로 수치예측모델(회귀모델)에 공급되는 각 엔진을 가장 잘 나타내는 RUL은 잠재 공간에서 학습된 function으로 회귀 모델을 직접 학습하여 제공됩니다. 이 섹션에서는 모델과 VAE 의 주요 차이점과 인코더 출력을 활용하여 제안하는 시각적 진단을 만드는 방법에 대해 설명합니다. 시계열 을 처리하기 위한 순환아키텍처(Recurrent Network) function이 RUL 추정을 수행하는 방법 에 중점을 둡니다 .
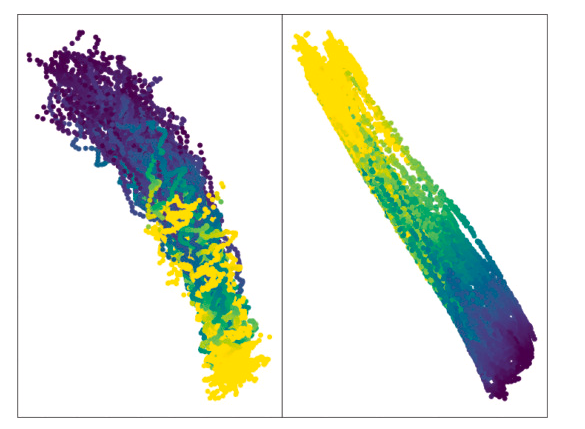
그림 4 . FD001에 대한 인코더가 학습한 잠재 표현. 왼쪽 그림 : VAE 의 정규 훈련 / 오른쪽 그림 : 디코더를 포함하지 않고 잘못된 예측에 대한 패널티를 추가하는 회귀 모델을 포함하는 우리 모델의 결과를 보여줍니다. RUL 값이 높은 항공기는 노란색으로, RUL 값이 낮은 항공기는 짙은 보라색으로 칠해집니다. 열화가 없거나 낮은 이벤트는 맵의 위쪽(높은 RUL 값)에 위치하고 가장 열화된 이벤트는 아래쪽(낮은 RUL 값)
3.1. Variational encoding
Variational encoding(변형 인코딩)은 서론에서 언급한 바와 같이 우리 연구의 핵심 요소인 변형 추론(variance inference)을 기반으로 입력 데이터를 압축하는 프로세스를 말합니다. 이 프로세스는 VAE 작동의 기초이므로 우리 모델과 관련하여 차이점을 명확히 하기 위해 VAE가 작동하는 방식을 아는 것이 중요합니다. VAE에서 훈련 과정은 과적합을 방지하고 잠재 공간이 생성 과정 을 가능하게 하는 필수 속성을 갖도록 정규화됩니다 . 이를 얻기 위해 인코더는 유사한 데이터가 서로 가까이 있는 방식으로 잠재 공간의 데이터를 매핑해야 합니다. 이를 통해 디코더는 데이터를 효율적으로 재구성할 수 있을 뿐만 아니라 훈련 샘플의 인코딩에 해당하지 않는 잠재 공간의 지점에서 새 인스턴스를 생성할 수도 있습니다.
잠깐 Variational AutoEncoder (VAE)란?
https://taeu.github.io/paper/deeplearning-paper-vae/
[논문] VAE(Auto-Encoding Variational Bayes) 직관적 이해
VAE : Variational Auto-Encoder를 직관적으로 이해하기!
taeu.github.io
[1] VAE는 Generative Model이다.
- Generative Model : training data가 주어졌을 때 이 training data가 가지는 real 분포와 같은 분포에서 sampling된 값으로 new data를 생성하는 model을 말한다.
[2] 베이지안 확률(Bayesian probability) : 세상에 반복할 수 없는 혹은 알 수 없는 확률들, 즉 일어나지 않은 일에 대한 확률을 사건과 관련이 있는 여러 확률들을 이용해 우리가 알고싶은 사건을 추정하는 것이 베이지안 확률이다.
- latent : ‘잠재하는’, ‘숨어있는’, ‘hidden’의 뜻을 가진 단어. 여기서 말하는 latent variable z는 특징(feature)를 가진 vector로 이해하면 좋다.
- intractable : 문제를 해결하기 위해 필요한 시간이 문제의 크기에 따라 지수적으로 (exponential) 증가한다면 그 문제는 난해 (intractable) 하다고 한다.
- explicit density model : 샘플링 모델의 구조(분포)를 명확히 정의
- implicit density model : 샘플링 모델의 구조(분포)를 explicit하게 정의하지 않음
[3] density estimation : x라는 데이터만 관찰할 수 있을 때, 관찰할 수 없는 x가 샘플된 확률밀도함수(probability density function)을 estimate하는 것
- Gaussian distribution : 정규분포
- Bernoulli distribution : 베르누이분포
- Marginal Probability : 주변 확률 분포
- D_kl : 쿨백-라이블러 발산(Kullback–Leibler divergence, KLD), 두 확률분포의 차이
- Encode / Decode: 암호화,부호화 / 암호화해제,부호화해제
- likelihood : 가능도. 이에 대한 설명은 꼭 아래 링크에 들어가 읽어보길 바란다.
[4] Autoencoder
- VAE와 오토인코더(AE)는 목적이 전혀 다르다.
- Autoencoder의 목적은 어떤 데이터를 잘 압축하는것, 어떤 데이터의 특징을 잘 뽑는 것, 어떤 데이터의 차원을 잘 줄이는 것이다.
- 반면 VAE의 목적은 Generative model으로 어떤 새로운 X를 만들어내는 것이다.
Likelihood
1. 특정 구간에 속할 확률: 확률밀도함수(Probability Density Function, PDF)
아까의 1에서 6사이의 숫자를 뽑는 상황을 다시 생각해 보자. 1에서 6사이(연속사건)의 숫자 중 정확히 5가 뽑힐 확률은 0지만 4에서 5사이의 숫자가 뽑힐 확률은 20%이다. 전체 구간의 길이는 6-1=5이고 4에서 5사이 구간의 길이는 1이기 때문이다. 마찬가지의 논리로 2에서 4사이의 숫자가 뽑힐 확률은 2/5=40%가 된다. 이처럼 우리는 특정 사건에 대한 확률 대신 특정 구간에 속할 확률을 구함으로서 간접적으로 특정 사건의 확률에 대한 감을 잡을 수 있다. 이것을 설명하는 곡선이 바로 고등학교 때 배운 확률밀도함수(Probability Density Function: PDF)이다. PDF는 특정 구간에 속할 확률을 계산하기 위한 함수이며 함수를 나타내는 <그래프에서 특정 구간에 속한 넓이="특정" 구간에 속할 확률>이 되게끔 정한 함수이다. 아래 그림을 예를 들어 살펴 보자. 왼쪽의 그림에서 PDF의 값은 1에서 6사이에서는 전부 0.2이고 나머지 구간에서는 전부 0인데, 이는 1에서 6사이의 숫자를 뽑는 상황을 그림으로 나타낸 것이다. 1보다 작거나 6보다 큰 숫자를 뽑을 수는 없으므로 이에 해당하는 확률밀도함수의 함수의 y값은 전부 0이고, 1~6사이에서는 무작위로 숫자를 뽑으므로 y값은 전부 같다. 전체 확률은 1이므로 그림의 직사각형의 넓이는 1이되고 y값은 전부 0.2가 되며, 이를 바탕으로 2에서 4사이의 숫자가 뽑힐 확률을 계산하면 2×0.2=0.4로 40%가 된다. 오른쪽의 그림은 정확한 의미는 잘 몰랐더라도 모양은 많이 봤을 정규분포(Normal distribution)이며, 그 중에서도 가장 흔히 쓰이는 평균 0, 분산 1인 표준정규분포(Standard normal distribution)를 나타내고 있다. 표준정규분포의 PDF는 다들 알고 있는대로(?) 12π√e−z2/212πe−z2/2(표준정규분포식)로 표현되며 그림에서 보듯이 z가 -1.96~1.96에 안에 있을 확률이 95%임이 잘 알 려져 있다.
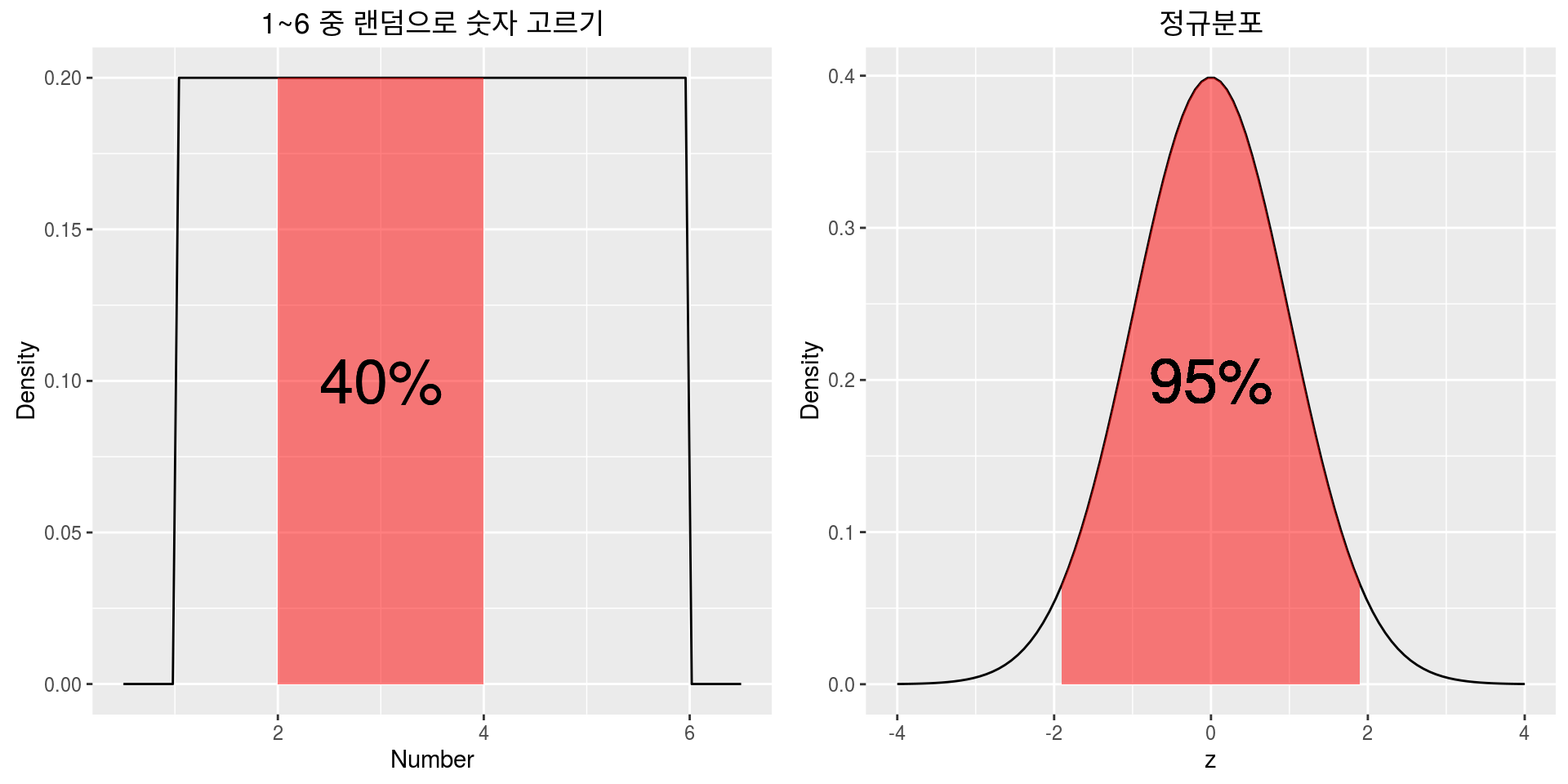
정리하자면 연속사건의 경우에는 특정 사건이 일어날 확률은 모두 0이며, 어떤 구간에 속할 확률은 PDF를 이용해서 구할 수 있다고 할 수 있다. 그러면 특정 사건에 대한 해석은 할 수 없는 것인가? 순순히 할 수 없다고 말하기는 아쉽다. 위의 정규분포의 경우를 보면 0이 나올 확률도 0, 1이 나올 확률도 0, 999가 나올 확률도 0으로 모두 같으므로 0, 1, 999가 나올 가능성은 전혀 차이가 없다고 말해야 한다. 그러나 우리 모두는 정규분포의 그림을 보고 직관적으로 느끼고 있다. 가장 위로 솟아올라 있는 0 근처가 나올 가능성이 가장 높고, 1 근처가 나올 가능성은 그보다 낮으며, 999같이 큰 수가 나올 가능성은 거의 없다는 것을… 그러나 확률이라는 지표로는 이런 연속사건간의 가능성 차이를 표시할 수가 없다는 문제가 있다.
2. 특정 사건이 일어날 가능성을 비교할 수는 없을까?: 가능도(Likelihood)
방금 설명한 대로 연속사건에서는 특정 사건이 일어날 확률이 전부 0으로 계산되기 때문에 사건들이 일어날 가능성을 비교하는 것이 불가능하며, 가능도라는 개념을 적용해야 이를 비교할 수 있다. 그러나 지금 가능도의 엄밀한 정의를 설명하는 것은 이해를 돕는데 도움이 안될 것이며, 직관적인 설명을 이용할 것인데, 쉽게 말하자면 위에 있는 그래프들에서 y값을 가능도로 생각하면 된다. 즉, y값이 높을수록 일어날 가능성이 높은 사건이라는 것이다. 주사위나 동전을 던지는 경우는 y값이 각 사건이 일어날 확률을 나타내었으므로 가능도=확률이 되어, 확률이 높을수록 일어날 가능성이 높은 사건이 된다. 한편 정규분포같이 연속사건인 경우는 PDF의 값이 바로 y가 되며 0에 해당하는 PDF값이 0.4로 1 에 해당하는 PDF값인 0.24보다 높아 0 근처의 숫자가 나올 가능성이 1 근처의 숫자가 나올 가능성보다 높다고 할 수 있으며, 0이 나올 확률과 1이 나올 확률이 모두 0인 것과는 대조적이다. 이를 정리하면 가능도의 직관적인 정의는 다음과 같다.
- 가능도의 직관적인 정의 : 확률분포함수의 y값
- 셀 수 있는 사건: 가능도 = 확률
- 연속 사건: 가능도 ≠≠ 확률, 가능도 = PDF값
3. 사건이 여러 번 일어날 경우에서의 가능도
이번에는 사건이 여러 번 일어날 경우를 생각해 보자. 먼저 아래의 두 문제를 풀어보자.
- 주사위를 3번 던져 각각 1,3,6이 나올 확률은 얼마일까?
- 동전을 10번 던지는 일을 3회 시행하여 앞면이 각각 2,5,7번 나올 확률은 얼마일까?
1번의 경우 주사위를 던져 1,3,6이 나올 확률은 전부 1616이므로 정답은 1/6×1/6×1/6=1/216이고, 2번의 경우 동전을 10번 던져 앞면이 2,5,7번 나올 확률은 앞에서와 같이 각각 0.044, 0.246, 0.117이므로 정답은 0.044 × 0.246 × 0.117= 0.001이다. 가능도도 마찬가지이다. 앞서 셀 수 있는 사건에서는 확률과 가능도가 같다고 했으므로 주사위를 3번 던져 각각 1,3,6 이 나올 가능성을 나타내는 가능도는 1/216이 되고, 동전을 던지는 경우의 가능도도 마찬가지로 확률과 같은 0.001이 된다. 이제 연속사건이 여러 번 일어날 경우를 살펴보자. 앞서 언급한 평균 0, 분산 1인 정규분포에서 숫자를 3번 뽑았을 때 차례대로 -1,0,1이 나올 확률은 각각의 사건이 일어날 확률이 모두 0이므로 결국 0이 된다. 그러나 가능도의 경우 -1,1이 나올 가능도는 0.24, 0이 나올 가능도는 0.4이므로 -1,0,1이 나올 가능도는 0.24 × 0.4 × 0.24 = 0.02가 되어 확률과는 다른 값으로 나타나게 된다.
VAE의 목표

VAE의 목표는 Generative Model의 목표와 같다. (1) data와 같은 분포를 가지는 sample 분포에서 sample을 뽑고 (2) 어떤 새로운 것을 생성해내는 것이 목표다. 즉,
- (1) 주어진 training data가 p_data(x)(확률밀도함수)가 어떤 분포를 가지고 있다면, sample 모델 p_model(x) 역시 같은 분포를 가지면서, (sampling 부분)
- (2) 그 sample 모델을 통해 나온 inference 값이 새로운 x라는 데이터이길 바란다. (Generation 부분)
예를 들어, 몇 개의 다이아몬드(training data)를 가지고 있다고 생각해보자. 그러면 training 다이아몬드 뿐만아니라 모든 다이아몬드의 확률분포와 똑같은 분포를 가진 모델에서 값을 뽑아(1. sampling) training 시켰던 다이아몬드와는 다른 또 다른 다이아몬드(new)를 만드는(2. generate) 것이다.
더 자세한 VAE의 구조
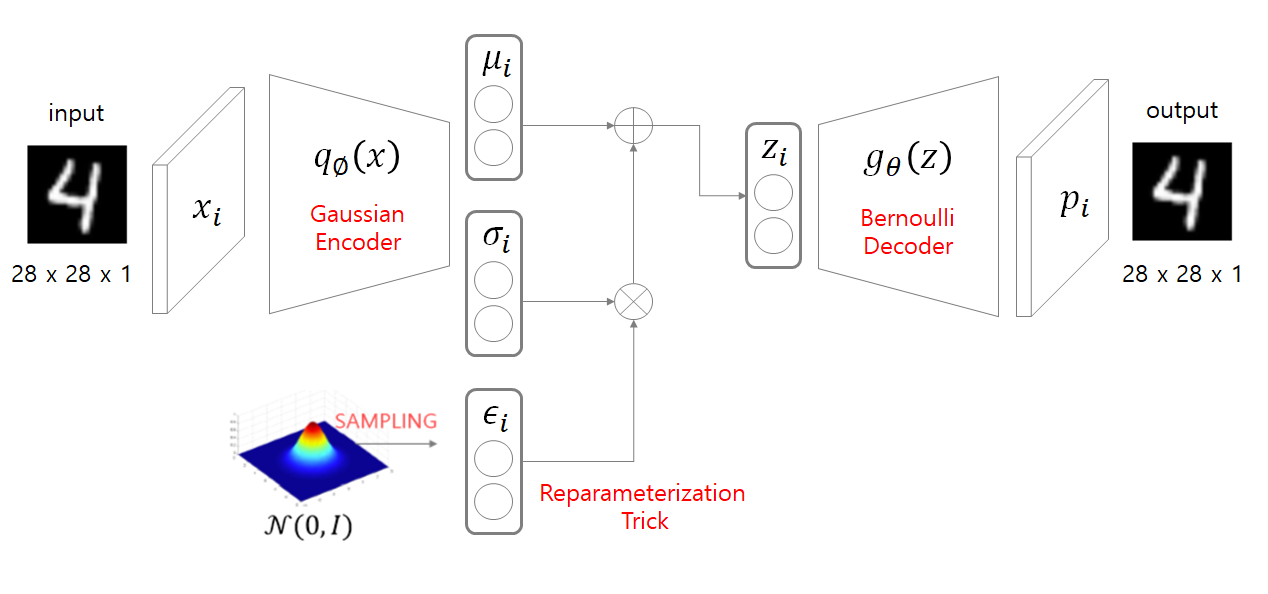
코드와 논문과 다른점 : Input shape, Encoder의 NN 모델, Decoder의 NN모델 (코드에서는 왼쪽의 각 부분들을 DNN을 CNN구조로 바꿈)
저 4가 그려진 input 그림에서 output이 나오기까지의 3단계
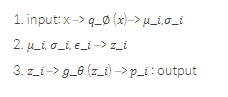
1. Encoder



q_세타?(x)는 encoder 함수인데 x를 인풋에 넣으면 z값의 분포의 평균,분산을 아웃풋으로.. (0~1사이 평균 u_i, 분산 시그마_i)
어떤 데이터의 특징을 X를 통해 추측하게 되는데, 그 특징들의 분포는 정규분포를 따른다고 가정.
-> Encoder 함수의 output은 latent variable의 분포의 평균과 분산(표준편차)를 내고, 이 두 값을 표현하는 확률밀도함수라고 볼 수 있다.
2. Reparameterization Trick (Sampling)

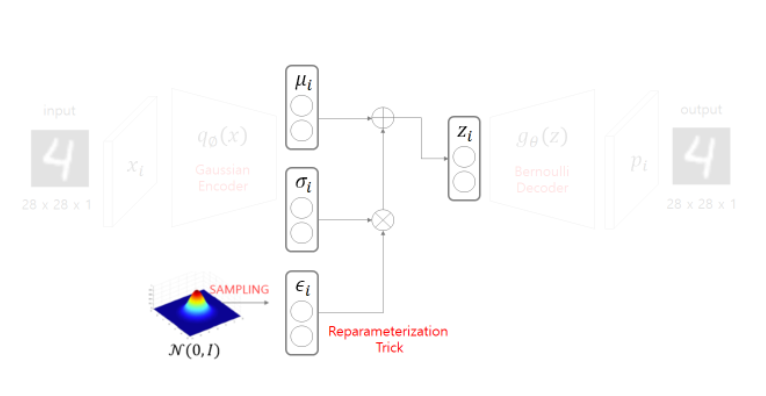

만약 Encoder 결과에서 나온 값을 활용해 decoding 하는데 sampling 하지 않는다면 어떤 일이 벌어질까? 당연히 한 값을 가지므로 그에 대한 decoder(NN)역시 한 값만 뱉는다. 그렇게 된다면 어떤 한 variable은 무조건 똑같은 한 값의 output을 가지게 된다.
하지만 Generative Model, VAE가 하고 싶은 것은, 어떤 data의 true 분포가 있으면 그 분포에서 하나를 뽑아 기존 DB에 있지 않은 새로운 data를 생성하고 싶다. 따라서 우리는 필연적으로 그 데이터의 확률분포와 같은 분포에서 하나를 뽑는 sampling을 해야한다. 하지만 문제점.
그냥 sampling 한다면 sampling 한 값들을 backpropagation 할 수 없다.(아래의 그림을 보면 직관적으로 이해할 수 있다) -> reparmeterization trick을 사용한다. (입실론 가지고 뭘 하는듯?)
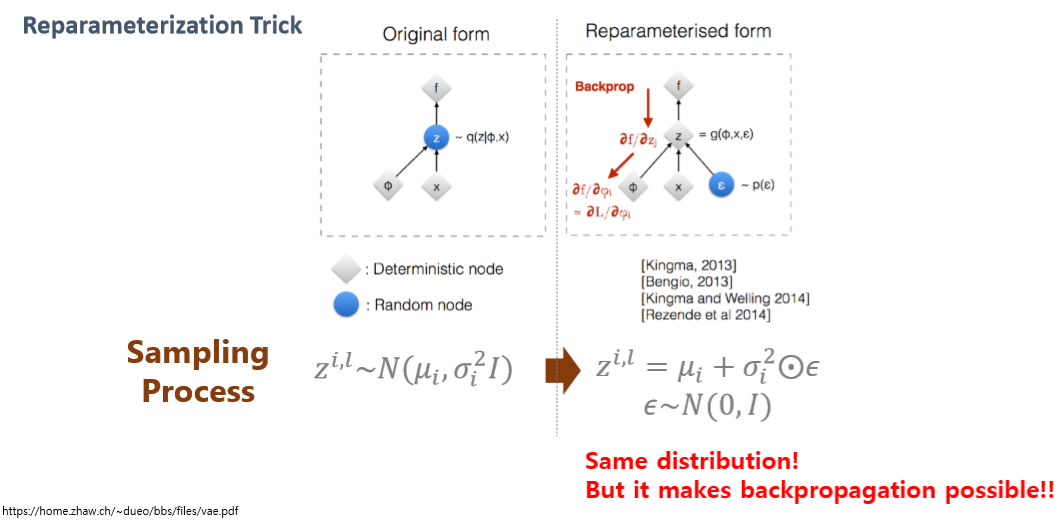
위의 코드를 보면 정규분포에서 z1를 샘플링하는 것이나, 입실론을 정규분포(=N(0,1))에서 샘플링하고 그 값을 분산과 곱하고 평균을 더해 z2를 만들거나 두 z1,z2 는 같은 분포를 가지기 때문이다. 그래서 코드에서 epsilon을 먼저 정규분포에서 random하게 뽑고, 그 epsilon을 exp(z_log_var)과 곱하고 z_mean을 더한다. 그렇게 형성된 값이 z가 된다.
3. Decoder



z 값을 g 함수(decoder)에 넣고 deconv(코드에서는 Conv2DTranspose)를 해 원래 이미지 사이즈의 아웃풋 z_decoded가 나오게 된다. 이때 p_data(x)의 분포를 Bernoulli 로 가정했으므로(이미지 recognition 에서 Gaussian 으로 가정할때보다 Bernoulli로 가정해야 의미상 그리고 결과상 더 적절했기 때문) output 값은 0~1 사이 값을 가져야하고, 이를 위해 activatino function을 sigmoid로 설정해주었다. (Gaussian 분포를 따른다고 가정하고 푼다면 아래 loss를 다르게 설정해야한다.)
VAE 학습
1. Loss function의 이해 - 크게 2 가지 구성요소가 있음.
- Reconstruction Loss(code에서는 xent_loss)
- Regularization Loss(code에서는 kl_loss)


- Generative 모델답게 새로운 X를 만들어야하므로 X와 만들어진 output, New X와의 관계를 살펴봐야하고, 이를 Reconstruction Loss 부분이라고 한다. 이때 디코더 부분의 pdf는 Bernoulli 분포를 따른다고 가정했으므로 그 둘간의 cross entropy를 구한다.
- X가 원래 가지는 분포와 동일한 분포를 가지게 학습하게 하기위해 true 분포 & approximate 한 함수의 분포에 대한 loss term이 Regularization Loss다. 이때 loss는 true pdf 와 approximated pdf간의 D_kl(두 확률분포의 차이(거리))을 계산한다.
그럼 최종적으로 VAE의 학습은 encoder 부분과 decoder 부분을 합쳐 한 모델을 만들고 train 하면 끝! 자세한 코드는 Github에 올려두었으니 참고하기 바란다.(블로그저자)
VAE 결과(시각화)
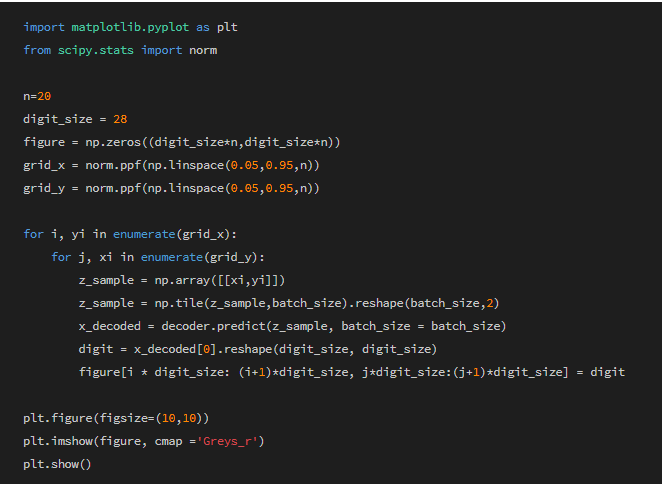

학습이 잘 되었을수록 2D 고악ㄴ에서 같은 숫자들을 생성하는 z들은 뭉쳐있고, 다른 숫자들을 생성하는 z들은 떨어져있다.
위의 코드를 실행시키면 위 그림에서 오른쪽과 같은 도식이 나오는데 학습이 잘 되었다면 차원의 manifold를 잘 학습했다는 말이다. 그 manifold를 2차원으로 축소시킨 것(z1,z2)에서 z1 20개(0.05~0.95), z2 20개, 총 400개의 순서쌍의 xi,yi에서 sample을 뽑아 시각화한것이 오른쪽 그림인데 2D상에서 거리의 유의미한 차이에 따라 숫자들이 달라지는 것을 확인할 수 있으며, 각 숫자 상에서도 서로 다른 rotation들을 가지고 있다는 것이 보인다.
마지막으로 VAE는 왜하냐고 물어본다면 크게 2가지로 답할 수 있다.
- Generative Model 목적 달성
- Latent variable control 가능
- Generative Model을 통해 적은 data를 가지고 원래 data가 가지는 분포를 꽤 가깝게 근사하고 이를 통해 새로운 data를 생성해낼 수 있다는 점.
- Latent variable의 분포를 가정해 우리가 sampling 할 값들의 분포를 control 할 수 있게 되고, manifold도 잘 학습이 된다는점.
- 이는 data의 특징들도 잘 알 수 있고, 그 특징들의 분포들은 크게 벗어나지 않게 control 하면서 그 속에서 새로운 값을 만들 수 있다는 점.
정도가 될 것 같다.
VAE의 한계점을 극복하기 위해, CVAE, AAE가 나왔으니 관심있는 사람은 관련된 자료를 찾아보기 바란다
VAE는 입력 데이터를 다음과 같이 단순화된 표현인 잠재 벡터로 압축합니다.
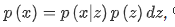
여기서 z의 영역은 연속적이므로 다루기 어렵습니다. 이러한 이유로 이 난해성은 log-likelihood [44] 의 하한을 통해 풀 수 있기 때문에 변이 추론이 사용됩니다.
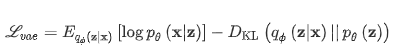
q-세타 :
Lvae : VAE Likelihood
첫 번째 항: log-likelihood를 최대화하여 코딩-디코딩 방식을 가능한 한 효율적으로 만드는 경향이 있는 x의 재구성입니다.

샘플링으로
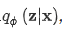
->즉, 인코더의 주요 목표는 입력 데이터를 저차원 공간에 매핑하여 특징 추출기 역할을 하는 것입니다
두번째 항: 확률 분포가 다른 확률 분포에서 얼마나 많이 발산하는지 측정하는 Kullback-Leibler divergence
인코더에서 반환된 분포가 표준 정규에 접근하도록 하여 잠재 공간의 구성을 정규화하는 경향이 있습니다. 이는 변동 근사와 z의 사전 분포 사이의 KL 발산을 최소화하여 잠재 변수(z로 표시)를 정규화합니다.
데이터는 인코더에 의해 학습된 조건부 확률 분포 p(x–z) 에서 재구성됩니다 . 생성 목적을 위해 잠재 공간에서 생성된 정규화 는 새 데이터 생성을 위한 무작위 샘플링 및 보간을 용이하게 합니다. 이것이 VAE가 생성 모델 로 이해 되고 그 사용이 널리 사용되는 이유입니다.
그러나 VAE는 주로 생성 작업을 지향하고 이로 인해 인코더가 데이터를 가능한 한 압축된 상태로 투영하도록 하여 잠재적인 공간을 정규화하여 명백한 중복이 발생하기 때문에 이것은 문헌에서 더 이상 탐구되지 않습니다.
이러한 겹침으로 인해 RUL을 추정하기 어렵기 때문에 이는 우리 목표에 대한 장벽입니다. 먼저 시각적으로: 비슷한 RUL 값을 가진 항공기는 지도에서 가깝지만 멀리 있는 항공기와 명확하게 구분되지 않습니다. 그러면 이 위에 구축된 모든 모델이 이 표현을 따르고 예측 실패를 초래할 가능성이 높기 때문입니다. 따라서 바닐라 VAE는 우리의 요구를 충족하지 않으며 문제에 대한 변이 추론의 사용을 조정해야 합니다. 우리가 원하는 것은 분류기가 아닌 회귀를 사용하여 변이 인코딩의 잠재적 조직 속성을 향상하는 것입니다.
VAE와 우리 모델의 차이점
우리가 택하기로 결정한 경로에는 해석 가능한 잠재 공간을 얻는 데 학습에 집중하기 위해 디코더를 생략하는 것이 포함됩니다. 따라서 VAE와 관련된 주요 차이점은 그림 3 과 같이 디코더를 회귀 모델로 교체 하고 훈련이 다르게 수행된다는 것입니다. 제안된 모델은 두 가지 목표로 구성된 손실 함수를 최소화하도록 훈련되었습니다.
VAE와 다른 우리 모델의 Loss

첫 번째 목적은 이전 Eq. (3) 두 번째 는 알려진 RUL과 모델에 의해 예측된 RUL 사이의 RMSE( Root Mean Square Error )입니다.
그림 4 (VAE와 우리모델의 차이 그림)의 오른쪽 부분는 이러한 방식으로 모델을 훈련하는 효과를 보여줍니다. 회귀자의 아키텍처는 간단합니다. 인코더 기반 위에 tanh 활성화 함수 가 있는 FC 레이어와 RUL 예측을 포함 하는 단일 뉴런 이 있는 다른 레이어 가 추가됩니다.
인코더로는 반복 네트워크(recurrent network)로 구현했다. [47] , [48]. 찾을 수 있는 다양한 유형의 RNN 중에서 LSTM 네트워크가 가장 많이 사용됩니다. 이러한 네트워크는 숨겨진 상태를 통해 과거의 정보를 보존하면서 데이터를 역방향에서 순방향으로 처리합니다. 그러나 양방향 LSTM 네트워크는 과거에 대한 정보뿐 아니라 미래에 대한 정보도 제공하기 때문에 수요가 높습니다. 데이터는 먼저 과거에서 미래로 처리된 다음 미래에서 과거로 처리되어 두 기간의 정보를 보존합니다. 이는 네트워크가 미래 단계에서 데이터가 어떻게 보일지 알고 있기 때문에 어떤 종류의 정보를 예측해야 하는지 이해하는 데 도움이 되기 때문에 매우 유용합니다.
요약하면 양방향 LSTM으로 구축된 인코더는 가우스 분포 를 근사화합니다

출력을 두 개의 선형 모듈에 공급하여 평균과 공분산을 추정합니다. 이는 인코더에 의한 엔진 데이터 압축으로 축이 근사 분포의 평균 및 공분산이 되는 2차원 잠재 공간이 생성됨을 의미합니다. 결과적으로 학습된 잠재 공간은 엔진 궤적을 기본 특성에 따라 다른 클러스터로 그룹화하여 단순화된 표현을 설명할 것으로 예상됩니다.
3.2 해석 가능한 진단
이번 작업에서 소개하는 진단 도구는 엔진의 실제 상태와 정상에서 열화로의 변화율을 보여주는 맵이다. 우리가 추구하는 것은 각 포인트가 비행 이력 중 이벤트 창과 관련된 엔진의 상태를 나타내어 성능이 저하된 항공기의 포인트는 주변 영역으로 그룹화되고 반대로 정상 항공기에 속하는 포인트는 위치하도록 하는 맵입니다. (아까 그 MNIST 데이터셋처럼 비슷한 숫자를 생성하는 것은 몰려있는 시각적인 맵 형태.)
4. 실험적 설계
표 1을 보면 데이터셋의 특징을 볼 수 있다.
각 데이터 세트는 서로 다른 작동 조건에서 작동할 수 있으며 시스템 오류는 터빈 과 압축기의 두 가지 구성 요소로 인해 발생할 수 있습니다. 따라서 FD003에는 언급된 두 구성 요소 중 하나로 인해 고장이 발생할 수 있는 엔진이 포함되지만 FD001 및 FD003은 동일한 조건에서 작동합니다. 그런 다음 FD002는 FD004와 같이 6가지 작동 조건에서 작동하는 반면 FD004에서는 FD003과 같이 고장 조건이 터빈과 압축기 고장을 모두 포함합니다. 이러한 의미에서 데이터 세트의 난이도는 특성에 따라 오름차순으로 FD001, FD003, FD002, FD004라고 생각됩니다.
4-1. 정규화에 대하여
이러한 이유로 다양한 고장 조건이 전처리에 큰 영향을 미치지 않기 때문에 우리가 내리는 결정은 작동 조건이 다른 샘플에 초점을 맞추는 것입니다. 분명히 작동 조건이 사이클 간에 변하기 때문에 RUL을 분석하고 예측하는 것이 훨씬 더 복잡하기 때문입니다. Min-Max 정규화가 일반적으로 사용되기 때문에 다른 논문에서는 간과되는 것처럼 보이지만 데이터를 정규화할 때 이것을 고려하는 것이 중요합니다 [15] . 대신 condition-based 표준화 를 사용하여 다른 길을 택합니다.. 이 접근 방식을 사용하면 동일한 작동 조건의 모든 레코드가 함께 그룹화되고 표준 스케일러를 사용하여 크기가 조정됩니다. 이러한 유형의 스케일링을 적용하면 그룹화된 작동 조건의 평균이 0이 됩니다. 이 기술은 각 작동 조건에 개별적으로 적용되므로 모든 신호는 평균 0을 수신하여 비교할 수 있습니다.
한편, 센서 데이터는 일반적인 경향이 있지만 주로 고주파 센서에 의해 발생하는 국부 진동에 영향을 받아 노이즈가 발생하는 것으로 알려져 있다 [23] , [43] . 계열 처리를 쉽게 하기 위해 지수 가중 이동 평균이 수행됩니다. 필터링된 값을 계산할 때 현재 값과 이전 필터링된 값을 고려합니다. (Kalman Filter) -> 필터의 유일한 목적은 센서 측정의 진동을 줄이는 것
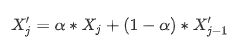
Lower values for α will have a stronger smoothing effect and consequently, stationarity is lost.
낮은 알파를 지정하면 더 강한 평활화(smoothing) 효과가 나타나, 정지상태를 잃어버린다.
그럼에도 불구하고 더 강한 평활화는 더 나은 모델 성능으로 이어집니다. 우리가 모델링하려는 것은 고장 지점의 감지가 아니라 저하율 의 변화 , 즉 일정 시간이 지나면 엔진 부품이 이전과 다른 속도로 저하되는 중단점 이라는 점에 주목하는 것이 중요합니다.
4-2. 시계열데이터 window와 time step
시계열 문제 에서 더 나은 예측 성능을 위해 데이터를 시퀀스로 분할하는 것은 매우 반복적 입니다. 즉, 다변량 계열은 엔진별로 처리되지 않고 그림 5와 같이 고정된 크기의 window으로 slicing됩니다.. 각 time step에서 데이터는 시간 창 내의 센서에서 선택되어 RUL을 예측하기 위한 네트워크에 대한 입력으로 사용되는 고차원 특징 벡터를 형성합니다. 따라서 네트워크의 각 입력 샘플에는 T30, T50, P30, EPRA, PS30, phi의 6개 센서에서 추출된 30개의 단일 주기 데이터가 포함되어 있으며 목표는 적절한 RUL 추정입니다. 마지막 몇 주기의 특정 엔진에 대한 시퀀스 분할에 창 길이를 완료하기에 충분한 데이터가 없을 수 있습니다. 이러한 경우 마스크된 값이 사용되며 해당 값을 단순히 무시하여 모델의 첫 번째 레이어에서 처리됩니다. 이러한 방식으로 가능한 한 많은 정보가 사용됩니다.

4-3. 학습에 대하여 (하이퍼파라미터, epoch 등등)
따라서 window 길이, smoothing 강도 또는 순환 계층(Recurrent layer)의 내부 뉴런 수가 핵심 요소입니다.
Hyperopt 베이지안 최적화 라이브러리에서 하이퍼파라미터 설정에 대한 참고사항을 얻는다.
LR의 정확한 선택이 특히 중요하므로 이 매개변수에 대해 적응형 LR 옵티마이저인 Adam과 [54] 에서 제안한 Cyclic Learning Rate 기법을 사용합니다.
또한 콜백을 사용하여 Epoch 수 대신 Early stop 조건을 유효성 검사 오류로 분류하는 측면에서 실험을 사용자 정의했습니다.
4-4. 센서의 선택
센서의 선택은 임의적이지 않습니다. 우리는 T30, T50, P30, EPRA, PS30 및 phi의 6개만 사용합니다. 이들은 나중에 소개할 실제 문제에서 정확히 사용할 수 있습니다. 두 데이터 세트에서 엔진은 Turbofan 항공기 엔진 입니다. 놀랍게도 우리는 제공된 21개의 센서 중 대부분이 유사한 작업에 사용되는 센서를 사용하여 계산 비용을 절감할 뿐만 아니라 RUL을 효율적으로 예측할 수 있는 충분한 정보를 제공한다는 것을 발견했습니다. 또한 데이터 세트 FD001 및 FD003의 경우 EPRA 센서는 서로 다른 작동 조건에서 엔진 추력을 측정하는 반면 FD001 및 FD003은 동일한 조건에서 작동하므로 필요하지 않습니다. 따라서 이 센서는 관련 정보를 제공하지 않고 캡처된 값은 단순히 일정하게 유지됩니다.
4-5. training과 validation의 비율
훈련 데이터의 20%가 검증에 사용되어 FD001 및 FD003에 대해 17692개의 훈련 샘플과 4128개의 검증 샘플, FD002에 대해 37432개의 훈련 샘플과 8787개의 검증 샘플, 마지막으로 FD004에 대해 43523개의 훈련 샘플과 10505개의 검증 샘플이 생성되었습니다. 모든 모델과 실험은 TensorFlow에서 구현되었습니다.
5. 실험 결과
제안된 프레임워크의 실험적 검증은 두 부분으로 구성됩니다.
1. C-MAPSS 데이터셋은 우리의 프레임워크를 RUL 추정을 위한 다른 모델들과 비교.
2. 우리가 제시하는 실제 문제의 실제 엔진뿐만 아니라 C-MAPSS 엔진은 잠재 공간에서의 투영을 기반으로 진단됩니다. 수치적 결과 + 시각화된 진단 지도가 제시, 실험적 검증이 논의됩니다.
5-1. RUL 측정에 대한 성능
기존 방법들은 데이터를 나타내지 않고 다음 단계에 해당하는 RUL만 예측한다는 점을 언급할 가치가 있습니다. 그런데 우리 방법은 데이터를 나타내어 시각화 진단 지도까지 제공하므로 대단하다.
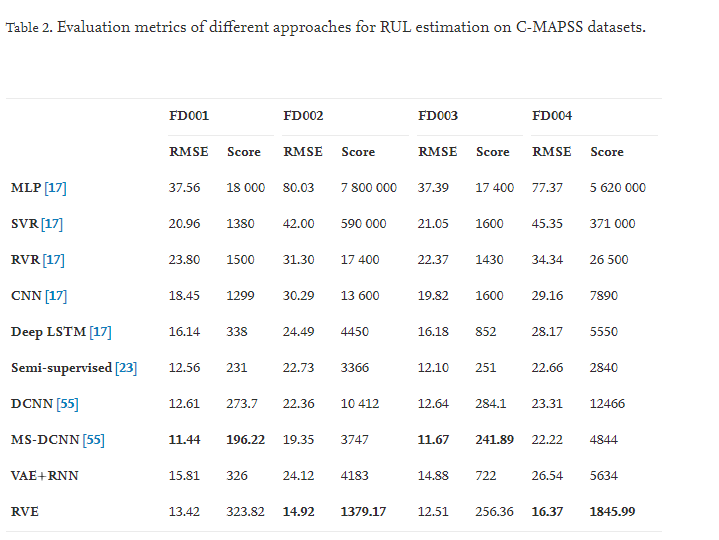
표 2을 보면 데이터 세트 FD001 및 FD003의 경우 메트릭이 양호한 것으로 간주되지만 최고가 아님을 빠르게 알 수 있습니다. 그러나 FD002 및 FD004에 관심이 집중됩니다. 작동 조건 및 고장 모드의 수가 증가함에 따라 이 두 데이터 세트에 더 복잡한 다중 스케일 저하 기능이 포함되기 때문입니다. RVE는 Score와 RMSE 모두에 대해 이 두 가지 예측 정확도를 크게 향상시킵니다.
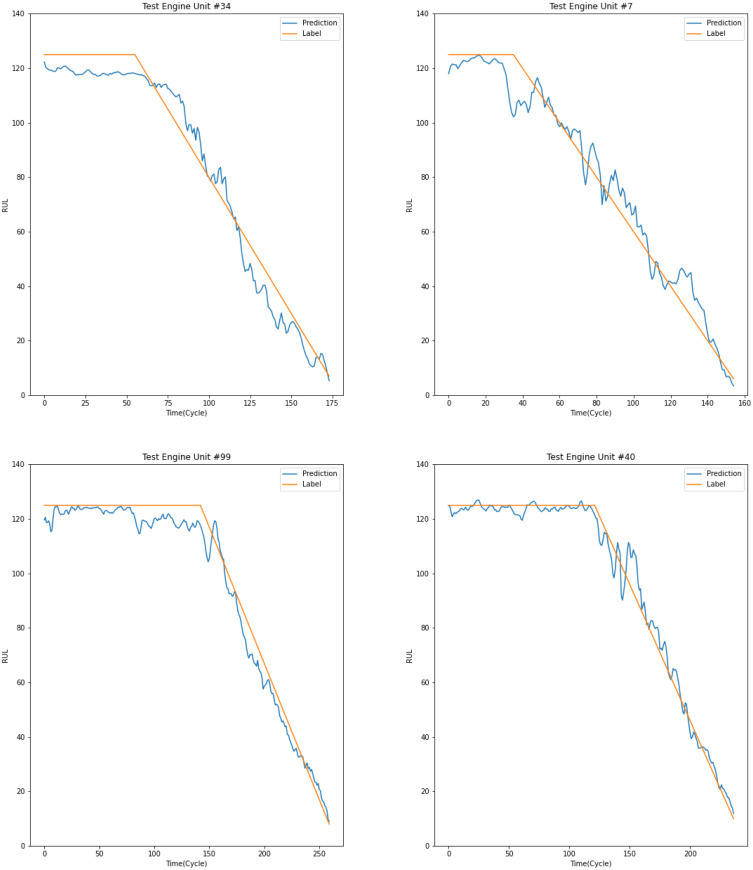
다른 데이터 세트에 해당하는 일부 테스트 엔진 장치의 수명에 대한 RUL 추정이 그림 6 에 나와 있습니다. RUL예측을 위해 다음과 같이 회귀선을 잡는 것은 매우 일반적이다. piece-wise function로 구성된 RUL은 주황색으로 표시되며 이 중 C-MAPSS는 마지막 cycle에 해당하는 RUL을 제공합니다. 우리의 방법으로 각 순간에 예측된 RUL 값은 파란색으로 표시됩니다. 네트워크가 이러한 성능 저하를 모델링하여 최종적으로 엔진의 실제 RUL을 정확하게 예측할 수 있음을 분명히 알 수 있습니다.
5-2. 설명 가능성 시각화 진단맵
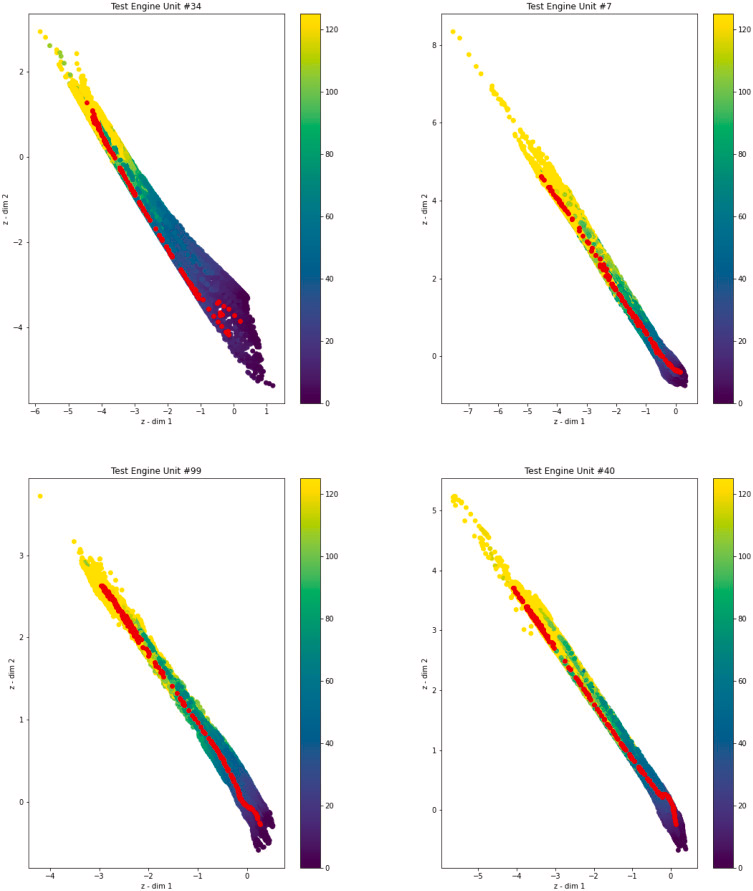
좋은 예측에도 불구하고 모드의 결정과 내부 표현의 설명 가능성에 있어 격차가 있습니다. 우리가 제안하는 것과 같은 기술로 채워질 수 있는 격차. 섹션 3 에서 설명한 것처럼 인코더에 의해 구축된 잠재 공간은 시간 경과에 따른 데이터의 발전을 이해할 수 있도록 하는 맵을 생성하기 위한 기초 역할을 하며 그림 7 은 이에 대한 샘플입니다. 각 맵은 그림 6 에 표시된 각 항공기가 이동한 사이클 세트에 대해 얻은 잠재 공간을 나타냅니다.
그림 7 : 6에 제시된 샘플의 모든 시간 단계에 대한 잠재 예측 .
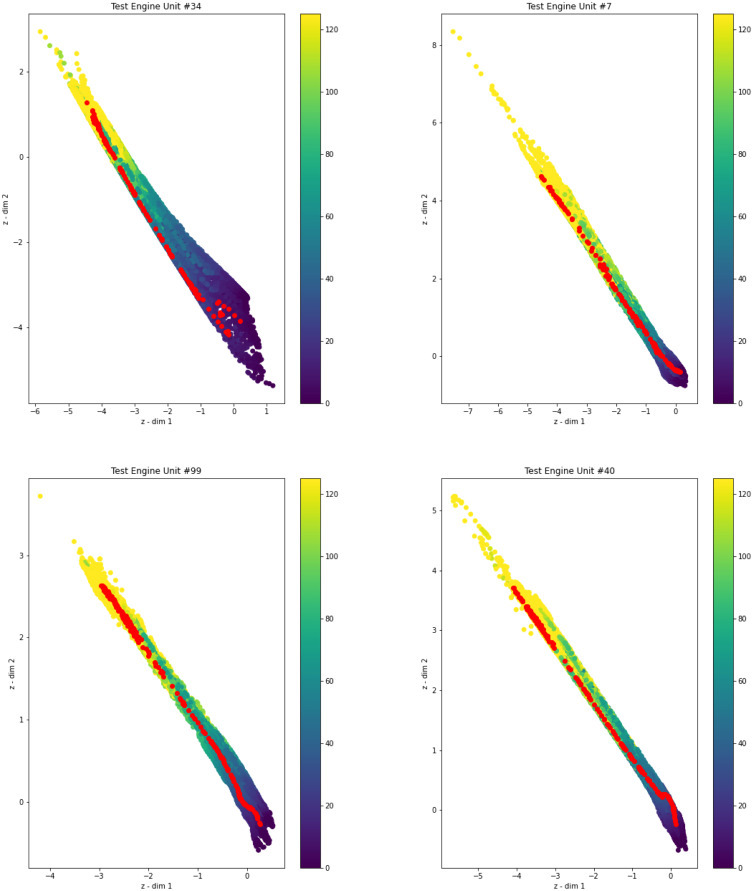
즉, 예를 들어 engine unit #7의 경우 처음 30개의 cycle의 압축된 표현은 첫 번째 왼쪽 상단 빨간색 점에 해당하는 반면 마지막 30개의 압축된 표현은 마지막 오른쪽 하단 빨간색 점입니다. 나머지 점은 훈련 중에 본 각 데이터 샘플의 표현에 해당합니다. 따라서 RUL이 색상 막대에 표시된 모든 노출된 지도에서 비행기 가좋은 조건(높은 RUL 값)에서 작동하고 있고, 잠복적인 표현은 왼쪽 상단 영역에 위치하며 성능이 저하되기 시작하면 이 위치는 비행기가 성능 저하(낮은 RUL)를 나타내는 데이터를 찾을 때까지 오른쪽으로 이동합니다.
이러한 방식으로 최소 30사이클을 비행한 항공기의 궤적 데이터를 제공할 수 있는 모델이 달성됩니다. 거기에서 우리가 찾고 있는 두 가지 진단을 얻기 위해 새 데이터 샘플을 사용할 수 있을 때마다 모델을 제공할 수 있습니다.
첫 번째 진단: 먼저 상태가 알려진 샘플에 대한 근접성을 기반으로 특정 순간의 항공기 상태를 감지하는 시각적 진단맵
두 번쨰 진단: 항공기의 남은 수명을 결정짓는 RUL 값을 명시적으로 보고하는 정량적 진단
5-3. 실제 문제에 대한 결과
제안된 모델이 보다 현실적인 맥락에서 어떻게 작동하는지 설명하기 위해 실제 엔진의 예가 아래에 제시됩니다. 데이터는 실제 사용 조건 에서 Turbofan 엔진 에서 샘플링되었습니다 . 안타깝게도 기밀 유지를 위해 회사 이름을 공개하거나 데이터 세트를 공개할 수 없습니다. 그럼에도 불구하고 엔진에 대한 간략한 설명은 표 3 에 나와 있습니다.
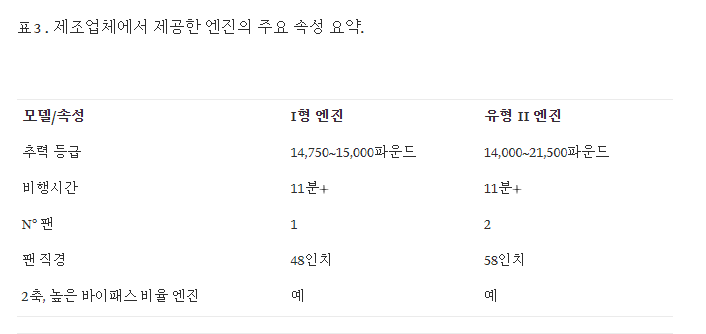
목표는 각 엔진의 데이터를 네트워크에서 처리할 수 있는 입력으로 변환하는 것입니다. NASA의 데이터 세트에서와 같이 훈련 중에 모델은 다양한 열화 패턴을 학습하여 인코더가 열화에 따라 엔진 장치를 잠재 공간으로 투영하여 정상 엔진과 손상된 엔진 사이의 거리에서 일관성을 유지합니다. 이 예측은 진단되지 않은 유닛이 주어지면 비행 횟수가 증가함에 따라 성능 저하가 어떻게 진행되는지 알아내기 위한 기초로 다시 사용됩니다.
그림 8을 보면 여섯 대의 비행기가 두 가지 다른 시간 단계에서 상태를 잠재 공간으로 투영하도록 선택되었습니다.

그림 8: 6개의 선택된 엔진의 RUL 진화. cycle이 진행됨에 따라 항공기는 진단이 알려진 유사한 저하 패턴을 가진 다른 항공기와 가까운 영역에 배치되므로 e5 및 e6의 경우와 같이 더 빠르게 저하되는 항공기를 쉽게 식별할 수 있습니다.
모델에서 제공하는 RUL이 색상 막대에 표시됩니다.
훈련 후 얻은 잠재 투영을 수정하면 다음 장치의 상태 진행 상황에 대한 통찰력을 얻을 수 있습니다. 표시된 단계 동안 엔진 e1, e2, e3 및 e4..의 잠재 투영은 다른 항공기 옆의 왼쪽 위 사분면 위에 남아 있습니다. 유사한 특성: 약 200회 cycle (t=0~t=1000)의 RUL, 거의 저하의 징후가 없습니다. 반대로, 샘플 e5 및 e6은(긴 화살표) 명확하게 아래쪽으로 이동하여 수명이 거의 다한(낮은 RUL 값) 엔진 장치와 함께 배치되어 가능한 레이블을 넘어 정확하고 설명 가능한 진단을 얻는 명확한 진행이 있습니다. 예측된 건강을 나타냅니다.
표시된 그림에서 센서 의 데이터에 따라 엔진의 상태 업데이트를 표시하기 위해 두 가지 시간 단계(t=0, t=1000)만 선택되었습니다 . 그러나 각 후속 여행에서 네트워크에 충분한 데이터를 제공할 수 있게 되면 순환 네트워크 를 사용하기 때문에 이 업데이트를 수행할 수 있습니다. 소개에서 언급했듯이 이것은 온라인 프로세스이며 각 시스템의 수명이 지속적으로 모니터링됩니다. 특히 회사에서 이러한 모터는 정기적인 유지 보수 주기가 있으며 이상 작동을 감지하면 경고하는 병렬 시스템도 있습니다.
방법 해석의 예는 다음과 같습니다. 그림 8 에서 화살표는 각 샘플의 진화를 묘사하는 데 사용되었지만 이전 하위 섹션에서 설명한 것처럼 모든 단계의 footprint이 기록됩니다(즉, 잠재 투영 t에 사용할 수 있습니다 t=1, t=2, t=3 등) 따라서 시간이 지남에 따라 분명한 발전이 있으며 이러한 업데이트의 비율은 실제 시나리오에서 경고를 트리거할 수 있습니다.(고장 나기 전 미리 기계공에게 말하는 등)
6. 결론 및 향후과제
우리는 항공기 엔진 진단 을 해결하기 위해 잠재 표현을 정규화하는 새로운 방법으로 변형 인코딩(variational encoding)을 기반으로 하는 새로운 아키텍처를 제안했습니다 . 이는 변동 추론(variational inference)을 통해 얻어지며 잘못된 RUL 추정에 불이익을 주는 비용 함수의 항에 의해 형성됩니다. 그 결과 VAE와 같은 다른 모델과 마찬가지로 급격한 점프 없이 엔진 궤적의 이력을 지속적으로 투영할 수 있는 잠재 공간이 생깁니다 . 결과적으로 인코더가 학습한 잠재 공간은 진단 도구로 사용됩니다. 보이지 않는 엔진이 주어지면 유사한 저하 패턴을 가진 엔진 근처에서 인코딩을 투영하기 위해 서로 다른 열화 단계를 가진 엔진 데이터의 2차원 표현(시각화 진단맵)을 학습합니다. 따라서 설명 가능한 진단이 지배적입니다.
마지막으로, 향후 작업에서 상태 모니터링 및 예측 유지 관리 (https://www.sciencedirect.com/topics/engineering/predictive-maintenance)와 관련된 다른 영역에서 모델의 적합성을 탐색하는 것을 목표로 합니다 . 또한 모델이 저하 단계를 구별하는 것 외에도 다양한 분야의 실패원인(예방적 유지보수)을 설명할 수 있는 잠재 기능을 학습하도록 동기를 부여하는 것이 흥미로울 것입니다.
코드
https://github.com/NahuelCostaCortez/Remaining-Useful-Life-Estimation-Variational
GitHub - NahuelCostaCortez/Remaining-Useful-Life-Estimation-Variational
Contribute to NahuelCostaCortez/Remaining-Useful-Life-Estimation-Variational development by creating an account on GitHub.
github.com

docker 또는 아나콘다 가상환경으로 개발환경을 세팅하라고 되어있다. 또는 jupyter notebook도 제공한다.
main.py - train을 실행하는 메인파일
model.py - 모델 정의: 논문에 나온 내용을 구현시킴

experimentalResults.ipynb - 시각화 진단맵과 training, test set의 RMSE 측정 ipynb 파일

RULRVE.ipynb - 모델 정의, train, 성능 측정까지 모두 있는 ipynb 파일

RVE(Recurrent Variational Encoder) 모델 총정리 (사안 4가지)
사안1. 우리 모델의 구조 : 인코더(대부분 VAE를 사용하는데 우리는 기존 VAE와 다른 VAE + Recurrent Network인 LSTM 사용) + 잠재 공간(feature가 있는 임베딩벡터) + Regressor



인코더의 output은 latent variable의 분포의 평균(mu)과 분산(sigma)를 내고, 이 두 값을 표현하는 확률밀도함수라고 볼 수 있다.
우리 모델 구조와 기존 VAE가 다른 점 : 그림 3 과 같이 1. 디코더를 회귀 모델로 교체 하고 2. 훈련을 다르게(loss function을 다르게 설정) 수행된다는 것입니다. 제안된 모델은 두 가지 목표(DKL , RMSE)로 구성된 손실 함수를 최소화하도록 훈련되었습니다.


사안 2. 센서 데이터에 대해 : 1. 정규화 2. 필터링
- 보통 Min-Max 정규화를 많이 사용하는데 우리는 Condition-Based 정규화를 사용하였음.
- 칼만 필터를 이용해 센서의 노이즈를 감소시키고, smoothing 작업을 함.
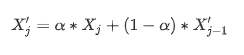
사안 3. 다른 모델 : RVE 수명 예측 / 우리 모델 : RVE 수명 예측 + 시각적 진단맵까지 제공해서 설명력 UP

사안 4. CMAPSS를 사용한 타 모델과 비교했을 때 성능은 아래 표2와 같음. 특히 우리 모델은 더 어려운 데이터유형인 FD002와 FD004(6가지 조건 하에서 진행되어 FD001, FD003보다 난이도가 높음)에서 뛰어난 성능을 보임
