2022. 5. 4. 12:34ㆍ카테고리 없음
학습 목차
1. AI, 머신러닝, 딥러닝의 차이 이해
2. 머신러닝의 기초
3. 머신러닝 문제의 분류
4. 학습 방법의 분류
5. Colab, Python, Numpy를 통한 튜토리얼

AI : 사람처럼 행동,생각하는 프로그램이다 by Russell & Norvig 교수

Acting Rationally : 최대효율, 엔지니어의 마인드와 비슷
그럼 AI인데 머신러닝이 아닌 것들은? -> Traditional AI
: 규칙 시스템 ( 스팸메일, 서치알고리즘(ex tree search - 가능한 경우의 수를 트리구조로 조사, 최선의 결과로 이어지는 액션을 취하는 것) )
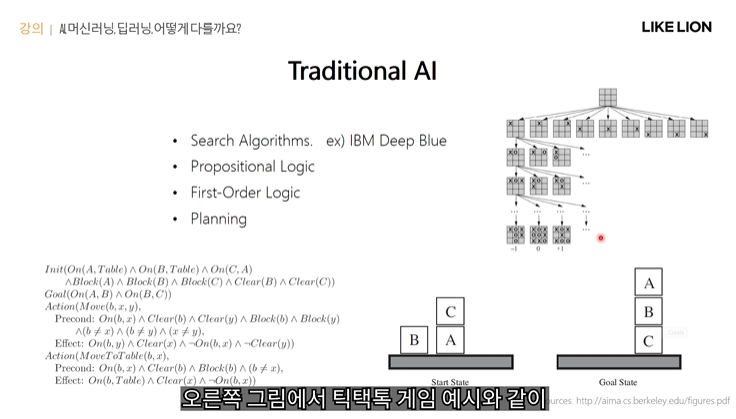
플래닝 알고리즘 : init state와 goal state가 주어지고, 어떤 액션을 어떤 순서로 취해야 goal state에 도달할 수 있을지를 찾는 것
-> 그러나 전통적 AI로는 요즘 해결할만한 문제들의 경우의 수가 너무 많다보니, 해결하는데 한계가 있음. (바둑 10^170)
-> 머신러닝

자율주행 : 뒷 차와 간격에 따라 속도를 몇으로 하고, 언제 멈출지 정하는 것 -> 전문가도 감으로 하는 부분.
따라서 머신러닝으로 이를 해결
머신러닝 : 데이터로부터 학습. 미래의 task에 대한 성능을 높임. 사람이 룰을 정해주는 것이 아니라 사람이 운전하는 데이터를 수집하고 그 데이터로부터 사람의 운전 패턴을 배우겠다는 것. 학습 데이터가 많아질수록 성능이 좋아진다.
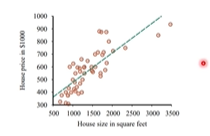
ex 집의 크기와 가격에 대한 회귀
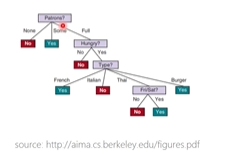
ex 식당에서 wait를 할지 말지 결정하는 Decision Tree(데이터를 통해 룰들을 학습한 것)
딥러닝 : 계층적 표현학습 = Hierarchical representation(여기서 representation=뉴럴 네트워크의 각 레이어에서 추출되는 feature)
계층적 표현학습 이라는 것은 input data가 뉴럴네트워크를 통과함에 따라 로우레벨 feature에서부터 하이레벨 feature까지 계층적으로 학습한다는 것이다.
ex input데이터가 이미지다 -> 로우레벨 feature : 엣지, 코너, 중간레벨 : 물체, 하이레벨 : 전체모습
8~90년대에도 뉴럴네트워크가 있었지만 2000년대 오면서 Big Data와 GPU, Memory 가 발전하면서 다시 전성기를 되찾음.

그러나 만능은 아님. 특정 task에 특정되지 않은 범용적 Deep learning은 아직 갈 길이 멀고
의료 같이 전문도가 높은 분야에서는 인간 이하의 성능을 보임.
딥러닝은 데이터셋이 많으면 많을 수록 좋음. 그래서 데이터셋이 적은 분야는 성능을 띄기 어려울 수 있다.
로보틱스 등 데이터가 부족한 일부 분야에서는 머신러닝이 더 뛰어난 성능
유튜브 추천알고리즘과 같은 structured big data의 경우 딥러닝이 뛰어난 성능

정리

롤베이스 시스템 : 사람이 정한 규칙에 따라 인풋에서 바로 아웃풋 계싼
클래식 머신러닝 : 사람이 디자인한 feature를 뽑아낸 다음에 그 feature로부터 결과값을 내도록 학습
(색칠된 박스는 학습이 필요한 모듈이다)
머신러닝 representation learning : 사람이 디자인한 feature 대신에 직접 feature까지 학습
딥러닝 : 딥 뉴럴 네트워크를 이용해 feature를 계층적으로 학습(ex 자율주행 - 초창기는 앞차와의 간격에 따라 속도를 조절, 진화된 운전보조시스템 - 차간간격, 차선과의 거리 각도 등과 같은 핸드 디자인 feature를 이용
완전 자율주행 - by 테슬라. 카메라에서 받아온 이미지를 그대로 뉴럴네트워크에 넣어서 운전을 학습.
머신러닝 기초
머신러닝 - 크게 두 개의 step으로 이루어짐

1. training(=learning)
모델을 training data에 fitting 시키는 과정이다. 모델 = 뉴럴네트워크, 디시젼트리 등
학습을 통해 training data를 가장 잘 설명하는 모델을 찾고난 후, test 혹은 inference 과정에서 학습한 모델을 통해
test data에 대해 최종 성능을 측정하게 된다.
2. dataset
머신러닝의 중요한 요소. training, validation, test set이 있다. 보통 몇만개 정도 되는 데이터 6:2:2, 100만개 이상 큰 데이터 9:1:1로 나눈다. 데이터셋이 크지 않은 경우에는 어떻게 나누느냐에 따라 모델의 성능이 달라질 수 있다. -> k fold cross validation (교차검정법)
validation : 성능을 측정해서 fitting, 과적합 탐지 모의고사
test : 최종 모델에 대한 성능 측정 수능

교차검정법 k fold : 데이터셋을 k개의 부분집합으로 분화하고 그 중 하나는 test로 나머지는 training으로 사용해서, k개의 모델을 학습하고 성능을 k개 모델의 평균 test셋 에러로 측정. 데이터셋 구성에 따른 영향은 최소화, 모델 성능 측정 가능
performance measure : loss function = cost function = 손실함수
머신러닝의 목적 : 그냥 task가 아닌 feature task에 대한 성능을 개선한다.
ML의 궁극적인 목표는 새로운 인풋 데이터가 들어와도 좋은 성능을 내는 모델을 학습시키는 것이기 때문이다.
-> Egen를 최소화하는 것=0이 목표인데, Egen은 힘드니 Etest로 대체하는 것
-> Etest를 최소화하는 것 을 두 개의 목적으로 split : 1 Etrain을 줄이면서 동시에 2 Etest와 Etrain이 비슷해지기를 원함.
-> 1 Etrain을 줄이기 위해 training set을 학습시킨다. 이떄 optimization을 사용,
-> 만약 위 단계에서 Etrain이 0보다 훨씬 크게 되면 = fitting이 잘 안된다 = underfitting = bias가 크다고 한다.
-> 2 Etest ~= Etrain 이때 regularization을 사용, training data를 추가하기도 한다.
-> 만약 위 단계에서 Etest~=Etrain을 실패하게 되면 = overfitting = variance가 크다.

단순한 모델, 복잡한 모델 -> 어떤 모델을 고를까?
모델의 capacity가 작다 크다 = 단순 복잡한 모델의 척도.
capacity가 크다 = 더 다양한 함수들에 fitting 될 수 있다는 것이다.
적절한 모델을 고르지 않으면 underfitting, overfitting이 생길 수 있다.
그럼.. 어떻게 고르라는 거냐
-> Occam's razor : 데이터와 잘 부합하는 모델 중 가장 단순한 모델을 골라라.

capacity가 큰 모델을 고르냐, 작은 모델을 고르냐는 머신러닝의 가장 큰 챌린지 중 하나이다.
capacity를 키우게 되면 generalization이 잘 안되고, capacity를 줄이게 되면 approximation이 떨어져 training error가 훨씬 커지게 된다. (trade off)
이러한 관계를 approximation-generalization tradeoff 또는 bias-variance tradeoff라고 부른다.
-> 해결책 : 좋은 optimizationgradient descent), regularization(dropout) 이 나왔다. 그리고 뉴럴네트워크라는 capacity가 아주 큰 모델이 있고 + big data도 있으므로 optimal한 곳을 찾아낼 수 있다.

머신러닝 문제의 분류(Classification, Regression, Density Estimation)


linear regression : 회귀 모델이 선형
logistic regression : 0~1사이 확률값을 예측

Density Estimation : 비지도학습?인듯 데이터셋에 인풋데이터만 존재.
인풋데이터 x의 확률분포를 찾아내는 것이 목적. 인풋데이터에 숨어있는 패턴을 파악.
ex 클러스터링 알고리즘과 가우시안 혼합모델로 저 데이터들의 분포를 추정한 결과

저 위에 소개한 3가지가 메이저한 머신러닝 테스크이나, 저걸 기반으로 많이 발전되었다.
semantic segmentation은 픽셀 단위의 classification으로 볼 수 있고, object detection은 object localization을 한 후 classification을 진행하는 것이라고 볼 수 있다.(bbox)
저 paperswithcode에 가면 벤치마크된 데이터셋과 머신러닝 테스크, 오픈소스 코드들이 잘 정리되어 있으니 한번 봐라
학습 방법의 분류

비지도,지도학습, 강화학습 - 모델의 예측에 대해 주어지는 피드백(=reward=punishment)으로 모델을 학습
semi supervised learning - 데이터의 일부에만 레이블이 주어짐, self supervised leraning - 레이블이 주어져있지는 않지만 스스로 레이블을 생성하여 학습에 활용.

y가 유한하냐 연속적이냐에 따라 classficiation 또는 regression으로 나뉜다.
정확하게 레이블링만 되어있으면 학습이 잘 되는 게 보장되어있다.
알파고 - 프로 바둑기사들이 만든 기보데이터를 이용해 현재 바둑판 상태에서 바둑판 어디에 돌을 두면 좋을지를 학습한 supervised learning의 예. training set은 바둑판의 상태와 그 때 프로 바둑 기사가 둔 돌의 위치 페어가 된다.
그 외에도 siri, 음성비서에 활용

ex Density estimation, PCA autoencoder와 같이 차원축소를 목적으로 비지도학습을 하기도 함.
저 오른쪽 그림은 autoencoder의 예시인데 26x26 이미지를 DNN을 이용해 2차원의 feature로 축소했다가 다시 복원하는 것을 학습 -> 2차원 feature에 의미있는 정보들이 압축 되기를 기대한다.
비지도학습은 인풋데이터만의 분포를 학습하기에 분류 등의 테스크에 바로 적용하면 accuracy가 낮지만 pretraining이나 feature extraction 등에 활용될 수 있다.

어떤 observation을 에이전트가 관측했을 때 그 때 취해야 하는 액션을 직접 알려주는 것이 아니라 그 액션에 대한 리워드를 줌으로써 그 에이전트를 학습시킨다. ( 로봇, 게임플레이에 많이 사용 )
물론 액션을 직접 알려줄 수 있다면 regression의 형태가 되서 더 쉬운 방법으로 학습 시킬 수 있을 텐데 로봇의 관절을 컨트롤해야하는 것처럼 섬세한 (게임 쿠키런 등) 일일이 레이블 주기 힘든 경우
reinforecement learning은 다른 학습들과 달리 sequential 하게 decision making 문제를 푸는 게 특징.
-> 현재 취한 행동이 현재에는 큰 이득이 없지만 추후에 큰 보상으로 돌아올 수도 있고
당장의 이익만 좇았다가 더 큰 점수를 딸 수 없을 수도 있다.
실습1 Colab

실습 2 Python 튜토리얼
구글드라이브에 있음
데이터타입, int, float, True, False, type(x)
포맷팅
hw12 = '{} {} {}'.format(hello, world, 12) # hello world 12
print(hw12)string 내장함수(메쏘드?)
s = "hello"
print(s.capitalize()) # Hello
print(s.upper()) # HELLO
print(s.rjust(7)) # hello
print(s.center(7)) # hello
print(s.replace('l', '(ell)')) # he(ell)(ell)o
print(' world '.strip()) # world컨테이너 : list(=c++의 array), dictionaries, set, tuple
list - indexing 가능
a = [1,2,3]
a.append('bar')
a = [1,2,3,'bar']
a.pop()

nums = list(range(5)) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints ["0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints ["0, 1, 2, 3]"
nums[2:4] = [8, 9] # Assign a new sublist to a slice
print(nums) # Prints "[0, 1, 8, 9, 4]"
Loop 반복문
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)List Comprehension
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares)
# 조건 추가
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares)
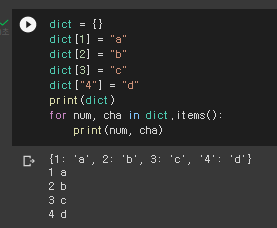
Dictionary - key, value가 있다.
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # cute
print('cat' in d) # Trueprint(d.get('monkey', 'N/A'))
# .get 메쏘드 : 해당 key의 value를 가져오거나 만약 그 key가 존재하지 않으면 N/A를 출력.
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"key와 value 삭제
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"Dictionary에서 반복문 dict.items() 이용

Dictionary Comprehension - key와 value에 comprehension 할당

Set 집합 - 순서가 없기 때문에, enumerate를 통해 loop를 돌려도 집합 print순서랑 다르게 출력이됨.
.add .remove len(set1) '어쩌구' in set1
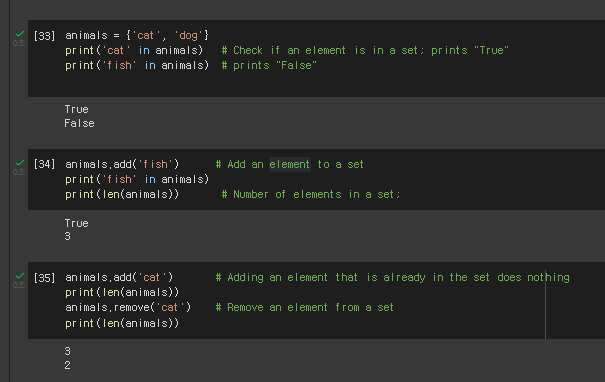
enumerate 사용해 set 반복문

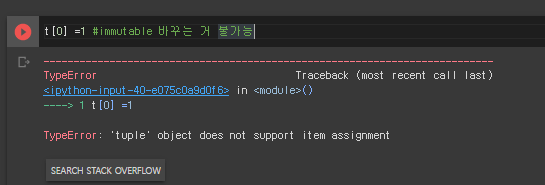
Tuple - immutable , 즉 추가나 삭제, 수정이 불가능함
if 문 - else if 대신 elif


enumerate : index와 원소를 각각 사용할 수 있는 함수인듯

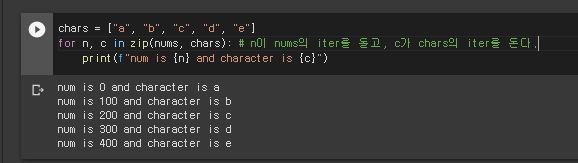
zip
Function - keyword argument, 변수가 아닌뒷쪽에 들어감. 옵션같은 느낌인듯

Class - 파이썬도 객체지향 언어기 때문에

실습 3 Numpy
numpy의 array는 모두 같은 타입의 요소로 이뤄짐. index는 tuple, 차원은 rank가 된다.
arr1.shape, type(arr1)


np.arange(처음,끝,간격)
np.zeros(행수,열수)
np.ones(행수,열수)
np.full(행수,열수) - 다 같은 수로 채움
np.eye(행수) - identity 행렬(0 1, 1 0) 대각선만 1 나머지 0인 행렬
np.random - random에 관련된 함수들
np.random.random((행렬,행렬)) - 랜덤한 수로 array를 만들어줌
np.random.randn(행렬,행렬) - 정수로
np.random.normal(평균, 표준편차, [행,열]) 인 가우시안 분포로 array를 만든다. sampling
Array indexing
슬라이싱(n차원)

a 슬라이싱해서 b만들면 b를 바꾸면 a도 바뀐다.
row 뽑기 col 뽑기
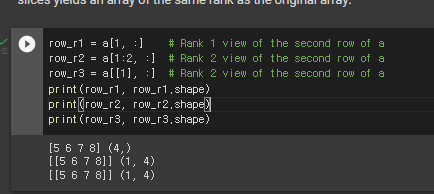


bool index

아니면 아예 바로 조건을 index로 넣어도 되는듯?

행렬 계산
np.add() np.substract() np.multiply() np.divide() np.sqrt()
np.dot() 또는 x.dot() , x@y 으로 dot product도 가능

np.sum

x.T

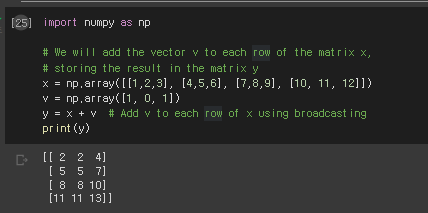
Broadcasting : shape가 다른 행렬끼리도 계산 가능
sol1 for문

sol2 tile로 해당 갯수만큼 복사하여 shape맞춰준 후 더하기

sol3 + 그냥 쓰기 numpy가 알아서 broadcasting 해서 elementwise하게 계산해준다.

matplotlib
jupyter notebook에서 할 땐 inline을 해줘야 한다.
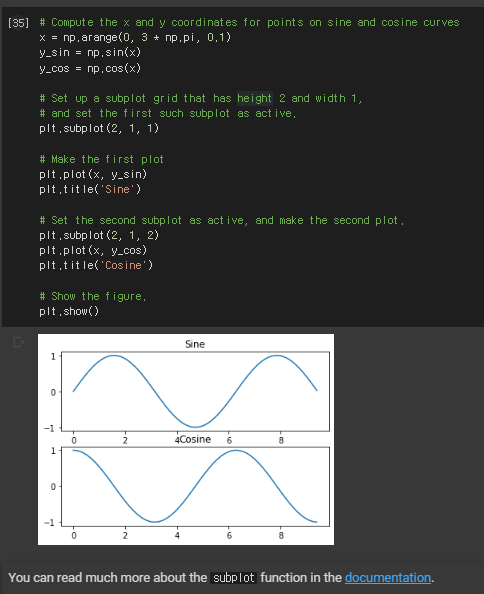
subplot
os
os.mkdir(path) os.getcwd(), os.path.exists(path)
glob 특정 디렉토리에 있는 파일 이름들을 불러옴

Linear Regression 튜토리얼
- Regression: input data x를 output data y로 매핑하는 모델 f를 찾는것.
- Linear Regression: 모델 f가 linear model, 즉 f(x)=wx+b
linear regression 연습 - 데이터셋을 읽어와서 x와 y를 np.asarray로 저장.
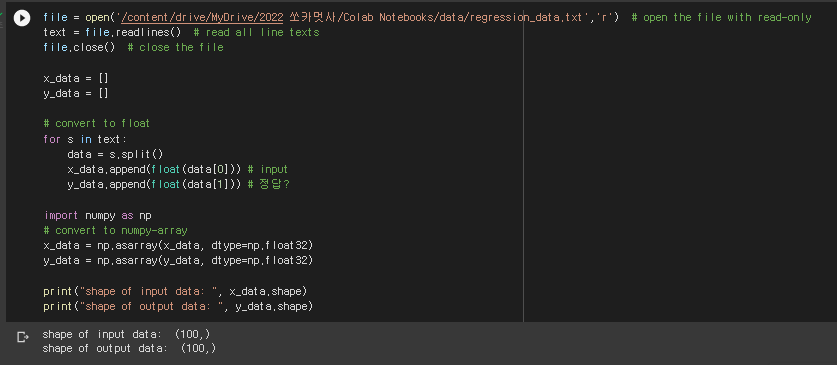
데이터셋 뜯어보기 matplotlib.pyplot의 plt.plot 이용
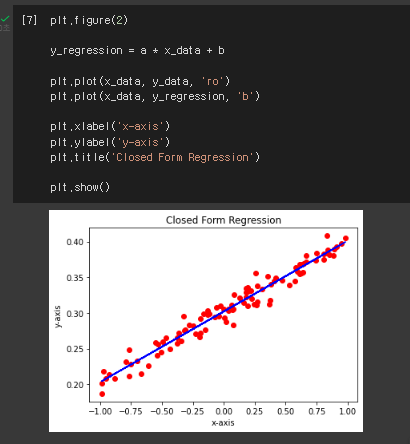
closed form regression - 식으로 해를 나타냄.

w1 은 weight, w0 는 bias
실제 정답 y와 가설(hypothesis = 회귀) 간의 오차는 L2 loss를 사용
L2 loss란 정답과 추정값의 차이를 제곱하여 전부 더한 것 = least square 방법

우리의 목표는 w* (= loss를 최소화 하는 지점의 w값) 를 찾는 것

즉 loss가 최소가 되는 w값이 궁금한 것이므로 loss함수의 접선의 기울기가 0인 곳, 즉 w1과 w0에 대해 미분했을 때 0이 될 때의 w1과 w0값을 저렇게 구할 수 있음.
이것을 Python으로 구현

그러면 loss가 가장 작은 w1,w0를 알았으니 w1x+w0로 식을 세워서 그것을 파란색으로 표시해보면 다음과 같이
문제지와 정답을 가장 잘 표현하는 식을 찾을 수 있다.
그러나 항상 이렇게 closed form solution이 존재하지 않을 경우가 많다. -> Graident Descent 사용

w+ = w - lr * (loss함수의 w에 대한 미분)
Pytorch 패키지를 이용하면 미분을 직접 할 필요 없이 Loss 정의, Gradient 계산, weight update 까지 Pytorch가 해준다.

회귀 모델, 하이퍼파라미터, loss, optimizer 까지 정의했다.

그 다음 데이터갯수와 차원을 맞게 expand 해준다.
그 다음 모델을 training 시키면서 loss를 감소시킨다.
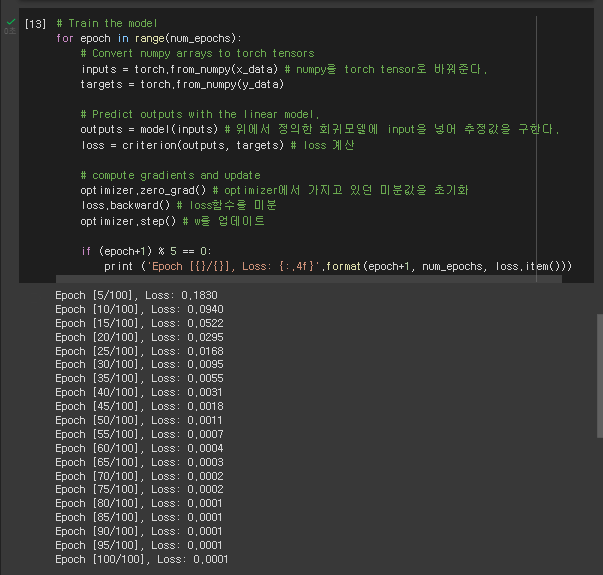
30 epoch정도만 돌아도 loss가 더이상 감소하지 않는다. 이 정도면 데이터셋에 잘 fitting 되도록 모델이 학습된 것이다.
그럼 이 모델이 얼마나 데이터셋과 잘 fitting됬는지 plot해보자.

closed solution을 사용하지 않고 gradient descent만 사용했는데도 잘 fitting됨을 알 수 있음.
숙제 : 데이터셋이 적은 경우, k fold clustering을 이용해 어떻게 데이터셋의 부분집합을 나누느냐에 따라 모델의 성능이 달라질 수 있다.
100개의 training set에서 5-fold cross validation을 한다고 치면 20개의 데이터씩 5개의 fold로 나누고, 4개의 fold로 학습시키고 1개의 fold에서 validation error를 측정하는 것을 5번 반복하여 평균 validation error를 계산합니다.
