2022. 3. 31. 19:10ㆍ카테고리 없음
Auto Encoder : input을 압축시켜 축소한 후 다시 확장하여 output을 input과 동일하게 만드는 일종의 DNN 모델
- 종류로 Stacked Auto Encoder, DAE(Denoising Auto Encoder), Variational Auto Encoder(VAE) 가 있다.
- input을 일종의 label로 삼아 학습하므로 self-supervised learning이라고 부르기도 하지만, 어쩄거나 정답라벨(y)를 이용하지 않는다는 점에서 Unsupervisesd learning이라고 한다.
Auto Encoder의 역할
- input을 압축시킴으로써 얻는 내재된(latent) 정보를 얻는다.(feature를 추출한다)
- 양이 큰 데이터를 축소시켜 전달할 수도 있다.
-> 입력 데이터의 대표적인 feature를 나타내는 파라미터를 얻어 이를 분류용 딥 뉴럴 네트워크에 사용해 더욱 더 빠른 학습과 성능 향상을 시키기 위해 사용한다.
- 노이즈를 추가하거나 제거하여 중요한 특징을 추출한다.

- MNIST의 1을 Auto Encoder에 넣은 후 output으로 input과 비슷하게 생긴 이미지 1을 출력하는 그림이다. input data인 28x28 = 784개의 뉴런을 500개, 300개, 2개로 압축시킴으로서 입력 데이터의 대표적인 feature를 추출한다.
그리고 이를 기반으로 다시 대칭구조(Symmetric)로 300개, 500개 뉴런으로 확장시킨 후 최종적으로 input과 똑같은 사이즈인 784개의 뉴런 개수로 최종 값을 출력한다.
- Auto Encoder에서 압축시키는 부분 : Encoder
- Auto Encoder에서 다시 확장시키는 부분 : Decoder
- E나 D중 하나의 파라미터를 고정시키고 나머지 부분만 학습시키는 경우도 있으나 전체적인 E-D 구조는 유지하여야 한다.
Stacked Auto Encoder : 대부분 Auto Encoder의 구조. Symmetric한 구조이다.

Denoising Auto Encoder (DAE) : 임의의 데이터인 노이즈 데이터를 제거하거나, 노이즈를 일부러 추가하여 중요한 feature를 추출하도록 하는 것.
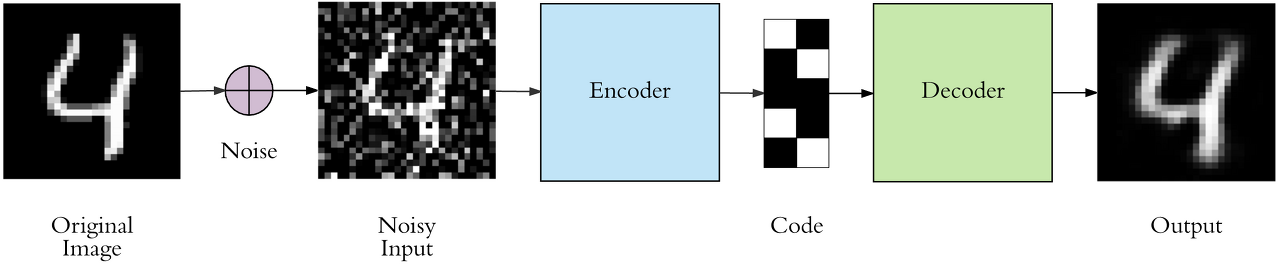
- 왜 일부러 노이즈를 첨가하느냐? trainning data는 저렇게 깔끔한 이미지겠지만, 실제 inference할 데이터는 낯설고 노이즈가 섞인 데이터일 것이기 때문이다. 즉, Overfitting을 해결하는 역할이기도 한다( = Regularization 효과)
혹여나 '더러운 데이터' 즉, 노이즈가 첨가된 데이터가 들어왔을 경우를 대비해서 모델이 스스로 잘 복구시키도록 일부러 원본 이미지에 노이즈를 첨가한 후 모델을 학습시키는 것이다.
Variational Auto Encoder (VAE) : 노이즈를 첨가하는 기능

VAE의 과정
- input 이 들어가면 그것을 압축하기 시작한다. 그리고 그 input의 대표적인 feature들을 추출한 노드들이 존재하는 층이 만들어진다. 예를 들어 이 층의 노드 수를 36개라고 하자. 이 36개 값들 중 한번 샘플링을 해서 대표 feature들의 또 대표 feature를 추출한다. 이 재추출된 대표 feature에 Gaussian 노이즈를 더해주면 임의의 노이즈가 첨가된 또 다른 대표 feature가 생성된다. 이를 기반으로 다시 확장시켜 output을 내게 된다.
이렇게 대표 feature중 한번 샘플링을 하고, 노이즈를 더한 새로운 대표 feature를 확장시켜 output을 도출하는 과정을 모델이 학습시키면서 반복한다. 결국 샘플링을 계속 반복할수록 샘플링해서 도출된 값들이 처음 압축시킨 대표 특성(처음 36개)들을 대표하는 대표값에 근사할 것이라는 가정 하에 출발하는 모델이라고도 할 수 있다.
https://techblog-history-younghunjo1.tistory.com/130
[ML] 데이터를 복구하는 Auto Encoder?
🔉해당 자료 내용은 순천향대학교 빅데이터공학과 김정현 교수님의 수업자료에 기반하였으며 수업자료의 저작권 문제로 인해 수업자료를 직접 이용하지 않고 수업자료의 내용을 참고하여 본
techblog-history-younghunjo1.tistory.com