2022. 3. 31. 18:46ㆍ카테고리 없음
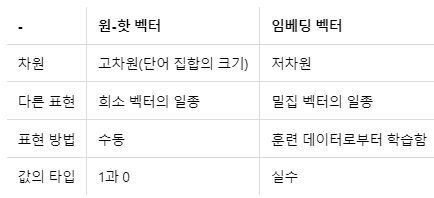
Sparse 표현(희소 표현) : one-hot encoding 과 같이 벡터 또는 행렬의 값이 대부분 0으로 표현되는 방법
- 단점은 단어의 개수가 늘어나면 벡터의 차원도 그만큼 있어야 한다. [0,0,0,0,1,0,0] 만약 단어가 1만개면 길이가 1만이 되어야 함.(즉 1만차원이 되어야 함) -> 공간적 낭비를 불러일으킨다. - 고차원
- 그리고 단어 벡터 간 유의미한 유사성을 표현하기가 힘들다.
Dense 표현(밀집 표현) : 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다. 꼭 0과 1만이 아닌 실수값을 가진다. 강아지 = [0,0,0,1,...] 기존의 one-hot encoding , 밀집 표현으로 하면? [0.2, 1.8, 1.1, -2, 2.8...] 단어가 1만개여도 길이가 꼭 1만일 필요가 없음. 128이든 사용자가 정하는 것에 따라 벡터차원을 설정할 수 있다. - 저차원 가능
Distributed 표현(분산 표현=밀집표현과 비슷한 뜻) : 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다. (강아지 - 귀엽다, 애교)
즉, 유사한 의미를 가진 단어들은 유사한 벡터값을 가진다. 분산 표현은 분포 가설(Distributional Hypothesis)를 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현한다. - 저차원. 아까 말한 Dense 표현과 동일한 개념인듯
강아지 = [0.3, 4.2, -1.1, ..]로 표현해서 꼭 텍스트의 갯수와 벡터의 차원이 동일(고차원)일 필요가 없다.
- 희소 표현: 고차원에 각 차원이 분리된 표현방법 , 분산 표현(밀집 표현) : 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현하였다. 이런 표현방법을 사용하면 단어 벡터 간 유의미한 유사도를 계산할 수 있다. 이를 위한 학습방법을 Word2Vec이라고 한다.
Word Embedding : 단어를 벡터로 Dense하게 표현하는 방법. 이 때 밀집 벡터([0.2, 1.8, 3.3, ..]) 를 임베딩 벡터(Embedding Vector)라고도 한다.
- 워드 임베딩 방법으로는 LSA, Word2Vec, FastText, Glove 등이 있다.
- 케라스에 있는 내장함수 Embedding()은 앞서 언급한 저 4가지 방법은 아니고, 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법을 사용한다.
Word2Vec : 단어 벡터 간 유의미한 유사도를 계산하기 위한 학습 방법. Word2Vec의 학습방법으로는 CBOW와 Skip Gram이 있다.
Word2Vec의 학습 방식 2가지
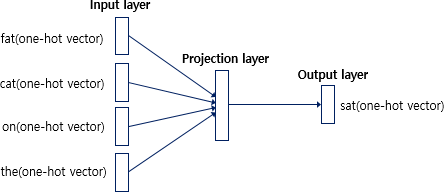
1. CBOW(Continuous Bag of Words) : 주변에 있는 단어(context word)들을 입력으로 중간에 있는 단어(center word)를 예측하는 방법
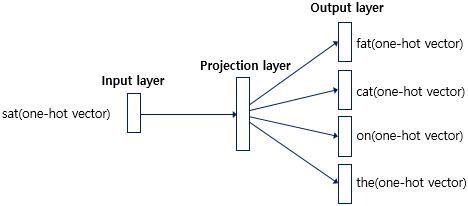
예문 : "The fat cat sat on the mat"
여기서 sat을 예측.
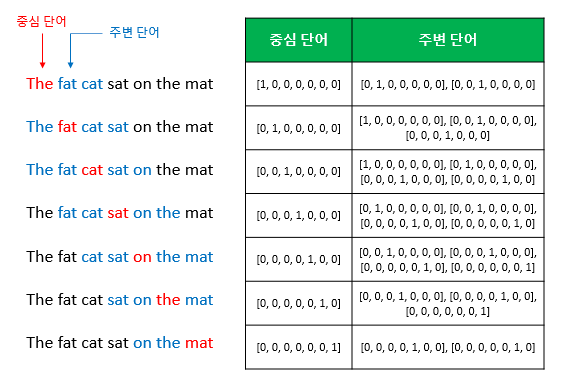
window : 중심 단어를 예측하기 위해 앞,뒤로 볼 단어의 개수. 2면 앞 뒤 단어 fat cat과 on the를 본다.
window sliding : 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터셋을 만드는 방법
CBOW의 인공신경망 도식화
2. Skip-Gram : 중간에 있는 단어(center word)들을 입력으로 주변 단어(context word)들을 예측
예문 "The fat cat sat on the mat"에 대해 윈도우 크기를 2로 잡으면 데이터셋은 다음과 같이 구성된다.
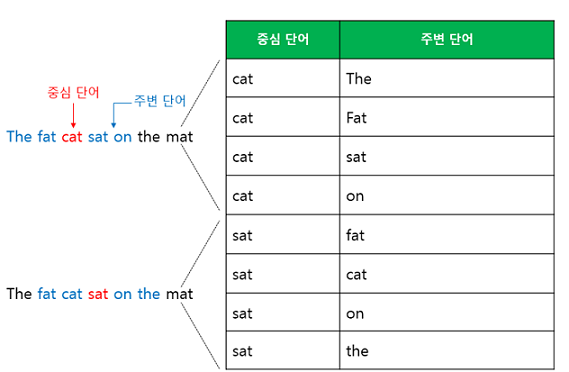
Skip-Gram 방식의 인공신경망 도식화
Keras를 이용한 Word2Vec 실습
03) 영어/한국어 Word2Vec 실습
gensim 패키지에서 제공하는 이미 구현된 Word2Vec을 사용하여 영어와 한국어 데이터를 학습합니다. ##**1. 영어 Word2Vec 만들기** 파이썬의 gen ...
wikidocs.net
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
# 모델 학습
model = Word2Vec(sentences=result, size=100, window=5, min_count=5, workers=4, sg=0)
# Word2Vec의 파라미터들
# sentences = 데이터셋 인듯
# size = 워드 벡터의 특징값, 즉 임베딩 된 벡터의 차원
# window = 앞 뒤로 몇 단어를 볼 건지?
# min_count = 단어 최소 빈도 수 제한
# workers = 학습을 위한 프로세스 수
# sg = 0이면 CBOW, 1이면 Skip-Gram
# Word2Vec.wv.most_similar 함수 - 입력한 단어에 대해 가장 유사한 단어들을 출력.
model_result = model.wv.most_similar('man')
print(model_result)
### 유사한 단어들 결과
# [('woman', 0.842622697353363), ('guy', 0.8178728818893433), ('boy', 0.7774451375007629), ('lady', 0.7767927646636963),
# ('girl', 0.7583760023117065), ('gentleman', 0.7437191009521484), ('soldier', 0.7413754463195801), ('poet', 0.7060446739196777), ('kid', 0.6925194263458252), ('friend', 0.6572611331939697)]
### man과 유사한 단어로 woman, guy, boy, lady, girl, gentleman 등이 출력되었다.
# 모델 저장
model.wv.save_word2vec_format('eng_w2v')
# 모델 load
loaded_model = KeyedVectors.load_word2vec_format('eng_w2v')