2022. 3. 30. 21:39ㆍ카테고리 없음
기울기 소실 Gradient Vanishing : 레이어가 많은 깊은 인공신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 미분값 = 기울기(Gradient)가 점점 작아지는 현상
- 입력층에 가까운 층들에게 weight update가 제대로 이루어지지 않으면 최적의 모델(global loss minimum인 weight 찾기)에 실패할 수 있다.
기울기 폭주 Gradient Exploding : 미분값 = 기울기가 점차 커지더니 가중치들이 비정상적으로 큰 값이 되면서 결국 발산해버리는 것. RNN에서 쉽게 발생한다.
1. ReLU와 ReLU의 변형
시그모이드 함수를 사용하면 입력에 따라 출력값이 0 또는 1에 수렴하면서 기울기가 0에 가까워진다. 따라서 역전파 과정에서 입력층 방향으로 갈 수록 제대로 역전파가 되지 않는다. (기울기 소실이 발생함)
기울기 소실 완화 방법
- 은닉층에서 tanh나 sigmoid를 activation function으로 사용하지 말아라.
- Leaky ReLu를 사용하면 기울기가 0에 수렴하지 않아 죽은 ReLU 문제를 해결한다
- 은닉층에서는 ReLU나 Leaky ReLU와 같은 activation function을 사용해라.
2. Gradient Clipping
Gradient Clipping : 기울기 값을 자르는 것. 기울기 폭주를 막기 위해 임계값을 넘지 않도록 값을 자른다. 임계치만큼 크기를 감소시킨다.
3. Weight Initialization
Weight Initialization : 가중치 초기화
- 초기에 가중치를 뭐로 하느냐 (w0)에 따라 모델의 훈련결과가 달라지기도 한다. 그러므로 가중치 초기화를 적절히 해준다.
1) Xavier Initialization 세이비어 초기화 = 글로럿 초기화
- 여러 층의 기울기 분산 사이에 균형을 맞춰서 특정 층이 너무 주목을 받거나 다른 층이 뒤쳐지는 것을 막는다.
- sigmoid나 tanh처럼 S자형인 함수와 사용하면 효과적이다. (ReLU랑은 X)
- 이전 층의 뉴런 개수 nin, 다음 층의 뉴런개수 nout이 있을 때 다음과 같은 분포를 사용하여 가중치를 초기화 한다.
- 균등분포
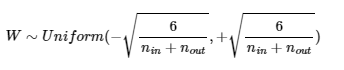
- 정규분포로 초기화할 떄는 평균 0, 표준편차는 다음과 같이 하여 초기화한다.
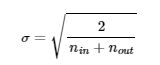
2) He Initialization
- ReLU와 사용할 때 효과적이다. 대부분 ReLU를 많이 사용하므로 He 초기화가 보편적이다.
- 이전 층의 뉴런 개수 nin만 가지고 초기화한다.
- 균등분포

- 정규분포
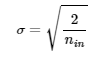
4. Batch Normalization
- ReLU + He initialization으로 어느 정도 기울기 소실/폭주를 완화할 수 있지만, 언제든 발생할 수 있는 문제이다.
Batch Normalization : 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 학습을 효율적으로 만들어준다. 즉, 한 번에 들어오는 batch 단위로 정규화 하는 것. 평균을 0으로 만들고 정규화를 한다. 그리고 정규화 된 데이터에 대해 scail(매개변수 사용)과 shift(매개변수 B 베타 사용)를 수행한다.
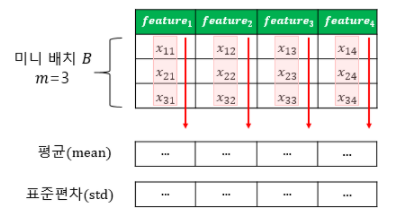
Mini Batch : 동일한 feature 갯수를 가진 다수의 sample(x)들
- training 시 배치 단위의 평균과 분산들을 차례대로 받아 이동 평균과 이동 분산을 저장해놓았다가, test 할 때 구해놓았던 평균과 분산으로 정규화를 한다.
Batch 정규화의 장점과 단점
- 배치정규화를 사용하면 sigmoid나 tanh를 사용하더라도 기울기 소실 문제가 크게 개선된다.
- weight initialization에 훨씬 덜 민감해진다
- 큰 lr을 사용할 수 있다 (=학습 속도가 빨라진다)
- 미니 배치마다 평균과 표준편차를 계산하여 사용하므로 훈련 데이터에 약간의 noise를 넣는 부수 효과로 과적합을 방지하는 효과도 있다. (= Drop out과 비슷한 효과를 낸다)
- 배치 정규화는 모델을 복잡하게하고, 추가 계산을 하는 것이기에 inference 시에 실행 시간이 느려진다. 따라서 서비스 속도를 고려하려면 배치 정규화를 할지 말지 고민해야한다.
1) Internal Covariate Shift (내부 공변량 변화)
내부 공변량 변화 : 학습 과정에서 층 별로 입력 데이터 분포가 달라지는 현상.
- 이전 층들의 학습에 의해 이전 층의 가중치 값이 바뀌게 되면, 현재 층에 전달되는 입력 데이터의 분포가 현재 층이 학습했던 시점의 분포와 달라진다.
- 공변량 변화 : training 데이터의 분포와 test 데이터의 분포가 다른 경우
- 내부 공변량 변화 : 신경망 층 사이에서 발생하는 입력데이터의 분포 변화
2) Batch Normalization의 구체적 수식

m = 미니 배치에 있는 sample 수
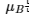
= 미니 배치 B에 대한 평균
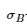
= 미니 배치 B에 대한 표준편차
x^(i) = 평균이 0이고 정규화 된 입력데이터

= 분산이 0일때, 분모가 0이 되는 것을 막는 작은 양수. 보통 10^-5 사용
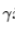
= 정규화 된 데이터에 대핸 scail 매개변수
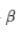
= 정규화 된 데이터에 대한 shift 매개변수
y(i) = batch normalization의 최종 결과
3) 배치 정규화의 한계 2가지
- 미니 배치 크기에 의존적이다.
너무 작은 배치에서는 잘 동작하지 않는다. 극단적으로 배치 크기를 1로 하게 되면 분산은 0이다. 작은 미니 배치에서는 배치 정규화의 효과가 극단적으로 작용하게 되어 훈련에 악영향을 줄 수 있다. 너무 작은 미니배치보다는 크기가 어느정도 있는 미니배치에서 해야한다.
- RNN에 적용하기 어렵다.
RNN은 각 시점(time step)마다 다른 통계치를 가진다. 이것때문에 배치 정규화를 RNN에 적용하기 어렵다. 따라서 RNN의 경우에는 Batch 정규화가 아닌 Layer 정규화 = 층 정규화를 사용한다.
5. Layer Normalization(층 정규화)
