2022. 3. 30. 20:37ㆍ카테고리 없음
training dataset에만 모델이 과적합되는 현상은 모델의 성능을 떨어트리는 주요 이슈이다.
train data에 대한 정확도는 높을지라도, 실제 데이터(처음보는 데이터- val data, test data)에 대해서는 정확도가 떨어질 수 있다.
이는 모델이 training data를 불필요할정도로 과하게 암기하여 training data에 포함된 노이즈까지 학습한 상태라고 해석할 수 있다.
그럼 지금부터 딥러닝(DNN)의 Overfitting을 막는 방법에 대해 알아보자.
1. 데이터 양 늘리기
- 데이터 양이 적을 경우, 모델은 해당 데이터의 특정 패턴이나 노이즈까지 쉽게 암기하게 되므로 과적합 현상이 발생할 확률이 늘어난다. 그러므로 데이터 양 ↑ 이면 데이터의 일반적인 패턴을 잘 파악함(Hypothesis) 따라서 과적합할 확률 ↓
- 데이터 증강 (Data Augmentation) : 데이터셋 자체가 작은 경우 의도적으로 기존의 데이터를 조금씩 변형하고 추가하여 데이터 양을 늘리는 것.
이미지의 경우 flip, rotate, grayscale,노이즈추가, 일부분 가리기 등 데이터의 양을 늘림.
텍스트의 경우 Back Translation(역번역) - 번역 후 재번역
2. 모델의 복잡도 줄이기
모델의 복잡도 : hidden layer의 수, 매개변수의 수=Capacity 등으로 결정됨.
복잡한 모델이 간단한 모델보다 과적합 될 가능성이 높다. (매개변수 수 ↑ 과적합할 가능성 ↑)
3. 가중치 규제(Regularization) 적용하기
- L1 규제 : 가중치 w들의 절대값 합계를 loss function에 추가한다.
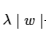
를 더한 값을 loss function에 추가,
- L2 규제 : 모든 가중치 w들의 제곱합을 loss function에 추가한다.
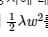
를 더한 값을 loss function에 추가,
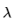
: 규제의 강도를 정하는 하이퍼파라미터로, 큰 값을 주면 training data에 대해 적합한 매개변수를 찾는 것보다 규제를 위해 추가된 항들을 작게 유지하는 걸 우선한다는 의미가 된다.
w가 최소가 되어야 loss function을 최소화하게되는 특징이 있다. 따라서 가중치 w의 값들은 0 또는 0에 가까이 작은 값이어야 하므로 어떤 feature(x)는 모델을 만들 때 거의 사용되지 않게 된다.
예를 들어 H(x) = w1x1+w2x2+w3x3+w4x4라는 수식이 있을 때 L1규제를 사용하였더니 w3가 0이 되면, x3 feature는 모델의 결과에 별 영향을 주지 못하는 특성임을 의미한다.
L2 규제는 w가 완전히 0이 되기보다는 0에 가까워지는 경향을 띤다. L2 규제 = 가중치 감쇠(weight decay)
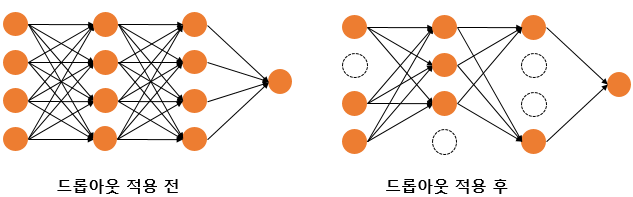
4. Dropout
Dropout : 학습 과정에서 신경망의 일부를 일부러 사용하지 않는 방법이다. 예를 들어 드롭아웃의 비율을 0.5라고 한다면 학습 과정마다 랜덤으로 절반의 뉴런을 사용하지 않고, 나머지 절반만을 사용한다.
- 드롭아웃은 학습(training) 시에만 사용하고 inference(=predict)할 때는 사용하지 않는다.
- 학습 시에 인공신경망이 특정 뉴런 또는 특정 조합에 너무 의존하는 것을 방지
- 매번 랜덤으로 학습에 사용할 뉴런을 선택하므로 서로 다른 신경망들을 앙상블하여 사용하는 것과 같은 효과를 내어 과적합을 방지할 수 있다.
케라스에서 드롭아웃 사용 방법
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense
max_words = 10000
num_classes = 46
model = Sequential()
model.add(Dense(256, input_shape=(max_words,), activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(num_classes, activation='softmax'))