2022. 3. 24. 18:52ㆍ카테고리 없음
과적합(Overfitting) : training dataset만 과하게 학습한 상태. epoch가 지나치게 많으면 발생할 수 있다. training data에 대해서는 오차가 낮지만, test data에 대해서는 오차가 높다. 과적합이 생기지 않고 loss가 제일 낮은 최적의 epoch를 찾아야 한다. test data의 오차가 증가하기 전이나, 정확도가 감소하기 전에 훈련을 멈추는 것이 좋다.
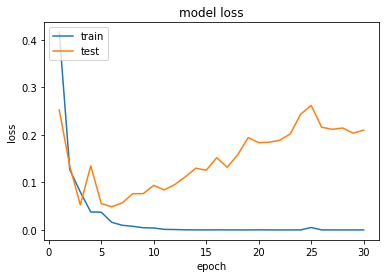
과소적합(Underfitting) : test data의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태. epoch가 너무 적으면 발생할 수 있다. test data에 대한 정확도도 낮고, train data에 대한 정확도도 낮다.
+ 여기서 fitting이라는 표현을 쓰는 이유는, 머신러닝에서 learning = train (학습 = 훈련) 이라고 하는 과정을 fitting이라고 부르기도 하기 때문이다. 모델이 주어진 데이터(input과 정답)에 대해 적합해져가는 과정이기 떄문이다. (케라스에서도 fit()이라는 이름의 함수가 존재함.)
- 이런 overfitting을 관찰하기 위해 이전 포스팅에서도 다뤘던 val dataset과 test dataset을 나누는 이유도 있음.
val dataset : 과적합(overfitting) 모니터링과 hyperparameter tuning
test dataset : 최종 성능 평가.
- 과적합 방지를 고려한 일반적인 딥러닝 모델의 학습 과정은 다음과 같다.
step 1. 주어진 데이터를 train : val : test = 8:1:1 또는 6:2:2로 분리
step 2. training data로 모델을 학습(epoch = epoch +1)
step 3. val data로 모델을 평가하여 val data에 대한 정확도와 오차 계산
step 4. train data 오차는 감소하는데 val data의 오차가 증가하면 과적합 징후이므로 학습 종료, step 5로 이동
아니라면 step 2로 재이동
step 5. 모델의 학습이 종료되었으니 test data로 모델을 평가.
- 과적합을 방지하기 위한 방법
1. Dropout
2. Early Stopping