2022. 3. 22. 22:08ㆍ카테고리 없음
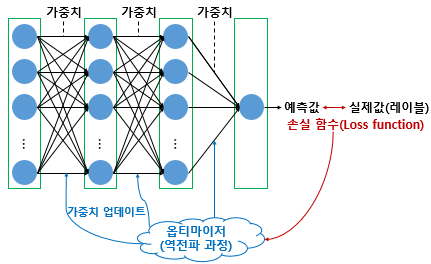
딥러닝의 학습과정에서는 loss function , optimizer, epoch의 개념이 쓰인다.
- loss function(손실함수) : loss = f(w,b) = pred - 실제정답 을 수치화하는 함수. ex) 회귀 - MSE, 분류 - cross entropy
loss function의 종류
1. MSE(Mean Squared Error)
model.compile(optimizer='adam', loss='mse', metrics=['mse'])2. Binary Cross Entropy
출력층에서 sigmoid를 사용하는 Binary Classification의 경우 사용하는 손실함수.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
3. Categorical Cross Entropy
출력층에서 softmax를 사용하는 Multi Classification의 경우 사용하는 손실함수.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
- Optimizer(최적화알고리즘) : cost = loss가 최저가 되도록 하는 W와 b를 찾아내는 알고리즘
- Batch : 가중치 등 매개변수의 값을 조정하기 위해 사용하는 단위데이터의 양. 한 뭉텅이의 데이터
- Epoch : 전체 데이터에 대한 한 번의 훈련횟수. 전체 데이터를 한번 돈 것.
Batch size에 따른 Gradient Descent(Optimizer 중 하나) 방법들
1. 배치 경사 하강법(Batch Gradient Descent)
가장 기본적인 경사 하강법, loss를 구할 때 전체 데이터를 고려한다. 1 epoch에 모든 매개변수 업데이트를 단 한번 수행한다. 시간이 오래 걸리고 메모리를 크게 요구함.
model.fit(X_train, y_train, batch_size=len(X_train))2. 배치 크기가 1인 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
전체 데이터가 아닌 랜덤으로 선택한 한 데이터에 대해서만 계산하여 매개변수 업데이트를 수행하는 경사 하강법
model.fit(X_train, y_train, batch_size=1)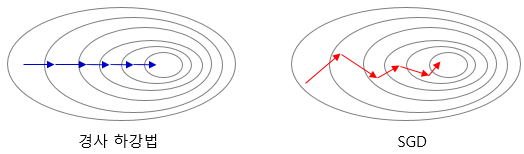
3. 미니 배치 경사 하강법(Mini Batch Gradient Descent)
- 전체 데이터도, 1개의 데이터도 아닌 배치 크기를 지정하여 해당 데이터 개수만큼에 대해서만 계산하여 매개변수 업데이트를 수행하는 경사 하강법.
- 가장 많이 사용하는 경사하강법. 배치 경사 하강법(Batch Gradient Descent)보단 빠르고, SGD보단 안정적이라는 장점.
model.fit(X_train, y_train, batch_size=128)- batch size는 2의 n제곱으로 설정한다. default는 32(2의5승)이다.
Optimizer의 종류(최적화 알고리즘 자체에 대한 종류, Gradient Descent를 조금씩 달리한 다양한 옵티마이저들.)
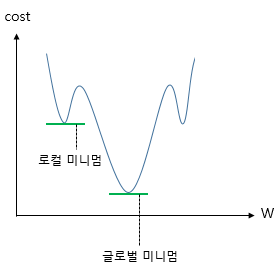
1. Momentum
- Gradient Descent에서 계산된 접선의 기울기에 한 시점 전의 접선의 기울기값을 일정한 비율만큼 반영한다.
- 관성을 이용하게 된다. local minimum에 빠지더라도 관성의 힘으로 탈출할 수 있는 효과를 줄 수 있다.
tf.keras.optimizers.SGD(lr=0.01, momentum=0.9)
2. Adagrad
- 모든 매개변수에 동일한 lr을 적용하는 것은 비효율적이기 때문에, 각 매개변수에 서로 다른 lr(학습률)을 적용시키는 것이다.
- 변화가 많은 매개변수는 lr을 작게, 변화가 적은 매개변수는 lr을 높게 설정한다.
- 나중에 가서는 lr이 지나치게 떨어진다는 단점이 있다.
tf.keras.optimizers.Adagrad(lr=0.01, epsilon=1e-6)
3. RMSprop
- Adagrad의 단점인 나중의 lr이 지나치게 떨어지는 것을 보완한 옵티마이저이다.
tf.keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
4. Adam
- Momentum + RMSprop, 즉 방향과 lr 두 가지를 모두 잡는 옵티마이저.
tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
keras에서의 사용방법
optimizer 인스턴스는 compile의 optimizer에서 호출한다.
#1
adam = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['acc'])
#2 또는 이렇게
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])