2022. 3. 21. 17:19ㆍ카테고리 없음
퍼셉트론(Perceptron) : 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘. 일정치 이상의 크기를 가지면 신호를 전달한다.
활성화함수 Activation Function : 퍼셉트론에서 hidden layer과 output layer의 뉴런에서 출력값을 결정(일정치 이상이면 어떤 값으로 내보내겠다)하는 함수 f(x).
- ex. f(x) = step function , sigmoid function, tanh, ReLU, softmax

- 활성화함수의 특징 : 비선형 함수(Nonlinear function)이다.
f(x) = wx+b이면 안된다. 왜냐하면 hidden layer를 여러개 계속 쌓을 수 없다. 만약 활성화함수가 선형함수이면 f(x) = wx+b 이고, hidden layer를 여러개 쌓았다고 치자. 그러면 출력 y = f(f(f(x))) = w*w*w(x)이므로 결국 또 kx로 표현이 가능하다. 즉, hidden layer를 여러개 쌓아도 1층만 있는 것과 동일해진다. 그래서 활성화함수는 비선형이어야 하고, 일정치 이상이면 어떤 값으로 내보내야 한다.
그러나 종종 활성화 함수를 사용하지 않는(=선형 함수를 사용한 층) 층을 쓰기도 한다. 이는 선형층(linear layer)나 투사층(projection layer)등 다른 표현으로 사용한다. 임베딩 층(embedding layer)도 선형층이다. (임베딩 층은 활성화함수가 존재하지 않는다.) 정리하자면
- layer
1. 선형층 - 활성화함수(비선형함수)를 사용하지 않는 층. ex) embedding layer
2. 비선형층 - 활성화함수(비선형함수)를 사용한 층. ex) 일반적인 hidden layer
- 활성화함수의 종류 : 주로 쓰이는 다섯가지를 알아보자. step function , sigmoid function, tanh, ReLU, softmax
1. Step function 계단 함수

퍼셉트론에서는 거의 사용되지 않지만 간단해서 처음 배울 때 익히는 함수
2. Sigmoid function 시그모이드 함수 와 기울기 소실문제
- hidden layer에서의 사용은 지양하고, 주로 이진 분류를 위해 출력층에서 사용된다.


인공신경망의 학습 과정을 잠시 알아보자.
step 1. 입력에 대해 순전파(forward propagation)연산을 하고, forward propagation 연산을 통해 나온 pred 값과 실제 정답의 오차 loss를 loss function을 통해 계산한다.
step 2. loss function을 w에 대해 미분해서 기울기(gradient)를 구하고, back propagation를 통해 다시 출력층에서 입력층 방향으로 w와 b를 업데이트 한다.
여기서 sigmoid함수의 경우 미분 과정에서 기울기 소실 문제가 발생한다.
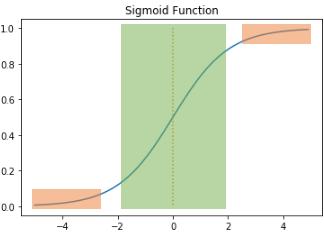
왜냐하면 sigmoid함수는 sigmoid 함수의 출력값이 0 또는 1에 가까우면(주황색 부분) 그래프의 기울기가 0에 가까워진다. 즉, 미분하면 그 미분계수=접선의기울기 가 0에 가까운 값 0.001 등일 것이다. 또한 초록색 부분도 기울기가 최대 0.25이다.
만약 sigmoid 함수를 활성화 함수로 하는 인공신경망의 층을 쌓는다면, w와 b를 업데이트 하는 과정인 back propagation 과정에서 0에 가까운 값(기울기)이 누적해서 곱해지게 되면서 앞단(입력층쪽)에는 기울기(미분계수)가 잘 전달되지 않게 된다.

Vanishing Gradient : back propagation 과정에서 0에 가까운 값(기울기)이 누적해서 곱해지게 되면서 앞단(입력층쪽)에는 gradient = 기울기(미분계수)가 잘 전달되지 않는 문제. 즉, w가 업데이트되지 못해 모델 학습이 이루어지지 않는다.
따라서 sigmoid함수는 여러 층을 쌓아야 하는 hidden layer에서의 사용은 지양한다.
3. Hyperbolic tangent function (tanh) 하이퍼볼릭탄젠트 함수

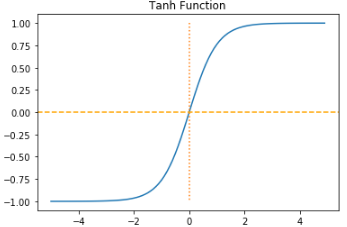
- 입력값을 -1~1사이 값으로 변환한다.
tanh 함수도 기울기(미분계수)가 크지 않아서 기울기소실 문제 때문에 은닉층(hidden layer)에서 잘 사용되지 않는 것이 좋겠다고 생각할 수도 있지만, tanh는 sigmoid와 달리 0을 중심으로 하고 있고, 미분하면 0.25보다는 큰 값이라 sigmoid보다는 기울기 소실 문제가 적기 때문에 hidden layer에서 사용되긴 한다.
4. ReLU function
- hidden layer에서 가장 선호되는 함수.


- 0 이하의 x에 대해선 y=0, 0 이상의 x에 대해선 y=x, 즉 0 이상의 입력값의 경우에는 미분값이 항상 1이다.(0.25보다 훨씬 크다) 따라서 hidden layer에서 여러 층에 적용하여도 기울기가 사라지지 않는다.
- sigmoid나 tanh처럼 어떤 연산이 필요한 것이 아니라 단순 임계값이므로 연산속도도 빠르다.
- 그러나 Dying ReLU 문제 : 입력값이 음수면 미분값이 0이어서 뉴런을 다시 회생시키는 것이 매우 어렵다.
5. Leaky ReLU function
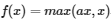
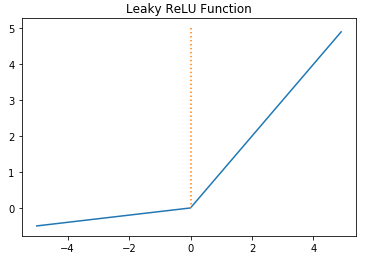
- 죽은 ReLU(Dying ReLU)를 보완하기 위한 ReLU의 변형된 버전.
- 0 이하의 x에 대해서는 매우 작은 기울기 a를 가진 y=ax, 0 이상의 x에 대해서는 y=x.
따라서 입력값 x가 음수여도 기울기가 0이 되지 않아 뉴런이 죽지 않는다.
6. Softmax function
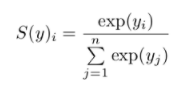





- hidden layer에서는 ReLU 또는 변형된 ReLU를 사용하는 것이 일반적이고, Softmax는 sigmoid와 같이 출력층에서 주로 사용된다.
sigmoid : Binary classification (이진분류)
softmax : Multiclass classification(다중 클래스 분류) 에 사용.
즉, 딥러닝으로 이진 분류를 할 떄는 로지스틱회귀(sigmoid)를 사용, 다중 클래스 분류를 할 때는 softmax 사용.