2022. 3. 19. 22:00ㆍ카테고리 없음
머신러닝 중 대부분인 지도학습 : 기계(컴퓨터)에게 input과 그것의 정답 y를 준다(training dataset)
그리고 그 dataset을 가장 잘 표현하는 직선(또는 비선형모델)을 만드는 W,b를 찾도록 컴퓨터를 학습시킨다.
Regression : 어떤 입력을 주면 특정 값을 출력(예측=inference) 해내는 것.
Linear regression : data를 가장 잘 표현하는 모델 H(x)로 직선을 사용하는 regression. 어떤 입력을 주면 특정 값을 출력(예측=inference) 해낸다. H(x) = Wx + b. 이 떄 x는 input(이미지, 단어 등)
Nonlinear regression : data를 가장 잘 표현하는 모델 H(x)로 비선형모델(구불구불한 선)을 사용하는 regression. 어떤 입력을 주면 특정 값을 출력(예측=inference) 해낸다. H(x) = x^3 어쩌구저쩌구
Cost = Loss : 기계의 예측값 - 실제정답. 기계가 모델 H(x)를 통해 예측한 값(기계가 생각했을 때 낸 답) - 실제정답. H(x) - y
Cost function = Loss function : 예측값 - 실제정답( = H(x) -y) 에 조금 더 정교한 계산방법을 추가한 함수. 변수로는 W와 b를 사용한다. cost = f(W,b)로 표현된다. 그래프를 그리면 x축은 w값, y축은 cost가 된다.
(ex. 많이 쓰이는 cost function으로 유명한 오차제곱평균이 있다. (H(x) - y)^2 / 데이터갯수)
우리가 해야될 것 : cost = loss = H(x) - y가 최저가 되도록(= 가장 데이터를 잘 표현하도록) 하는 W와 b값을 찾아내는 것 = 최적의 W(와 b)를 찾아내는 것. w는 cost function의 변수이다.
Optimizer = 최적화 알고리즘 : cost = loss가 최저가 되도록 하는 W와 b를 찾아내는 알고리즘

Gradient Descent : 모든 경우(local이 아닌 global)에서 이 loss = f(w)가 최저가 되는 지점(global minimum)과, 그 때의 w를 찾는 방법. w = w0 - 미분계수값*lr (w0 = 이전 w값). 가장 유명하고 기본적인 optimizer
미분계수 : cost(w)를 w에 대해서 미분한 것 = 접선의 기울기 = 순간변화율
- 미분계수(접선의 기울기)가 양수라면 w를 줄여야하고, 미분계수(접선의 기울기)가 음수라면 w를 늘려야한다.
+ Gradient Descent에서 한가지 이슈는 가장 낮은 지점인줄 알았는데 local minimum에 빠져버릴 수도 있다는 점이다. 따라서 local minimum = global minimum인 아름다운 함수 convex function로 cost function을 만들어야한다.

Learning rate : lr 최적의 loss 지점을 찾아가기 위해 미분계수를 구할 다음 w값을 정할 때 미분계수에 곱해주는 하이퍼파라미터. 보통 0<lr<1이다.
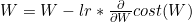
Learning rate를 적절히 지정해야하는 이유 : lr이 너무 크면 w값이 너무 왔다갔다 해서 global minimum에 수렴하지 못하고 오히려 발산할 수 있음. 혹은 lr이 너무 작으면 w값이 너무 조금조금씩 변해서 global minimum에 수렴하기까지 너무 오래 걸린다.

정리하자면 Hypothesis, Cost function, Optimizer는 머신 러닝 분야에서 사용되는 포괄적 개념이다. 풀고자하는 각 문제에 따라 Hypothesis, Cost function, Optimizer는 전부 다를 수 있으며 선형 회귀에 가장 적합한 Cost(=Loss) function와 Optimizer가 알려져있는데 MSE와 Gradient Descent가 각각 이에 해당됩니다.
+ 우리의 음식 탐지 모델 프로젝트의 경우 pretrained된 모델을 가져와서 학습시켰는데 그 모델이 pretrained 될 당시 사용한 training 데이터셋(COCO dataset) 에 비해 우리가 사용할 커스텀 training 데이터셋의 사이즈가 약 1/10으로 작아서 lr또한 1/10으로 설정해주었다. 왜냐하면
데이터셋 이미지갯수가 10배 많음 -> w 와리가리하는 횟수가 더 많음 -> 같은 w 와리가리 폭이어도 데이터셋 이미지갯수가 10배 적으면 반복횟수(라기보다는 배울기회)가 더 적음 -> 같은 w 와리가리 폭이어도 충분히 배우지 못하고 발산할 수 있음. 그러니 안전하게 lr을 데이터셋이 줄어든 비율만큼 작게 준다. -> lr이 작으면 생기는 문제인 너무 느린 시간도 데이터셋이 그만큼 작기때문에 충분히 이해할만함.
-> 코치님꼐 질문 - 관련 논문이 있는지?