2022. 2. 23. 15:08ㆍ프로젝트/KFood
https://github.com/ultralytics/yolov3
GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
YOLOv3 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov3 development by creating an account on GitHub.
github.com
YOLOv3🚀는 COCO 데이터 세트에서 사전 훈련된 Object Detection 아키텍처 및 모델 제품군이며 미래 비전 AI 방법에 대한 Ultralytics 오픈 소스 연구를 나타내며 수천 시간의 연구 및 개발을 통해 학습한 교훈과 모범 사례를 통합합니다.
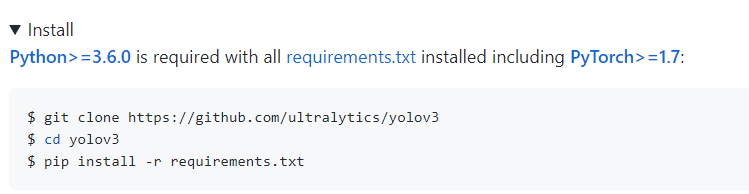

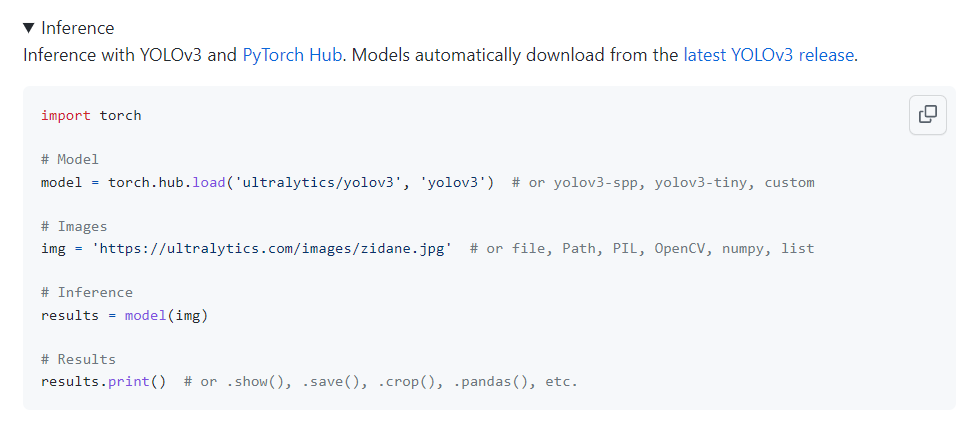


이건 내가 파이썬파일 따로 만들어서 inference 하는 것 같고 아래 방법으로 해본다.


내가 detection에 넣을 사진

python detect.py --weights yolov3.pt --source data/images/추론할이미지.jpg
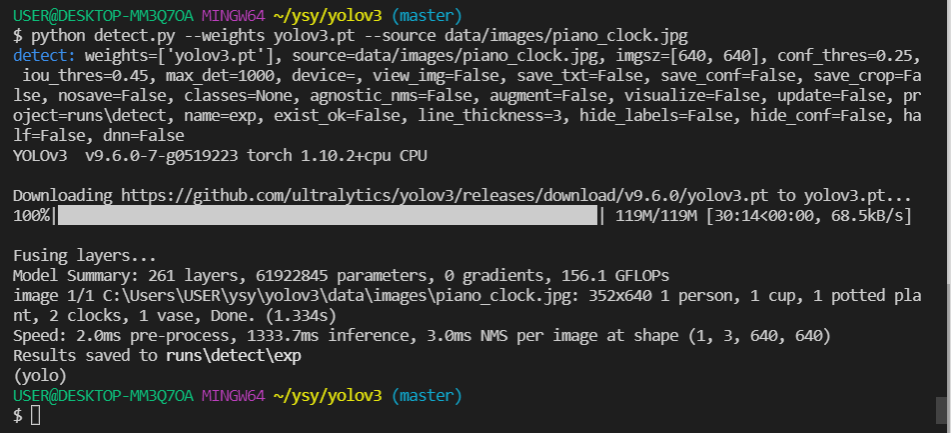
오 inference가 끝났다.
오 runs/detect/exp 파일이 생겼다!
결과는??!

오.. 화분, 시계, 사람을 찾아냈다! 나는 저 액자속 사람들이랑 선풍기도 잡아낼 줄 알았는데.. 그건 아니었다 ㅋㅋ
이번엔 식사 속 식기들,그릇들도 잡는지 아래 사진을 넣어보았다


오 모델을 한번 다운받아놓으니까 그 다음은 금방 된다.
결과는?
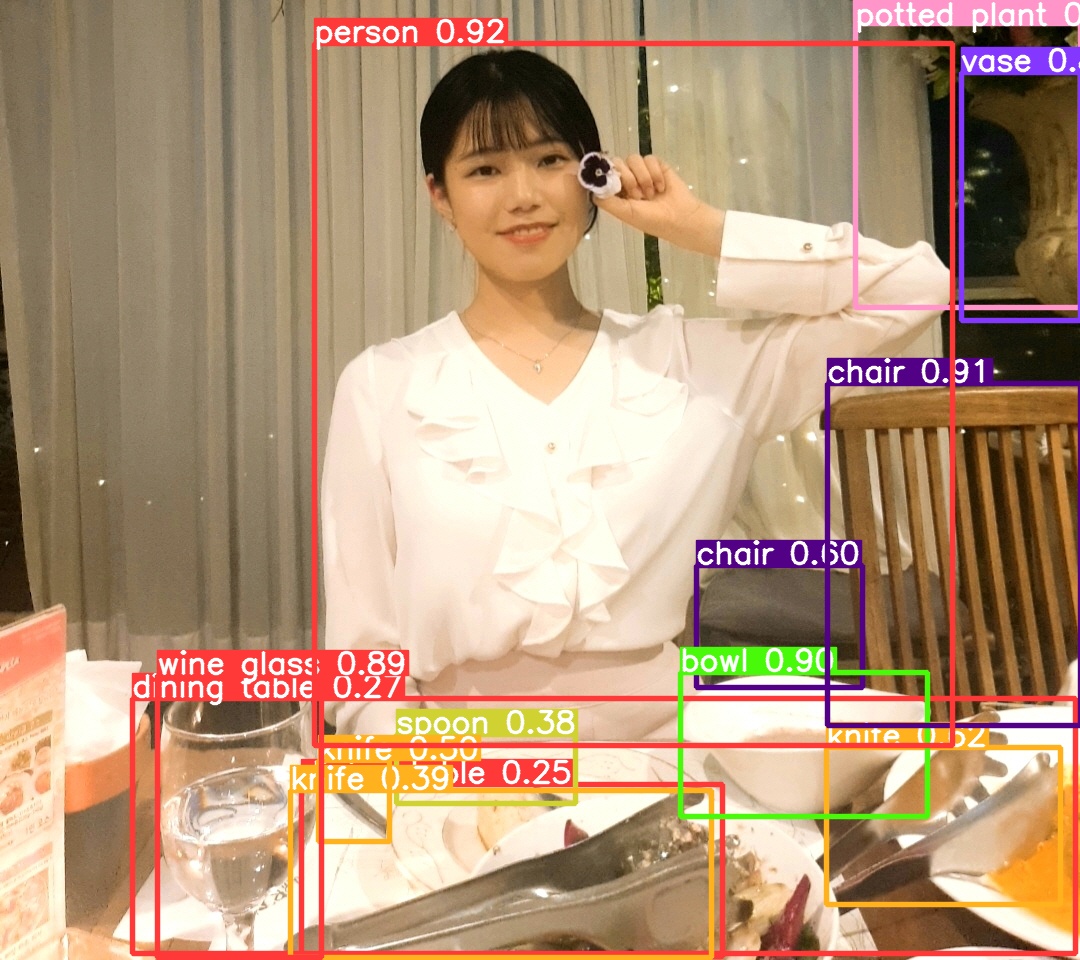
오 와인잔,나이프,bowl, 의자 등 잘 잡는 모습이다.
동영상도 한번 넣어보자 ㅋㅋ 추억의 영상들.. 레몬 먹는 영상을 넣어보았다.
python detect.py --weights yolov3.pt --source data/images/seoyoon_lemon.mp4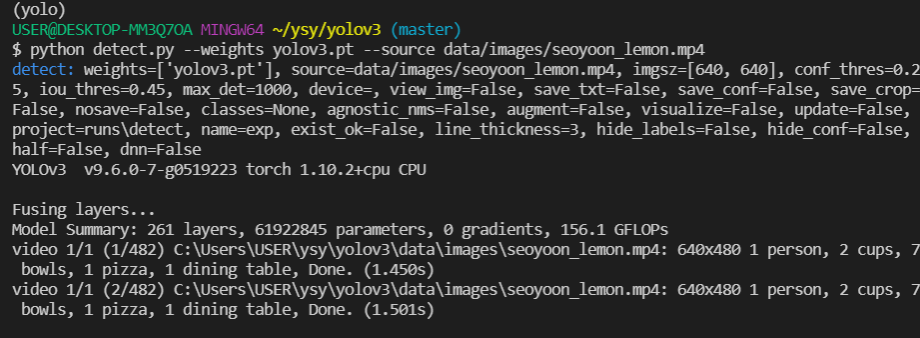
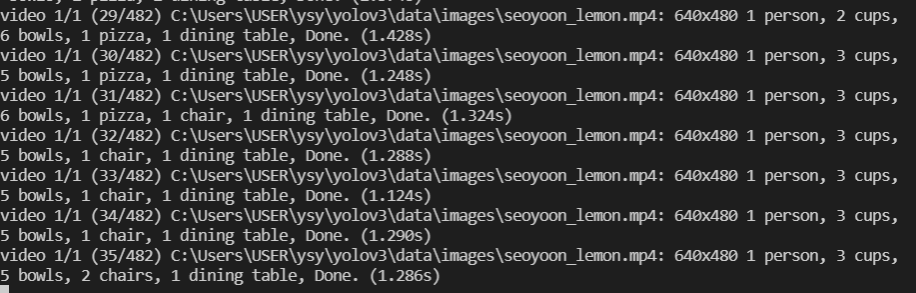
오 확실히 image보다 프레임이 많다. 20초짜리 동영상인데 1프레임당 1~2초? 걸리나보다

오 대부분의 프레임에서 빠르게 물체를 인식해내고 심지어 뒤에 숨은 의자까지도 잘 잡아내는 모습
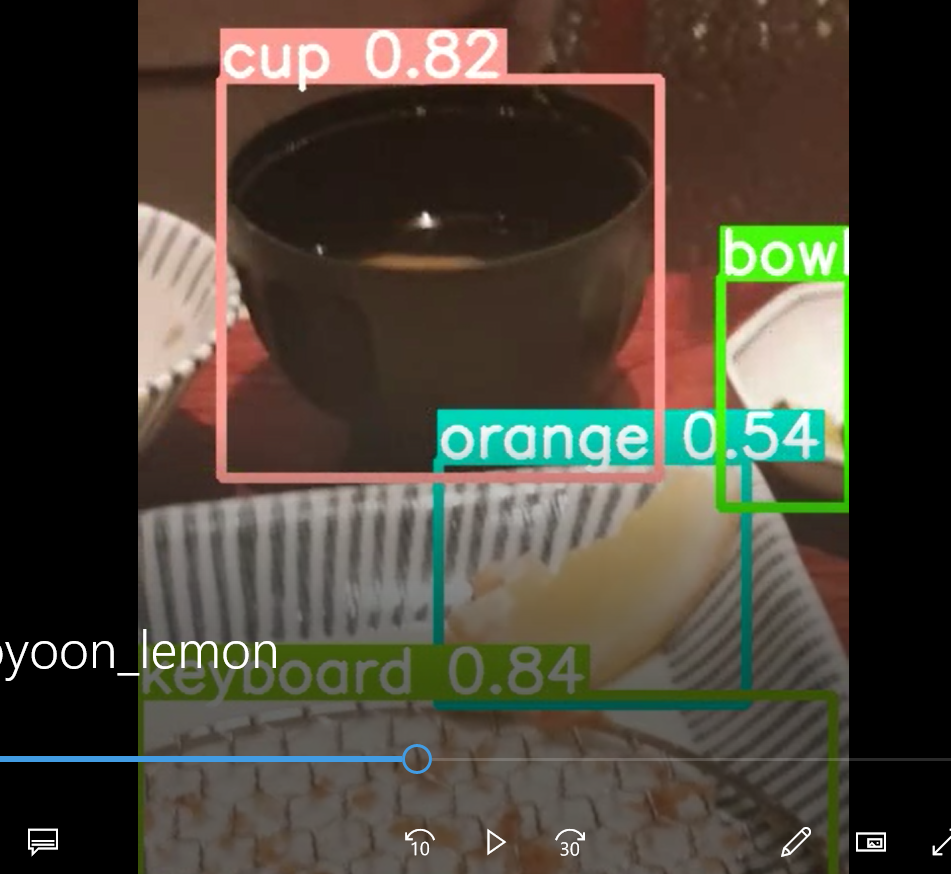
근데 막 오렌지를 pizza, knife 등으로 잡기도 한다...
--------------------------------------------------------------------------------------------------------------------------------
다운받아지는 동안 Train On Custom Data 튜토리얼을 공부하고 있자
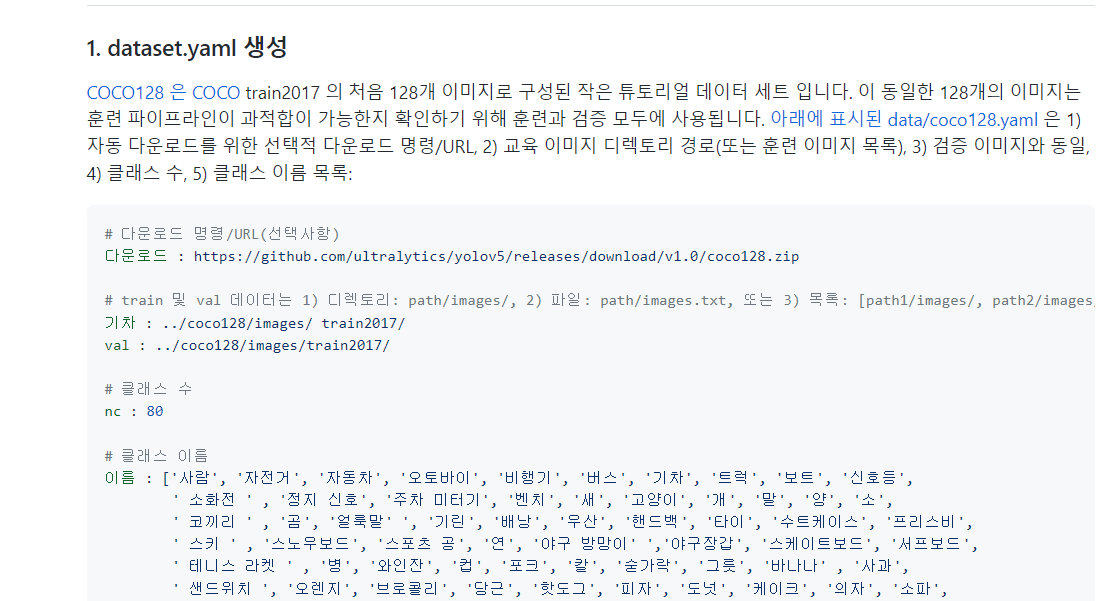



bbox정보가 들어있는 라벨링 txt 파일을 만들어야 한다. txt 파일의 이름은 그냥 이미지 이름으로 하고
다음 순서로 작성한다.
class 번호 x_center y_center w h
예를들면 , 가지볶음이 1번이라고 하면
1 0.4919 0.6383 0.3232 0.8282
이런식으로 적으면 된다. 저 0~1사이 소수점은 bbox 의 위치를 백분율로 나타낸 듯 하므로
해당위치좌표/전체 PIL Image의 shape픽셀 로 하면 될 것 같다.

그 다음 경로를 수정한다. 내가 가지고 있는 Custom Dataset을 image폴더와 label폴더로 잘 나누고, training / test / validation 8:1:1 로도 나눠봐야할 것 같다.



일단 우리팀이 구축한 데이터셋은 다음과 같은 구조이다.
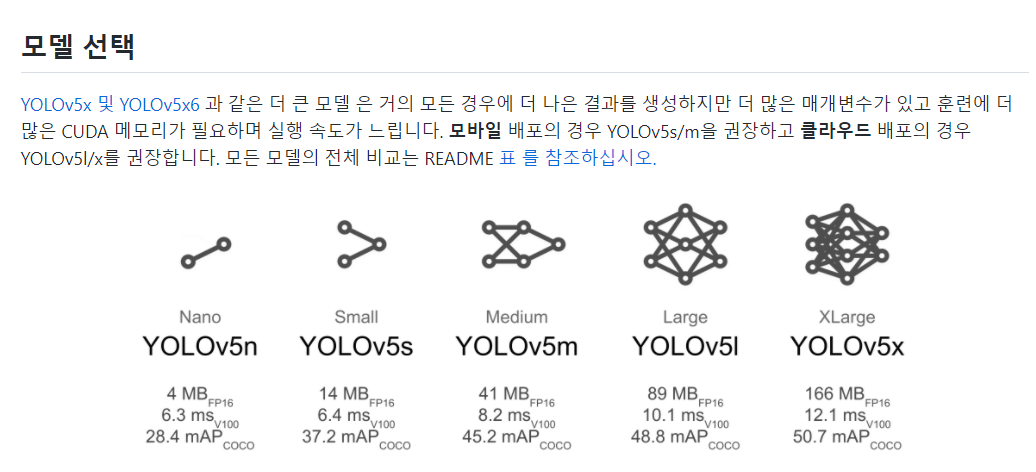
데이터셋을 잘 마련했으면 Model을 고른다. 같은 YOLO 더라도 v3, tiny, v5 등 여러 종류가 있다.
trade off에 맞게 자신이 원하는 모델을 선정하면 된다.

모델을 선정했으면 이제 training을 시키면 된다. --weights옵션으로 해당되는 pretrained 모델 weight(.pt 파일)
그다음 데이터셋 옵션인 --data 뒤에 해당 데이터셋을 넣어주면 된다.

training 결과는 runs/train이라는 폴더에 저장된다.
코드로는 이렇게 하면 된다고 한다. 예를들어 --data로는 coco128.yaml 사용, --weights로는 yolov3.pt 또는 ''로 줘서 아무 weight를 사용한다 치면
(아래는 tutorial.ipynb파일을 참고함)

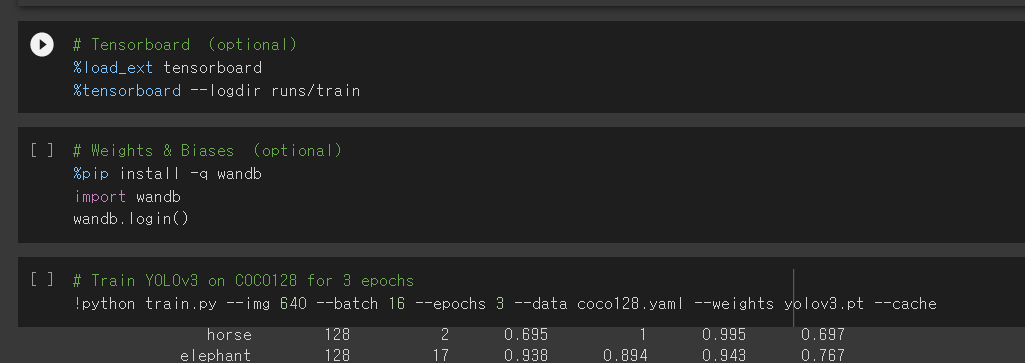
--img , --batch , --epochs, --data , --weights 를 옵션으로 원하는 값으로 준다.
그리고 저기 wandb라는 건 코치님께서 설명해주신 휴대폰으로 현재 trainining 현황이 어떻게 되고 있는지 확인할 수 있는 시각화툴인것 같다.

이런식으로 학습이 진행된다. wandb라는 것은 pip install wandb로 하면 되고, 웹으로 들어가서 training이 진행되는 동안 그 결과들을 확인할 수 있다고 한다.

wandb는 코치님이랑 더 보도록 하고, 일단 그럼 training이 완료되면 어떤 log들이 남느냐
학습이 완료되고 나서 runs/train 폴더에 들어가면 모든 결과들이 있다고 한다. 그리고 나중에 새로운 train을 하면 runs/train/exp2, exp3 이런식으로 생긴다고 함. 이 폴더에 들어가면 train과 val 이미지들을 볼 수 있?다고 한다.

----------------------------------------------------------------------------------------------------------------------------------
아래는 더 나은 정확도를 위한 팁들이다
- 데이터셋

- 모델 선택
- Pretrained(크지않은 데이터셋) vs Scratch(대용량)
