2022. 1. 23. 14:09ㆍ카테고리 없음
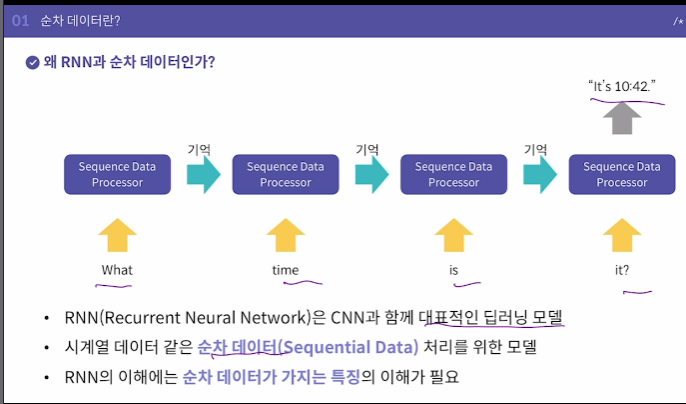
RNN (딥러닝)
시계열데이터 같은 순차데이터(What time is it )을 처리하기 위한 모델
순차데이터
순서를 가지고 나타나는 데이터(DNA 염기서열, 세계기온변화(시간순), 샘플링된 소리신호)
데이터 내 각 개체 간의 순서가 중요하다
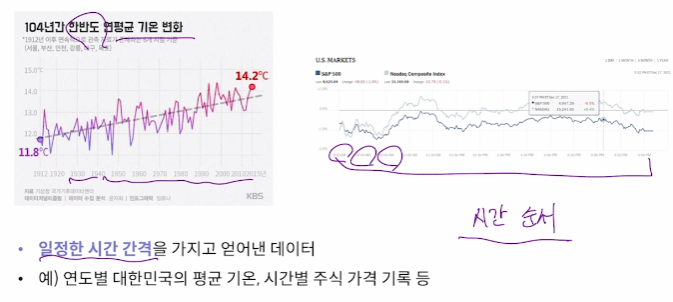
1. 시계열 데이터(Time Series Data)
일정한 시간 간격을 가지고 얻어낸 데이터
2. 자연어 데이터(Natural Language)
인류가 말하는 언어를 의미
주로 문장 내에서 단어가 등장하는 순서에 주목

딥러닝으로 순차데이터를 처리하면 어떤 일을 할 수 있을까?
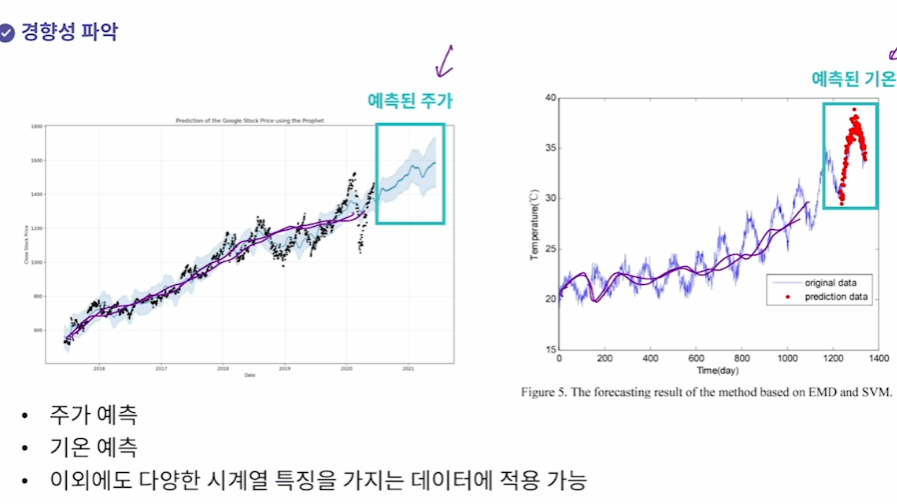
1. 경향성 파악(주가 예측, 지구온난화)
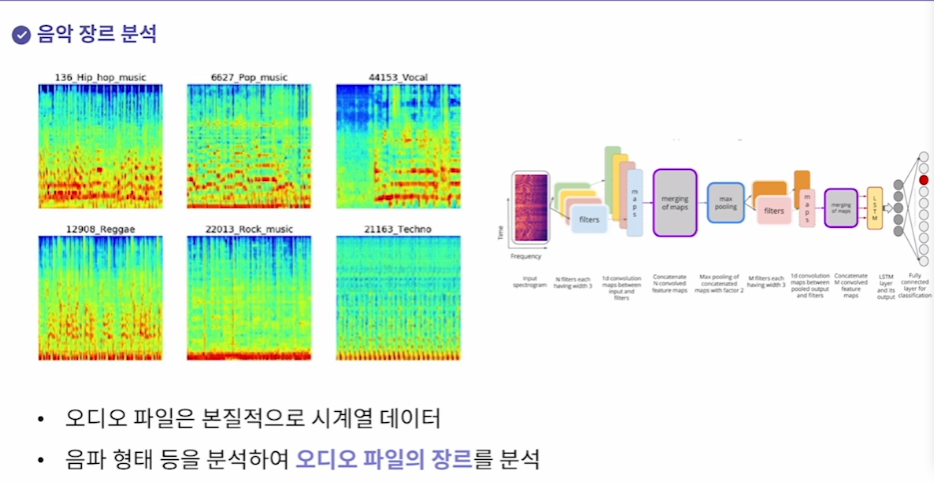
2. 음악 장르 분석
오디오 파일의 음파형태를 분석해서 오디오 파일의 장르를 분석
RNN(Recurrent Neural Network)
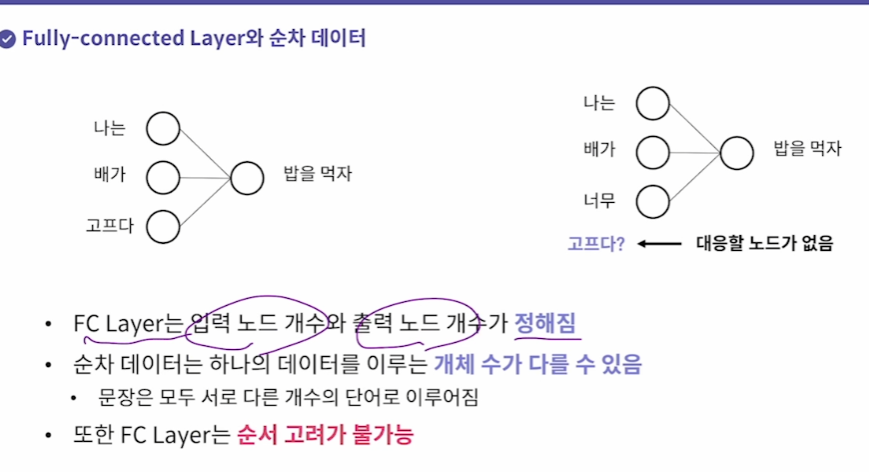
순차데이터에서도 FC보다 다른 유형이 더 적합하다
RNN은 Hidden State라는 순환구조를 가지고 있다.


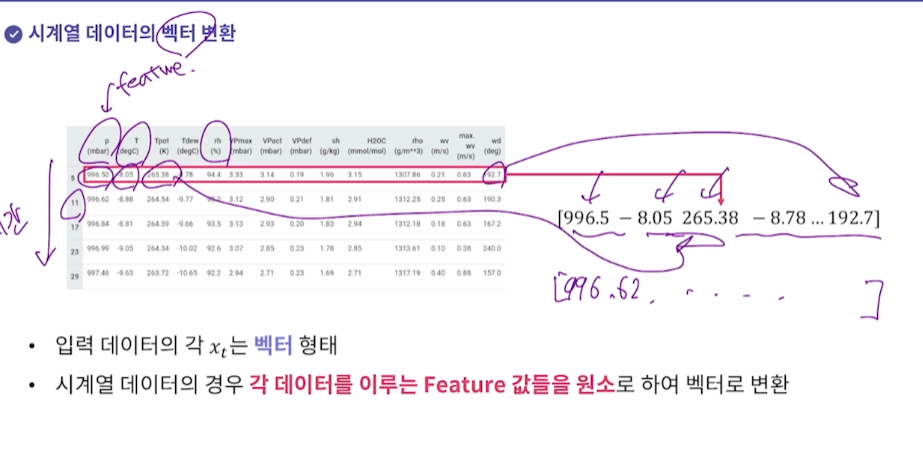
시계열 : 각 데이터를 이루는 feature값을 벡터로 변환
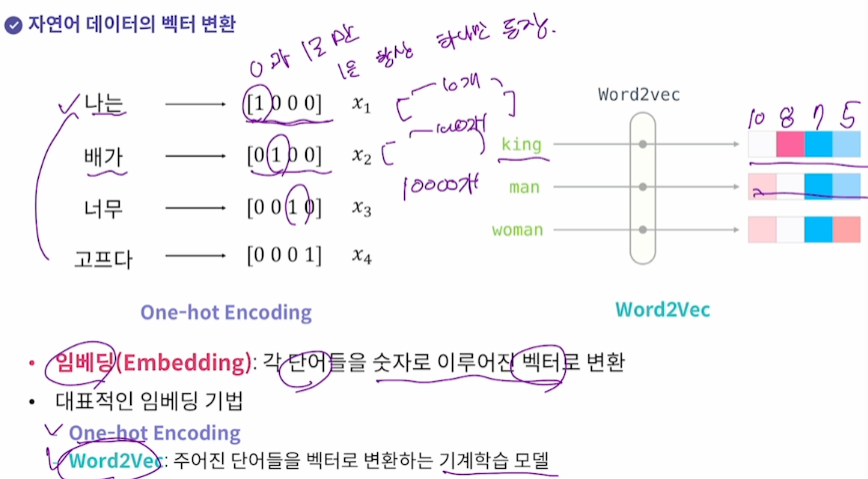
자연어 : 임베딩(one hot encoding=1이 하나만 등장한다 등)으로 각 단어를 숫자로 이루어진 벡터로 변환
단점.. 단어가 많으면 01000000길이가 매우 길어져야 할 것. 단어 개수에 따라 -> One Hot Encoding은 잘 안씀
-> Word2Vec을 사용함. 스탠포드대학에서 만듦. 주어진 단어들을 벡터로 변환하는
Vanilla RNN : 가장 간단한 RNN 모델
세 개의 FC Layer로 구성
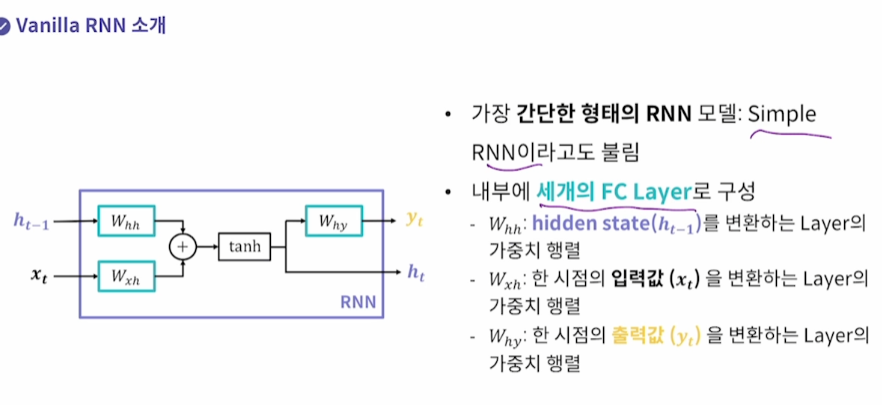
hidden, 입력, 출력
1. 현재 입력값에 대한 새로운 hidden state 계싼
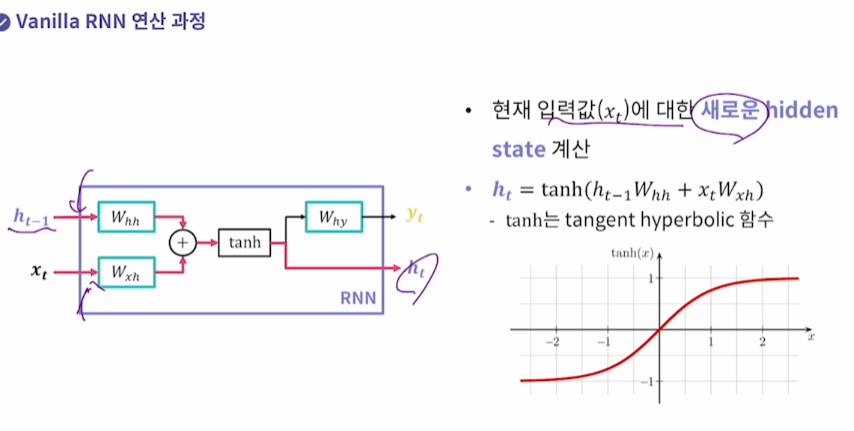
2. 현재 입력값에 대한 새로운 출력값 계산
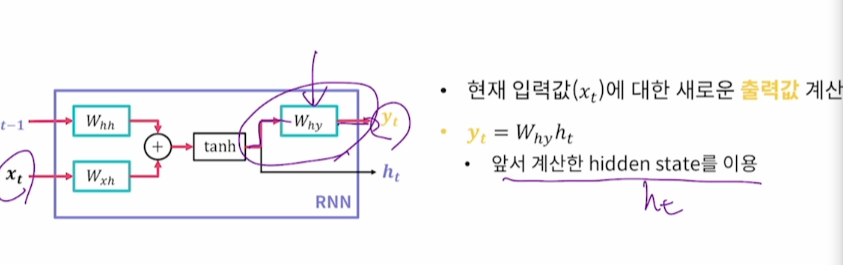

이전 시점에 생성된 hidden state를 다음 시점에 사용하는 Recurrent 한 구조이다.
저 RNN 들은 모두 똑같은 애를 쓴다
RNN의 의의
1. Hidden state의 의미 : 일종의 메모리
2. Parameter Sharing의 의미 : 재사용

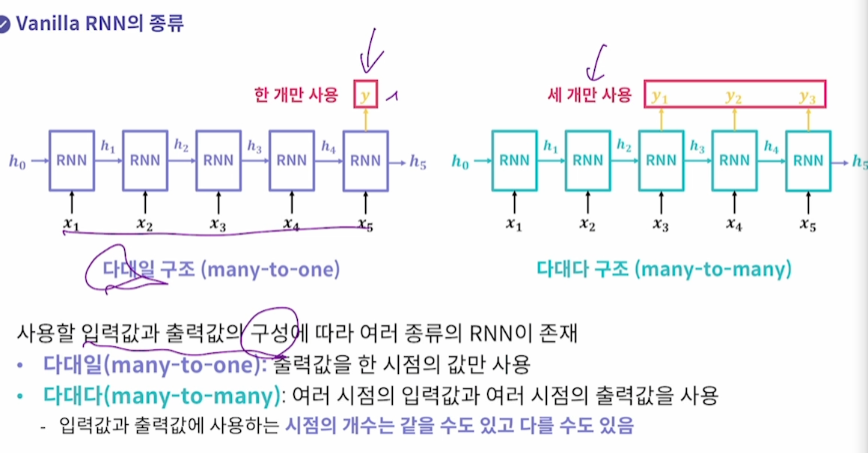
다대일, 다대다 Vanilla RNN
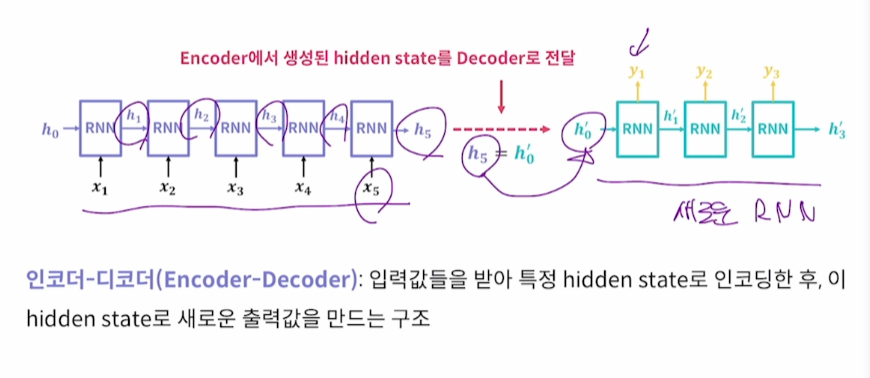
Encoder, Decoder Vanilla RNN
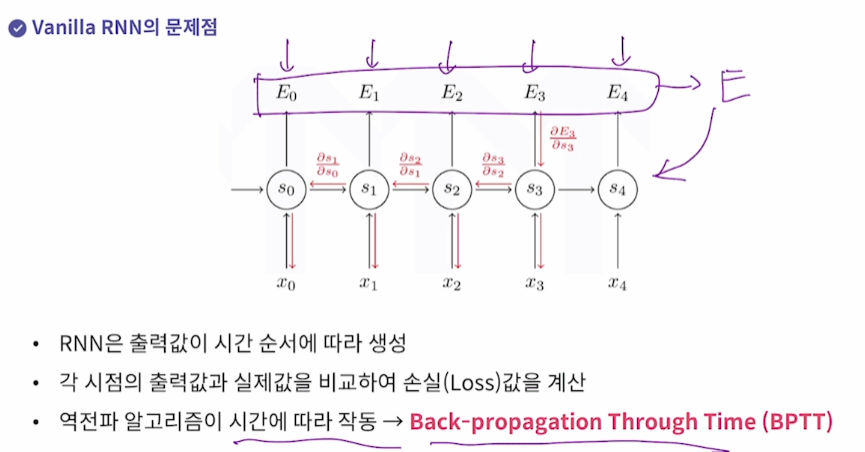
Vanilla RNN 의 문제점
Back propagation이 시간에 따라 작동하기 때문에 생긴다
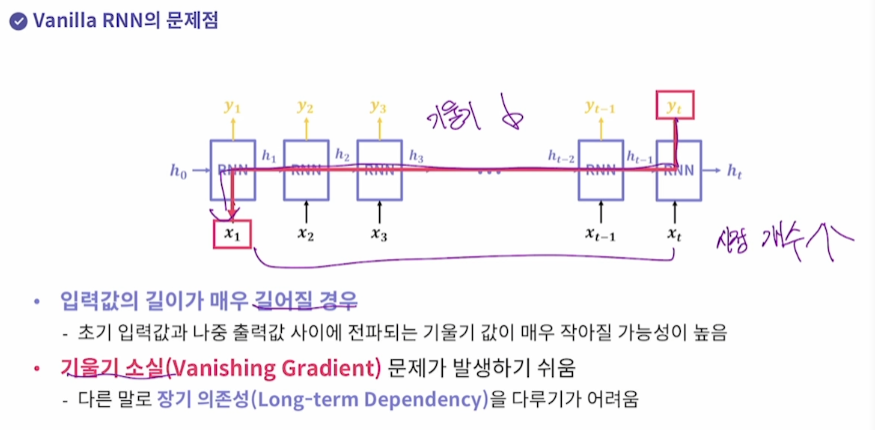
시점이 많아지면(입력값의 길이가 많아지면) 기울기 소실 문제가 발생
x2랑 xt-1이 멀다면(문장이 긴데, 첫 단어가 마지막 단어에 영향을 주는 장기 의존성)
기울기가 소실되면 이런 의존성을 알아내기가 힘들다.
One hot encoding
tensorflow.python.keras.preprocessing.text에서 Tokenizer라는 함수를 import한다
tokenizer = Tokenizer()
tokenizer.fit_on_texts(텍스트)
tokenizer.texts_to_sequences([텍스트])[0]
tokenizer.word_index
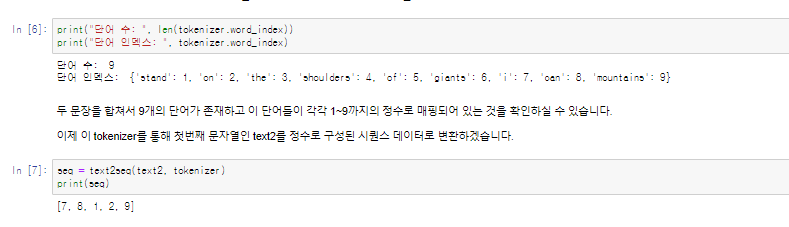
실습1
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
# TODO: [지시사항 1번] 첫번째 모델을 완성하세요.
def build_model1():
model = Sequential()
model.add(layers.Embedding(10, 5)) #전체단어개수, 벡터길이
model.add(layers.SimpleRNN(3))
return model
# TODO: [지시사항 2번] 두번째 모델을 완성하세요.
def build_model2():
model = Sequential()
model.add(layers.Embedding(256,100))
model.add(layers.SimpleRNN(20))
model.add(layers.Dense(10, activation='softmax')) #분류기
return model
def main():
model1 = build_model1()
print("=" * 20, "첫번째 모델", "=" * 20)
model1.summary()
print()
model2 = build_model2()
print("=" * 20, "두번째 모델", "=" * 20)
model2.summary()
if __name__ == "__main__":
main()
실습2

import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
def load_data(num_words, max_len):
# imdb 데이터셋을 불러옵니다. 데이터셋에서 단어는 num_words 개를 가져옵니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=num_words)
# 단어 개수가 다른 문장들을 Padding을 추가하여
# 단어가 가장 많은 문장의 단어 개수로 통일합니다.
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
return X_train, X_test, y_train, y_test
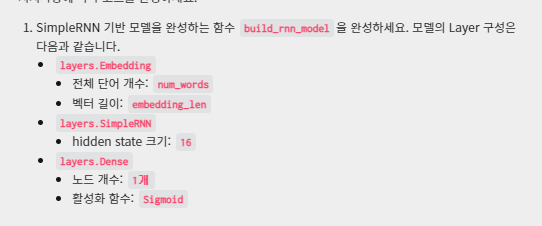
def build_rnn_model(num_words, embedding_len):
model = Sequential()
# TODO: [지시사항 1번] 지시사항에 따라 모델을 완성하세요.
model.add(layers.Embedding(num_words, embedding_len))
model.add(layers.SimpleRNN(16))
model.add(layers.Dense(1, activation='sigmoid'))
return model
def main(model=None, epochs=5):
# IMDb 데이터셋에서 가져올 단어의 개수
num_words = 6000
# 각 문장이 가질 수 있는 최대 단어 개수
max_len = 130
# 임베딩 된 벡터의 길이
embedding_len = 100
# IMDb 데이터셋을 불러옵니다.
X_train, X_test, y_train, y_test = load_data(num_words, max_len)
if model is None:
model = build_rnn_model(num_words, embedding_len)
# TODO: [지시사항 2번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# TODO: [지시사항 3번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=100, validation_split=0.2, shuffle=True, verbose=2)
# 모델을 테스트 데이터셋으로 테스트합니다.
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 Loss: {:.5f}, 테스트 정확도: {:.3f}%".format(test_loss, test_acc * 100))
return optimizer, hist
if __name__=="__main__":
main()
실습3
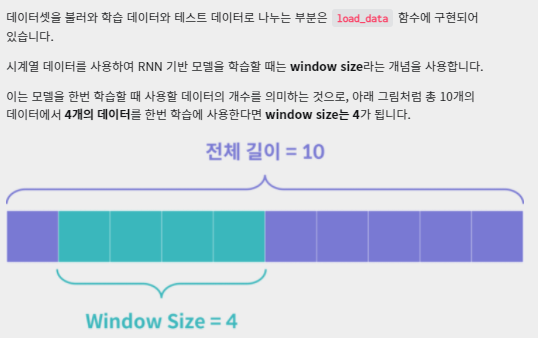
window size 모델을 한번 학습할 때 사용할 데이터 개수

from elice_utils import EliceUtils
elice_utils = EliceUtils()
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def load_data(window_size):
raw_data = pd.read_csv("./airline-passengers.csv")
raw_passengers = raw_data["Passengers"].to_numpy()
# 데이터의 평균과 표준편차 값으로 정규화(표준화) 합니다.
mean_passenger = raw_passengers.mean()
stdv_passenger = raw_passengers.std(ddof=0)
raw_passengers = (raw_passengers - mean_passenger) / stdv_passenger
data_stat = {"month": raw_data["Month"], "mean": mean_passenger, "stdv": stdv_passenger}
# window_size 개의 데이터를 불러와 입력 데이터(X)로 설정하고
# window_size보다 한 시점 뒤의 데이터를 예측할 대상(y)으로 설정하여
# 데이터셋을 구성합니다.
X, y = [], []
for i in range(len(raw_passengers) - window_size):
cur_passenger = raw_passengers[i:i + window_size]
target = raw_passengers[i + window_size]
X.append(list(cur_passenger))
y.append(target)
# X와 y를 numpy array로 변환합니다.
X = np.array(X)
y = np.array(y)
# 각 입력 데이터는 sequence 길이가 window_size이고, featuer 개수는 1개가 되도록
# 마지막에 새로운 차원을 추가합니다.
# 즉, (전체 데이터 개수, window_size) -> (전체 데이터 개수, window_size, 1)이 되도록 변환합니다.
X = X[:, :, np.newaxis]
# 학습 데이터는 전체 데이터의 80%, 테스트 데이터는 20%로 설정합니다.
total_len = len(X)
train_len = int(total_len * 0.8)
X_train, y_train = X[:train_len], y[:train_len]
X_test, y_test = X[train_len:], y[train_len:]
return X_train, X_test, y_train, y_test, data_stat
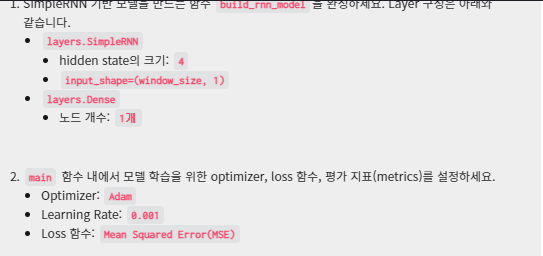
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(4, input_shape=(window_size,1)))
model.add(layers.Dense(1))
return model
def plot_result(X_true, y_true, y_pred, data_stat):
# 표준화된 결과를 다시 원래 값으로 변환합니다.
y_true_orig = (y_true * data_stat["stdv"]) + data_stat["mean"]
y_pred_orig = (y_pred * data_stat["stdv"]) + data_stat["mean"]
# 테스트 데이터에서 사용한 날짜들만 가져옵니다.
test_month = data_stat["month"][-len(y_true):]
# 모델의 예측값을 실제값과 함께 그래프로 그립니다.
fig = plt.figure(figsize=(8, 6))
ax = plt.gca()
ax.plot(y_true_orig, color="b", label="True")
ax.plot(y_pred_orig, color="r", label="Prediction")
ax.set_xticks(list(range(len(test_month))))
ax.set_xticklabels(test_month, rotation=45)
ax.set_title("RNN Result")
ax.legend(loc="upper left")
plt.savefig("airline_rnn.png")
elice_utils.send_image("airline_rnn.png")
def main(model=None, epochs=10):
tf.random.set_seed(2022)
window_size = 4
X_train, X_test, y_train, y_test, data_stat = load_data(window_size)
if model is None:
model = build_rnn_model(window_size)
# TODO: [지시사항 2번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 3번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, batch_size=8, epochs=epochs, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print()
print("테스트 MSE: {:.5f}".format(test_loss))
print()
# 모델의 예측값과 실제값을 그래프로 그립니다.
y_pred = model.predict(X_test)
plot_result(X_test, y_test, y_pred, data_stat)
return optimizer, hist
if __name__ == "__main__":
main()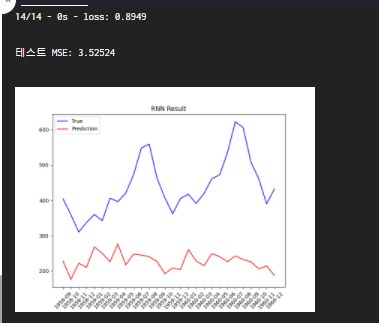
실습4 심층 Vanilla RNN



import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.keras import layers, Sequential
from tensorflow.keras.optimizers import Adam
import numpy as np
def load_data(num_data, window_size):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, num_data, 1)
time = np.linspace(0, 1, window_size)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10))
series += 0.1 * np.sin((time - offsets2) * (freq2 * 10 + 10))
series += 0.1 * (np.random.rand(num_data, window_size) - 0.5)
num_train = int(num_data * 0.8)
X_train, y_train = series[:num_train, :window_size], series[:num_train, -1]
X_test, y_test = series[num_train:, :window_size], series[num_train:, -1]
X_train = X_train[:, :, np.newaxis]
X_test = X_test[:, :, np.newaxis]
return X_train, X_test, y_train, y_test
def build_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 1번] SimpleRNN 기반 모델을 구성하세요.
model.add(layers.SimpleRNN(20, input_shape=(window_size, 1)))
model.add(layers.Dense(1))
return model
def build_deep_rnn_model(window_size):
model = Sequential()
# TODO: [지시사항 2번] 여러개의 SimpleRNN을 가지는 모델을 구성하세요.
model.add(layers.SimpleRNN(20, return_sequences=True, input_shape=(window_size,1)))
model.add(layers.SimpleRNN(20))
model.add(layers.Dense(1))
return model
def run_model(model, X_train, X_test, y_train, y_test, epochs=20, name=None):
# TODO: [지시사항 3번] 모델 학습을 위한 optimizer와 loss 함수를 설정하세요.
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='mse')
# TODO: [지시사항 4번] 모델 학습을 위한 hyperparameter를 설정하세요.
hist = model.fit(X_train, y_train, epochs=epochs, batch_size=256, shuffle=True, verbose=2)
# 테스트 데이터셋으로 모델을 테스트합니다.
test_loss = model.evaluate(X_test, y_test, verbose=0)
print("[{}] 테스트 MSE: {:.5f}".format(name, test_loss))
print()
return optimizer, hist
def main():
tf.random.set_seed(2022)
np.random.seed(2022)
window_size = 50
X_train, X_test, y_train, y_test = load_data(10000, window_size)
rnn_model = build_rnn_model(window_size)
run_model(rnn_model, X_train, X_test, y_train, y_test, name="RNN")
deep_rnn_model = build_deep_rnn_model(window_size)
run_model(deep_rnn_model, X_train, X_test, y_train, y_test, name="Deep RNN")
if __name__ == "__main__":
main()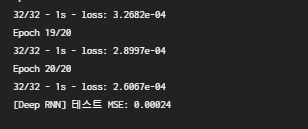
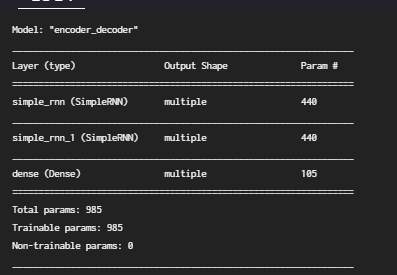
실습5 Encoder Decoder
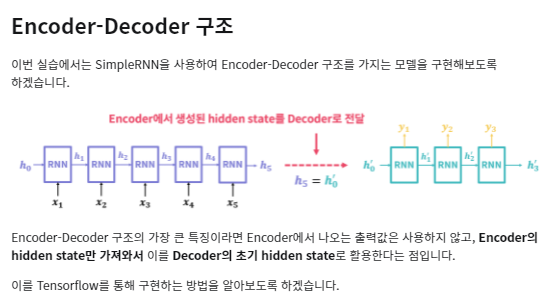
인코더의 h를 디코더의 h로 사용
return_sequence가 False면 마지막시점 출력값만 사용
return_sequence가 True면 다섯개 시점 출력값 모두 사용
return_state 는 hidden state를 활용하기 위한 변수 default는 false
return_state를 True로 하면 encoder_output, encoder_state 두 가지를 사용할 수있게 된다
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras import layers, Sequential, Input
class EncoderDecoder(Model):
def __init__(self, hidden_dim, encoder_input_shape, decoder_input_shape, num_classes):
super(EncoderDecoder, self).__init__()
# TODO: [지시사항 1번] SimpleRNN으로 이루어진 Encoder를 정의하세요.
self.encoder = layers.SimpleRNN(hidden_dim, return_state=True, input_shape=encoder_input_shape)
# TODO: [지시사항 2번] SimpleRNN으로 이루어진 Decoder를 정의하세요.
self.decoder = layers.SimpleRNN(hidden_dim, return_sequences=True, input_shape=decoder_input_shape)
self.dense = layers.Dense(num_classes, activation="softmax")
def call(self, encoder_inputs, decoder_inputs):
# TODO: [지시사항 3번] Encoder에 입력값을 넣어 Decoder의 초기 state로 사용할 state를 얻어내세요.
encoder_output, encoder_state = self.encoder(encoder_inputs)
# TODO: [지시사항 4번] Decoder에 입력값을 넣고, 초기 state는 Encoder에서 얻어낸 state로 설정하세요.
# decoder_outputs = self.decoder(decoder_inputs, initial_state=encoder_state)
decoder_outputs = self.decoder(decoder_inputs, initial_state=[encoder_state]) #여러개 쓸거면 리스트로
outputs = self.dense(decoder_outputs)
return outputs
def main():
# hidden state의 크기
hidden_dim = 20
# Encoder에 들어갈 각 데이터의 모양
encoder_input_shape = (10, 1)
# Decoder에 들어갈 각 데이터의 모양
decoder_input_shape = (30, 1)
# 분류한 클래스 개수
num_classes = 5
# Encoder-Decoder 모델을 만듭니다.
model = EncoderDecoder(hidden_dim, encoder_input_shape, decoder_input_shape, num_classes)
# 모델에 넣어줄 가상의 데이터를 생성합니다.
encoder_x, decoder_x = tf.random.uniform(shape=encoder_input_shape), tf.random.uniform(shape=decoder_input_shape)
encoder_x, decoder_x = tf.expand_dims(encoder_x, axis=0), tf.expand_dims(decoder_x, axis=0)
y = model(encoder_x, decoder_x)
# 모델의 정보를 출력합니다.
model.summary()
if __name__ == "__main__":
main()